












本篇文章我们将从软件系统的价值出发,首先认识架构工作的价值和目标, 接下来依次了解架构设计的基础、指导思想(设计原则)、组件拆分的方法和粒度、组件之间依赖设计、组件边界多种解耦方式以及取舍、降低组件之间通信成本的方法,从而最终指导我们做出正确的架构决策和架构设计。
一、软件系统的价值
架构是软件系统的一部分,所以要明白架构的价值,首先要明确软件系统的价值。软件系统的价值有两方面,行为价值和架构价值。
行为价值是软件的核心价值,包括需求的实现,以及可用性保障(功能性 bug 、性能、稳定性)。这几乎占据了我们90%的工作内容,支撑业务先赢是我们工程师的首要责任。如果业务是明确的、稳定的,架构的价值就可以忽略不计,但业务通常是不明确的、飞速发展的,这时架构就无比重要,因为架构的价值就是让我们的软件(Software)更软(Soft)。可以从两方面理解:
- 当需求变更时,所需的软件变更必须简单方便。
- 变更实施的难度应该和变更的范畴(scope)成等比,而与变更的具体形状(shape)无关。
当我们只关注行为价值,不关注架构价值时,会发生什么事情?这是书中记录的一个真实案例,随着版本迭代,工程师团队的规模持续增长,但总代码行数却趋于稳定,相对应的,每行代码的变更成本升高、工程师的生产效率降低。从老板的视角,就是公司的成本增长迅猛,如果营收跟不上就要开始赔钱啦。
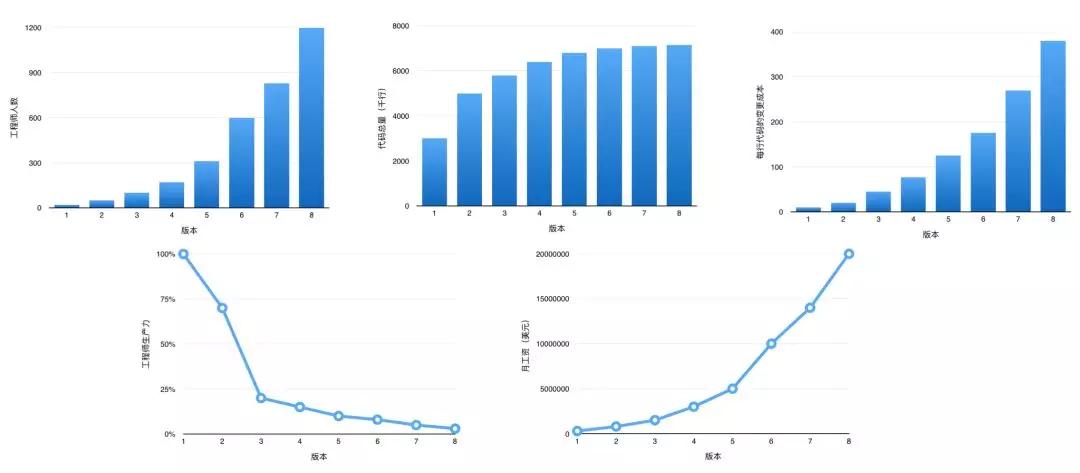
可见架构价值重要性,接下来从著名的紧急重要矩阵出发,看我们如何处理好行为价值和架构价值的关系。
重要紧急矩阵中,做事的顺序是这样的:1.重要且紧急 > 2.重要不紧急 > 3.不重要但紧急 > 4.不重要且不紧急。实现行为价值的需求通常是 PD 提出的,都比较紧急,但并不总是特别重要;架构价值的工作内容,通常是开发同学提出的,都很重要但基本不是很紧急,短期内不做也死不了。所以行为价值的事情落在1和3(重要且紧急、不重要但紧急),而架构价值落在2(重要不紧急)。我们开发同学,在低头敲代码之前,一定要把杂糅在一起的1和3分开,把我们架构工作插进去。
二、架构工作的目标
前面讲解了架构价值,追求架构价值就是架构工作的目标,说白了,就是用最少的人力成本满足构建和维护该系统的需求,再细致一些,就是支撑软件系统的全生命周期,让系统便于理解、易于修改、方便维护、轻松部署。对于生命周期里的每个环节,优秀的架构都有不同的追求:
- 开发阶段:组件不要使用大量复杂的脚手架;不同团队负责不同的组件,避免不必要的协作。
- 部署阶段:部署工作不要依赖成堆的脚本和配置文件;组件越多部署工作越繁重,而部署工作本身是没有价值的,做的越少越好,所以要减少组件数量。
- 运行阶段:架构设计要考虑到不同的吞吐量、不同的响应时长要求;架构应起到揭示系统运行的作用:用例、功能、行为设置应该都是对开发者可见的一级实体,以类、函数或模块的形式占据明显位置,命名能清晰地描述对应的功能。
- 维护阶段:减少探秘成本和风险。探秘成本是对现有软件系统的挖掘工作,确定新功能或修复问题的***位置和方式。风险是做改动时,可能衍生出新的问题。
三、编程范式
