在上一篇文章【一篇运维老司机的大数据平台监控宝典(1)】中,我们介绍了目前联通大数据监控平台由Grafana+Influxdb+Prometheus+Alertmanager等组件组成,并且着重详述了以Grafana为核心的图形化展示功能。
本文继续针对运维监控体系的另一重要内容,即告警分析、处理及发送功能进行分享。
一、为什么要选择Prometheus+Alertmanager
你的监控系统是否曾面临这些痛点:
- 告警信息推送无法分类,无法针对某部分人进行特定告警
- 重复告警或无用告警过多,重要告警易被埋没
- 监控系统无法提供可视化展示,或仅能部分展示
- 监控历史数据不能二次查询或多维度查询,故障排查缺少依据
对于业务量、平台主机量级较大的公司来说,使用以nagios+ganglia为首的传统的监控平台往往会遇到以上情况,显得力不从心。经过大量、丰富的实战工作后,我们***选择Prometheus+Alertmanager+钉钉的搭配作为联通大数据监控平台的告警分析、处理及发送工具组合。这套组合不仅能够针对以上痛点一一解决,也可以说是运维人员保障集群平台稳定运行、故障排查、问题定位的一把利器。
在下面的章节中,笔者会对系统中的Prometheus、Alertmanager等组件逐一进行介绍。
二、Prometheus-数据存储及分析
1. Prometheus简介
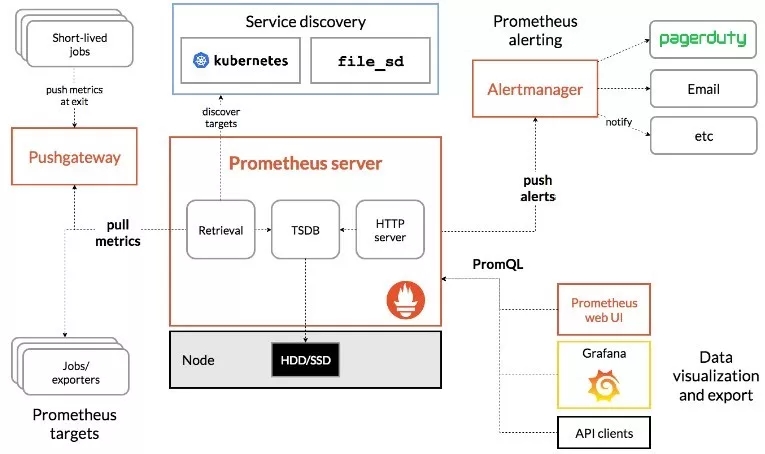
基于上图,大家可以清晰的看到,Prometheus实际上是一个tsdb型数据库,所有的采集数据以metric的形式保存在其中,且能够将数据落到本地磁盘中,供使用人员二次查询数据。
Prometheus同时附加了强大的计算与分析功能,能够利用各种labels与promql语句来完成多维度的监控数据查询,从而为故障排查与问题定位提供可靠的证据。
监控规则方面,Prometheus可以根据promql来获取数据,并且与固定阈值进行计算比较,若超出正常范围,则标记为告警信息,并且可以分组分标签定义告警描述,供后续Alertmanager使用。
在拓展性方面,Prometheus可以轻松的完成服务发现功能,并拥有每秒上万数据点的监控数据收集与分析的处理能力,完全摆脱了传统监控系统对监控主机数量的要求。目前联通大数据平台机器几千余台,监控实例过十万,监控实例指标过千万,Prometheus优良的性能可以做到***支撑。
2. Prometheus特点
(1) 监控数据存储功能及多维度查询
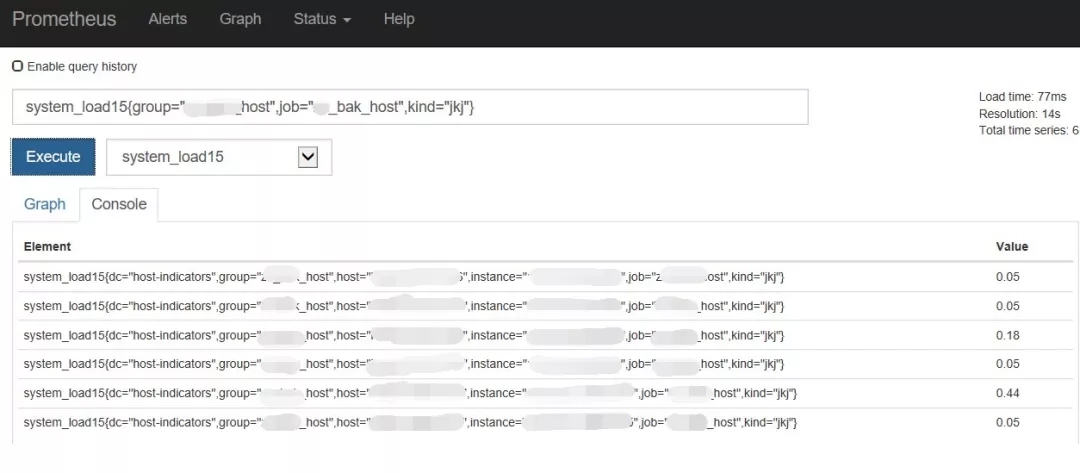
下图中以一个简单例子说明:该条查询可以看到某集群接口机15分钟内的系统负载,涉及到的标签维度为集群、主机IP、主机类型等。在实际线上环境中,还可以添加多个标签来完成查询,并且可以利用promql特有的查询语句(sum、count_values、topk等)来完成更加丰富的多维度查询,提供可靠、便捷、直观的监控数据供运维人员使用。
(2) 优秀的自定义及第三方监控拓展功能
Pushgateway是Prometheus环境中的一个data_collector。把它定义为采集者的原因很简单,标准的Prometheus会采用pull模式从target中获取监控数据,但当由于外力原因(如网络、硬件等)无法直接从target中拉取数据时,就要依靠Pushgateway了,请看下图:

大致流程为client上部署的脚本(支持多语言shell、python等)会收集target中的数据,并且以metric形式传送到Pushgateway中,只要保证client和Pushgateway能够正常通信即可。Prometheus会按照配置时间,定时到Pushgateway上拉取监控数据,从而达到收集target的目的。
下图为Pushgetway发送数据的代码过程:
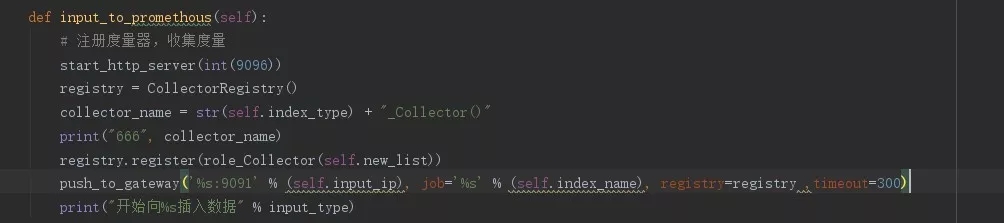
那么是否可以这么理解:对于常见组件(redis、mysql、nginx、haproxy等),我们可以依靠现有的丰富client库,直接进行监控纳管;对于一些特殊组件或自定义业务,可通过多语言脚本采集监控数据或业务埋点方式,把Pushgateway作为一个data_collector来收集各方数据,从而完成监控纳管。
(3) 良好的监控生态圈之常见client库
由于近年Prometheus的兴起,开源社区中越来越多的人将自己的代码贡献出来,使得Prometheus拥有庞大的client库(redis、mysql、nginx、haproxy等),运维人员可以利用这些client实现即开即用即监控的功能。
3. 配置
global:
scrape_interval: 15s
evaluation_interval: 15s
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['IP:9093']
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
- job_name: 'prometheus'
scrape_interval: 15s
static_configs:
- targets: ['localdns:9090']
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
三、Alertmanager-告警的分类搬运工
1. Alertmanager简介
Alertmanager在监控系统中的定位是接收Prometheus发送来的告警,并逐一按照配置中route进行分类,并且通过silencing、inhibition的规则计算,最终得到有效告警信息,通过邮件、钉钉、微信等方式发送给各类业务人群。
2. Alertmanager特点
(1) 分组
可以用一个业务场景来解释该特点:某大数据集群由于网络问题大面积瘫痪,上百个datanode触发断开告警,如果按照传统监控模式的话,收到的将是上百条的告警短信形成短信轰炸。但如果使用分组特性,Alertmanager会将具有共同属性的告警归为一条发送到接收端,清晰明了。
(2) 抑制
还是用业务场景来解释该特点:某主机上运行了一个mysql实例,若该主机宕机,则会收到多条关于mysql各项监控的告警信息,但如果配置了抑制用法,只要触发该主机的宕机告警,上面mysql所触发的告警便会被抑制掉。
(3) 沉默
举例来说,某主机硬件主板损坏,但厂商反馈要2天后才能更换主板,一般情况下在更换主板前,该警报会一直大量重复发送。如果此时利用沉默功能,在页面上配置沉默选项即可暂停此告警,待修复完成后取消沉默规则即可。
3. 配置
global:
resolve_timeout: 5m
templates:
- 'template/*.tmpl'