其实所谓架构就是限制,限制源码放在哪里、限制依赖、限制通信的方式,但这些限制比较上层。编程范式是最基础的限制,它限制我们的控制流和数据流:结构化编程限制了控制权的直接转移,面向对象编程限制了控制权的间接转移,函数式编程限制了赋值,相信你看到这里一定一脸懵逼,啥叫控制权的直接转移,啥叫控制权的间接转移,不要着急,后边详细讲解。
这三个编程范式最近的一个也有半个世纪的历史了,半个世纪以来没有提出新的编程范式,以后可能也不会了。因为编程范式的意义在于限制,限制了控制权转移限制了数据赋值,其他也没啥可限制的了。很有意思的是,这三个编程范式提出的时间顺序可能与大家的直觉相反,从前到后的顺序为:函数式编程(1936年)、面向对象编程(1966年)、结构化编程(1968年)。
1.结构化编程
结构化编程证明了人们可以用顺序结构、分支结构、循环结构这三种结构构造出任何程序,并限制了 goto 的使用。遵守结构化编程,工程师就可以像数学家一样对自己的程序进行推理证明,用代码将一些已证明可用的结构串联起来,只要自行证明这些额外代码是确定的,就可以推导出整个程序的正确性。
前面提到结构化编程对控制权的直接转移进行了限制,其实就是限制了 goto 语句。什么叫做控制权的直接转移?就是函数调用或者 goto 语句,代码在原来的流程里不继续执行了,转而去执行别的代码,并且你指明了执行什么代码。为什么要限制 goto 语句?因为 goto 语句的一些用法会导致某个模块无法被递归拆分成更小的、可证明的单元。而采用分解法将大型问题拆分正是结构化编程的核心价值。
其实遵守结构化编程,工程师们也无法像数学家那样证明自己的程序是正确的,只能像物理学家一样,说自己的程序暂时没被证伪(没被找到bug)。数学公式和物理公式的***区别,就是数学公式可被证明,而物理公式无法被证明,只要目前的实验数据没把它证伪,我们就认为它是正确的。程序也是一样,所有的 test case 都通过了,没发现问题,我们就认为这段程序是正确的。
2.面向对象编程
面向对象编程包括封装、继承和多态,从架构的角度,这里只关注多态。多态让我们更方便、安全地通过函数调用的方式进行组件间通信,它也是依赖反转(让依赖与控制流方向相反)的基础。
在非面向对象的编程语言中,我们如何在互相解耦的组件间实现函数调用?答案是函数指针。比如采用C语言编写的操作系统中,定义了如下的结构体来解耦具体的IO设备, IO 设备的驱动程序只需要把函数指针指到自己的实现就可以了。
struct FILE { void (*open)(char* name, int mode); void (*close)(); int (*read)(); void (*write)(char); void (*seek)(long index, int mode);}
这种通过函数指针进行组件间通信的方式非常脆弱,工程师必须严格按照约定初始化函数指针,并严格地按照约定来调用这些指针,只要一个人没有遵守约定,整个程序都会产生极其难以跟踪和消除的 Bug。所以面向对象编程限制了函数指针的使用,通过接口-实现、抽象类-继承等多态的方式来替代。
前面提到面向对象编程对控制权的间接转移进行了限制,其实就是限制了函数指针的使用。什么叫做控制权的间接转移?就是代码在原来的流程里不继续执行了,转而去执行别的代码,但具体执行了啥代码你也不知道,你只调了个函数指针或者接口。
3.函数式编程
函数式编程有很多种定义很多种特性,这里从架构的角度,只关注它的没有副作用和不修改状态。函数式编程中,函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。前面提到函数式编程对赋值进行了限制,指的就是这个特性。
在架构领域所有的竞争问题、死锁问题、并发问题都是由可变变量导致的。如果有足够大的存储量和计算量,应用程序可以用事件溯源的方式,用完全不可变的函数式编程,只通过事务记录从头计算状态,就避免了前面提到的几个问题。目前要让一个软件系统完全没有可变变量是不现实的,但是我们可以通过将需要修改状态的部分和不需要修改的部分分隔成单独的组件,在不需要修改状态的组件中使用函数式编程,提高系统的稳定性和效率。
综上,没有结构化编程,程序就无法从一块块可证伪的逻辑搭建,没有面向对象编程,跨越组件边界会是一个非常麻烦而危险的过程,而函数式编程,让组件更加高效而稳定。没有编程范式,架构设计将无从谈起。
四、设计原则
和编程范式相比,设计原则和架构的关系更加紧密,设计原则就是架构设计的指导思想,它指导我们如何将数据和函数组织成类,如何将类链接起来成为组件和程序。反向来说,架构的主要工作就是将软件拆解为组件,设计原则指导我们如何拆解、拆解的粒度、组件间依赖的方向、组件解耦的方式等。
设计原则有很多,我们进行架构设计的主导原则是 OCP(开闭原则),在类和代码的层级上有:SRP(单一职责原则)、LSP(里氏替换原则)、ISP(接口隔离原则)、DIP(依赖反转原则);在组件的层级上有:REP(复用、发布等同原则)、 CCP(共同闭包原则)、CRP(共同复用原则),处理组件依赖问题的三原则:无依赖环原则、稳定依赖原则、稳定抽象原则。
1.OCP(开闭原则)
设计良好的软件应该易于扩展,同时抗拒修改。这是我们进行架构设计的主导原则,其他的原则都为这条原则服务。
2.SRP(单一职责原则)
任何一个软件模块,都应该有且只有一个被修改的原因,“被修改的原因“指系统的用户或所有者,翻译一下就是,任何模块只对一个用户的价值负责。该原则指导我们如何拆分组件。
举个例子,CTO 和 COO 都要统计员工的工时,当前他们要求的统计方式可能是相同的,我们复用一套代码,这时 COO 说周末的工时统计要乘以二,按照这个需求修改完代码,CTO 可能就要过来骂街了。当然这是个非常浅显的例子,实际项目中也有很多代码服务于多个价值主体,这带来很大的探秘成本和修改风险。
另外当一份代码有多个所有者时,就会产生代码合并冲突的问题。
3.LSP(里氏替换原则)
当用同一接口的不同实现互相替换时,系统的行为应该保持不变。该原则指导的是接口与其实现方式。
你一定很疑惑,实现了同一个接口,他们的行为也肯定是一致的呀,还真不一定。假设认为矩形的系统行为是:面积=宽*高,让正方形实现矩形的接口,在调用 setW 和 setH 时,正方形做的其实是同一个事情,设置它的边长。这时下边的单元测试用矩形能通过,用正方形就不行,实现同样的接口,但是系统行为变了,这是违反 LSP 的经典案例。