route:
group_by: ['cluster']
group_wait: 10s
group_interval: 20s
repeat_interval: 30m
receiver: 'host'
routes:
###############example####################
- receiver: 'example'
match:
cluster: example
continue: true
- name: 'example'
webhook_configs:
- url: 'http://localhost:8180/dingtalk/ops_dingding/send'
inhibit_rules:
- source_match:
- source_match_re:
target_match_re:
equal: ['ipAddress']
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
四、钉钉-最终告警接收查阅
运维人员常用的发送告警工具有短信、邮件、企业微信和钉钉,之所以选择钉钉的原因如下:
- 短信:一般是通过往oracle插入告警信息走短信网关发送;优点是及时高效,但缺点是oracle支持的并发量有限。
- 邮件:邮件告警的及时性是一个很大的问题,并且如果没有合理设置阈值,邮件轰炸会影响其他工作邮件的阅读。
- 企业微信:企业微信不存在短信网关的并发限制,但弊端在于告警条数有限。
- 钉钉:有强大的分组功能且不限制告警条数;可按项目创建告警群,也方便解除。
使用钉钉作为告警接收工具,简单来说就是在钉钉群聊中配置机器人,每个机器人会有一条唯一的webhook,当接收到来自Alertmanager的告警后就可以发送到手机端。本文不再详述钉钉机器人的配置,感兴趣的同学可以自行到网上查阅资料。
五、补充知识点
作为运维人员,做得最多的工作就是日常巡检、故障恢复。公司集群规模越庞大,故障发生率和故障实例数也会成倍增加,相信每个运维人都体会过节假日被临时召唤修复故障的经历。这里,笔者额外贡献一条“自动化恢复”小贴士,解放随时等待召唤的运维er,你值得拥有:
自动化简易流程:通过采集分析Prometheus里的告警数据,利用fabric或ansible等多线程安全并发远程连接工具,执行相关角色实例的恢复工作。
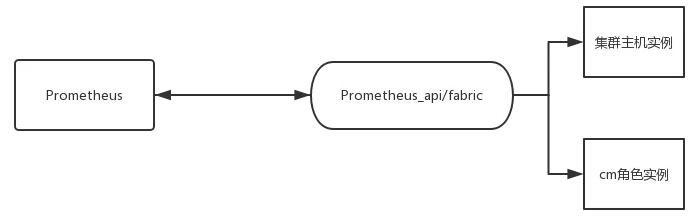
Fabric建立连接执行恢复命令。

目前自动化恢复涉及的集群日常运维操作有:
- 计算节点检测出使用swap交换分区,将会自动清理swap分区,并关闭swap分区。
- 计算节点检测出时钟偏差,将会自动纠偏时钟偏差。
- cloudera manager代理挂掉,将会自动重启。
- 主机检测出有坏盘,坏盘更换完成后,自动恢复。
- 角色实例检测出异常掉线,自动恢复上线。
- 集群存在多个节点多块磁盘存储剩余空间不足,自动进行磁盘级别的数据balancer。
- 集群存储达到阈值,自动进行节点级别的数据balancer。
需要提示的是,自动化恢复的适用场景很多,但并不适用于罕见故障且该故障有一定概率会影响到平台部分功能性能的情况,建议大家使用前严谨权衡、对症下药。
【本文是51CTO专栏机构中国联通大数据的原创文章,微信公众号“中国联通大数据( id: unibigdata)”】