Rectangle r = ...r.setW(5);r.setH(2);assert(r.area() == 10);
4.ISP(接口隔离原则)
不依赖任何不需要的方法、类或组件。该原则指导我们的接口设计。
当我们依赖一个接口但只用到了其中的部分方法时,其实我们已经依赖了不需要的方法或类,当这些方法或类有变更时,会引起我们类的重新编译,或者引起我们组件的重新部署,这些都是不必要的。所以我们***定义个小接口,把用到的方法拆出来。
5.DIP(依赖反转原则)
跨越组建边界的依赖方向永远与控制流的方向相反。该原则指导我们设计组件间依赖的方向。
依赖反转原则是个可操作性非常强的原则,当你要修改组件间的依赖方向时,将需要进行组件间通信的类抽象为接口,接口放在边界的哪边,依赖就指向哪边。
6.REP(复用、发布等同原则)
软件复用的最小粒度应等同于其发布的最小粒度。直白地说,就是要复用一段代码就把它抽成组件。该原则指导我们组件拆分的粒度。
7.CCP(共同闭包原则)
为了相同目的而同时修改的类,应该放在同一个组件中。CCP 原则是 SRP 原则在组件层面的描述。该原则指导我们组件拆分的粒度。
对大部分应用程序而言,可维护性的重要性远远大于可复用性,由同一个原因引起的代码修改,***在同一个组件中,如果分散在多个组件中,那么开发、提交、部署的成本都会上升。
8.CRP(共同复用原则)
不要强迫一个组件依赖它不需要的东西。CRP 原则是 ISP 原则在组件层面的描述。该原则指导我们组件拆分的粒度。
相信你一定有这种经历,集成了组件A,但组件A依赖了组件B、C。即使组件B、C 你完全用不到,也不得不集成进来。这是因为你只用到了组件A的部分能力,组件A中额外的能力带来了额外的依赖。如果遵循共同复用原则,你需要把A拆分,只保留你要用的部分。
REP、CCP、CRP 三个原则之间存在彼此竞争的关系,REP 和 CCP 是黏合性原则,它们会让组件变得更大,而 CRP 原则是排除性原则,它会让组件变小。遵守REP、CCP 而忽略 CRP ,就会依赖了太多没有用到的组件和类,而这些组件或类的变动会导致你自己的组件进行太多不必要的发布;遵守 REP 、CRP 而忽略 CCP,因为组件拆分的太细了,一个需求变更可能要改n个组件,带来的成本也是巨大的。
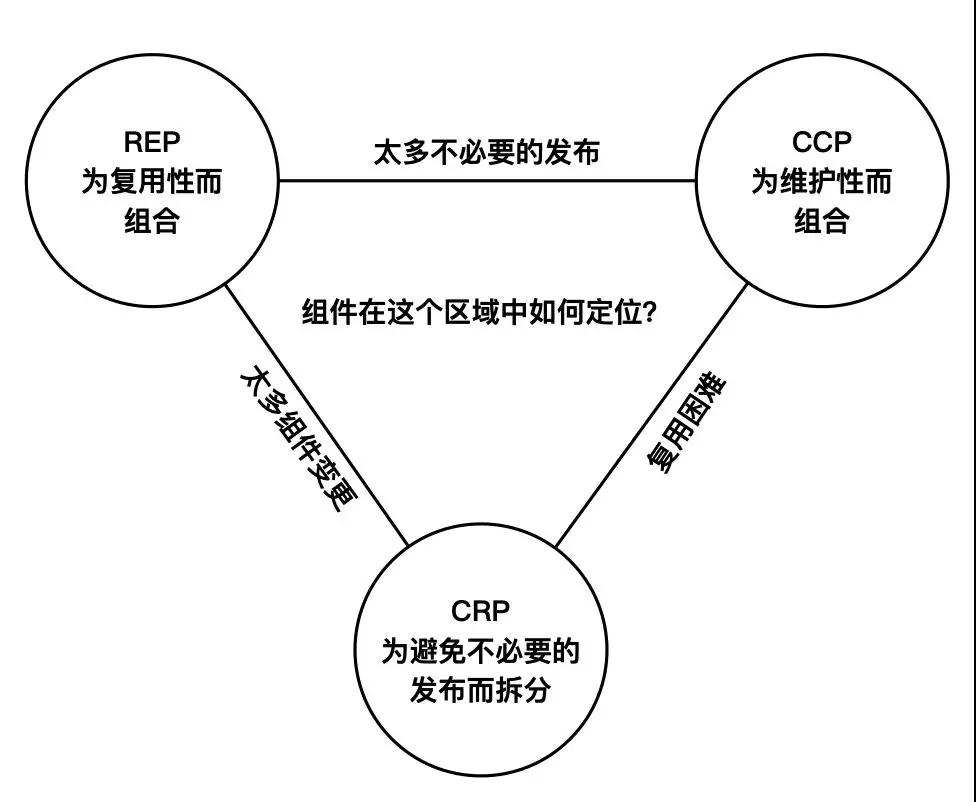
优秀的架构师应该能在上述三角形张力区域中定位一个最适合目前研发团队状态的位置,例如在项目早期,CCP比REP更重要,随着项目的发展,这个最合适的位置也要不停调整。
9.无依赖环原则
健康的依赖应该是个有向无环图(DAG),互相依赖的组件,实际上组成了一个大组件,这些组件要一起发布、一起做单元测试。我们可以通过依赖反转原则 DIP 来解除依赖环。
10.稳定依赖原则
依赖必须要指向更稳定的方向。
这里组件的稳定性指的是它的变更成本,和它变更的频繁度没有直接的关联(变更的频繁程度与需求的稳定性更加相关)。影响组件的变更成本的因素有很多,比如组件的代码量大小、复杂度、清晰度等等,最最重要的因素是依赖它的组件数量,让组件难以修改的一个最直接的办法就是让很多其他组件依赖于它!
组件稳定性的定量化衡量指标是:不稳定性(I) = 出向依赖数量 / (入向依赖数量 + 出向依赖数量)。如果发现违反稳定依赖原则的地方,解决的办法也是通过 DIP 来反转依赖。
11.稳定抽象原则
一个组件的抽象化程度应该与其稳定性保持一致。为了防止高阶架构设计和高阶策略难以修改,通常抽象出稳定的接口、抽象类为单独的组件,让具体实现的组件依赖于接口组件,这样它的稳定性就不会影响它的扩展性。
组件抽象化程度的定量化描述是:抽象程度(A)= 组件中抽象类和接口的数量 / 组件中类的数量。
将不稳定性(I)作为横轴,抽象程度(A)作为纵轴,那么最稳定、只包含抽象类和接口的组件应该位于左上角(0,1),最不稳定、只包含具体实现类,没有任何接口的组件应该位于右下角(1,0),他们连线就是主序列线,位于线上的组件,他们的稳定性和抽象程度相匹配,是设计良好的组件。位于(0,0)周围区域的组件,它们是非常稳定(注意这里的稳定指的是变更成本)并且非常具体的组件,因为他们的抽象程度低,决定了他们经常改动的命运,但是又有许多其他组件依赖他们,改起来非常痛苦,所以这个区域叫做痛苦区。右上角区域的组件,没有其他组件依赖他们,他们自身的抽象程度又很高,很有可能是陈年的老代码,所以这个区域叫做无用区。
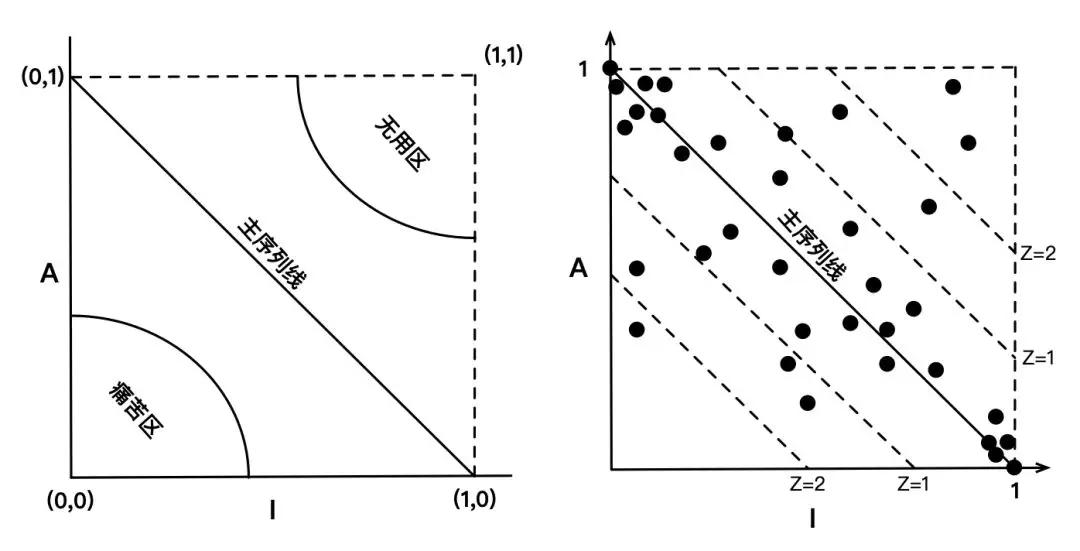
另外,可以用点距离主序列线的距离 Z 来表示组件是否遵循稳定抽象原则,Z 越大表示组件越违背稳定依赖原则。
五、架构工作的基本方针
了解了编程范式和设计原则,接下来我们看看如何应用他们拆分组件、处理组件依赖和组件边界。架构工作有两个方针:
尽可能长时间地保留尽可能多的可选项。这里的可选项指的是无关紧要的细节设计,比如具体选用哪个存储方式、哪种数据库,或者采用哪种 Web 框架。业务代码要和这些可选项解耦,数据库或者框架应该做到像插件一样切换,业务层对这个切换的过程应该做到完全无感。
低层次解耦方式能解决的,不要用高层次解耦方式。组件之间的解耦方式后边细讲,这里强调的是边界处理越完善,开发和部署成本越高。所以不完全边界能解决的,不要用完全边界,低层次解耦能解决的,不要用高层次解耦。
六、组件拆分
首先要给组件下个定义:组件是一组描述如何将输入转化为输出的策略语句的集合,在同一个组件中,策略的变更原因、时间、层次相同。
从定义就可以看出,组件拆分需要在两个维度进行:按层次拆分、按变更原因拆分。
这里的变更原因就是业务用例,按变更原因进行组件拆分的例子是:订单组件、聊天组件。按层次拆分,可以拆为:业务实体、用例、接口适配器、框架与驱动程序。
业务实体:关键业务数据和业务逻辑的集合,与界面无关、与存储无关、与框架无关,只有业务逻辑。
用例:特定场景下的业务逻辑,可以理解为 输入 + 业务实体 + 输出 = 用例。
接口适配器:包含整个整个MVC,以及对存储、设备、界面等的接口声明和使用。
一条策略距离系统的输入、输出越远,它的层次越高,所以业务实体是***的层,框架与驱动程序是***的层。
七、组件依赖处理
前面拆好了组件分好了层,依赖就很好处理了:依赖关系与数据流控制流脱钩,而与组件所在层次挂钩,始终从低层次指向高层次,如下图。越具体的策略处在的层级越低,越插件化。切换数据库是框架驱动层的事情,接口适配器完全无感知,切换展示器是接口适配器层面的事情,用例完全无感知,而切换用例也不会影响到业务实体。

八、组件边界处理
一个完整的组件边界包括哪些内容?首先跨越组件边界进行通信的两个类都要抽象为接口,另外需要声明专用的输入数据模型、声明专用的返回数据模型,想一想每次进行通信时都要进行的数据模型转换,就能理解维护一个组件边界的成本有多高。
除非必要,我们应该尽量使用不完全边界来降低维护组件边界的成本。不完全边界有三种方式:
省掉***一步:声明好接口,做好分割后,仍然放在一个组件中,等到时机成熟时再拆出来独立编译部署。
单向边界:正常的边际至少有两个接口,分别抽象调用方和被调用方。这里只定义一个接口,高层次组件用接口调用低层次组件,而低层次组件直接引用高层次组件的类。
门户模式:控制权的间接转移不用接口和实现去做,而是用门户类去做,用这种方式连接口都不用声明了。
除了完全边界和不完全边界的区分,边界的解耦方式也可以分为3个层次:
源码层次:做了接口、类依赖上的解耦,但是放在同一个组件中,通常放在不同的路径下。和不完全边界的省略***一步一样。
部署层次:拆分为可以独立部署的不同组件,比如 iOS 的静态库、动态库,真正运行时处于同一台物理机器上,组件之间通常通过函数调用通讯。
服务层次:运行在不同的机器上,通过 url 、网络数据包等方式进行通讯。
从上到下,(开发、部署)成本依次升高,如果低层次的解耦已经满足需要,不要进行高层次的解耦。
























