












《复仇者联盟4:终局之战》仍在热映中。在看到大结局的同时,本文将带你通过数据科普的眼光来回顾《复仇者联盟3》:看看这群世界上英雄们爱说的词汇是哪些?
这次回顾旅程将从一个新的角度出发——自然语言处理。
本文通过使用spaCy(用于处理和理解大量文本的NLPPython 开源程序库)对复联3的剧本进行分析,并研究以下几个项目:
- 整部电影中使用最频繁的前十个动词、名词、副词和形容词。
- 特定角色使用最多的动词和名词。
- 电影中提及次数排位前30位的命名实体(namedentities)。
- 台词对白的相似性,例如雷神的台词对白和灭霸台词对白的相似性。
看见代码和专业词汇就想睡?今天你可以放心了!为读者着想,本文中使用的词汇和术语都是非技术性的,所以就算是你没有接触过NLP、AI、机器学习或者诸如*insert buzzword here*之类的代码,你都能理解并掌握本文想要传达的信息哦!所以,不看代码也不会影响你对其余内容的理解。
灭霸 图片来源:Marvel
处理数据
实验中使用的数据或文本语料库(通常在NLP中称为语料库)是电影脚本。但是,在使用这些数据之前,需要做一下筛选。因为,心理描写、动作描述或者场景描写的文本,以及每句台词前的角色名(仅指示说话人,不作为文本分析的语料库)都不是本次研究的对象。所以,诸如“Thanoscrushes the Tesseract, revealing the blue Space Stone…” (灭霸捏碎了宇宙魔方,获得了蓝色的空间宝石……)之类的句子都被删除了。
此外,作为spaCy数据处理步骤的一部分,“I”(我)、“you”(你)、“an”(一个)这类被标记为停止词(常用的单词,多为冠词、介词、副词或连词)的术语被将不做处理。同时,实验过程中只使用单词的标准形式,也就是词根。举例说明,动词“talk”、“talked”和“talking”是同一个词“talk”(说话)的不同形式,所以这些词的词根就是“talk”。
要在spaCy中处理一段文本,首先需要加载语言模型,然后在文本语料库上调用模型进行文本处理。结果会输出一个涵盖所有已处理文本的Doc文件。
- importspacy
- # load a medium-sized language model
- nlp = spacy.load("en_core_web_md")
- with open('cleaned-script.txt', 'r') asfile:
- text = file.read()
- doc = nlp(text)
在spaCy中创建Doc文件
然后就可以获得一个经过处理、有效信息占比极高的语料库。紧接着就可以开始实验了!
整部电影中使用最频繁的前十个动词、名词、副词和形容词
是否可能仅通过了解出现最频繁的动词就推断出电影的整体走向和情节呢?下文的图表证明了这一观点。
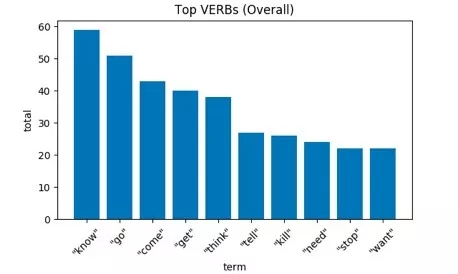
“I know” (我了解……)、“you think” (你觉得……)是最常见的短语。
“know” (了解)、“go” (去)、 “come”(来)、“get” (获得)、“think”(思考)、“tell” (告诉)、“kill” (谋杀)、“need” (需要)、“stop” (制止)、和“want” (想要) 。从中能够推断出什么?介于这部电影于2018年上映,相信大部分观众都已经知道它讲述了一个什么样的故事:根据这些动词推断出《复仇者联盟3》是关于了解、思考和调查如何去阻止某物或某人。
通过以下代码就能统计各个动词出现次数:
- importspacy
- #load a medium-sized language model
- nlp= spacy.load("en_core_web_md")
- withopen('cleaned-script.txt', 'r') as file:
- text = file.read()
- doc= nlp(text)
- #map with frequency count
- pos_count= {}
- fortoken in doc:
- # ignore stop words
- if token.is_stop:
- continue
- # pos should be one of these:
- # 'VERB', 'NOUN', 'ADJ' or 'ADV'
- if token.pos_ == 'VERB':
- if token.lemma_ in pos_count:
- pos_count[token.lemma_] += 1
- else:
- pos_count[token.lemma_] = 1
- print("top10 VERBs {}".format(sorted(pos_count.items(), key=lambda kv: kv[1],reverse=True)[:10]))
那么描述动词的词——副词也会有同样的实验效果吗?
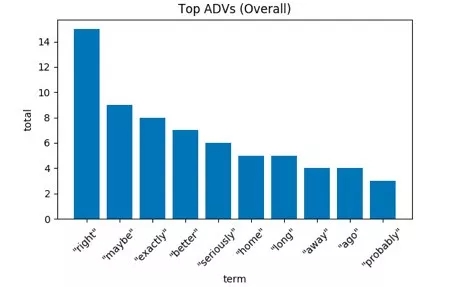
“I seriously don’t know how you fit your head into that helmet.” (我真不知道那个头盔怎么塞得进你的脑袋。)——奇异博士。
对于一部关于阻止紫薯精毁灭半个宇宙的电影来说,台词中有很多类似“right”(没错)、“exactly”(就是这样)、“better”(更好地)这种具有积极意向的副词。
所以,知道了电影中的动作和动作描述,现在是时候看看名词了。
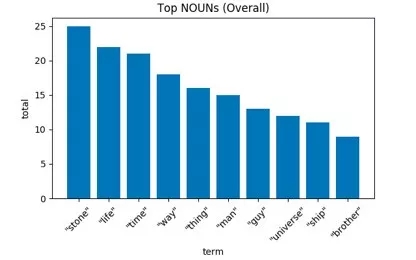
“You will pay for his life with yours.Thanos willhave that stone.” (这将是以命换命,灭霸总会得到那块宝石。)——暗夜比邻星
结果显示,“stones”(宝石)不出意料地出现次数最多,毕竟整部电影都在围绕它们发展。出现次数排第二的是灭霸想要摧毁的“life”(生命),接着是复仇者们没有多少的“time”(时间)(注意:出现次数较多也可能是因为电影中多次提到了“theTime Stone”——时间宝石)。
在进入下一个实验项目之间,探究一下形容词或描述名词的单词。与副词的情况类似,这里也有“good”(好的)和“right”(对的)等表达积极意义的词汇,以及“okay”(没问题)和“sure”(当然)等表示肯定的词汇。
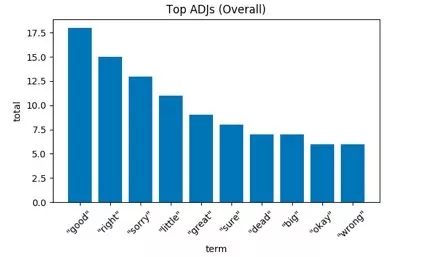
“I'm sorry, little one.” (对不起,小家伙)——灭霸
特定角色使用最多的动词和名词
前面的图片列举了电影中最常见的动词和名词。虽然这些结果让我们对电影的整体感觉和情节有了一定的了解,但它并没有过多地讲述各个角色的个人经历。因此,在特定角色的个人台词中,通过使用前面相同的程序,找到了出现次数前十的动词和名词。
由于电影中有很多角色,所以本实验中只选择了一些台词数量较多的角色。这些角色分别是钢铁侠、奇异博士、卡魔拉、雷神、火箭浣熊、星爵、乌木喉和灭霸。对不起,队长没有入选。
下图展示了这些角色使用次数最多的10个名词。
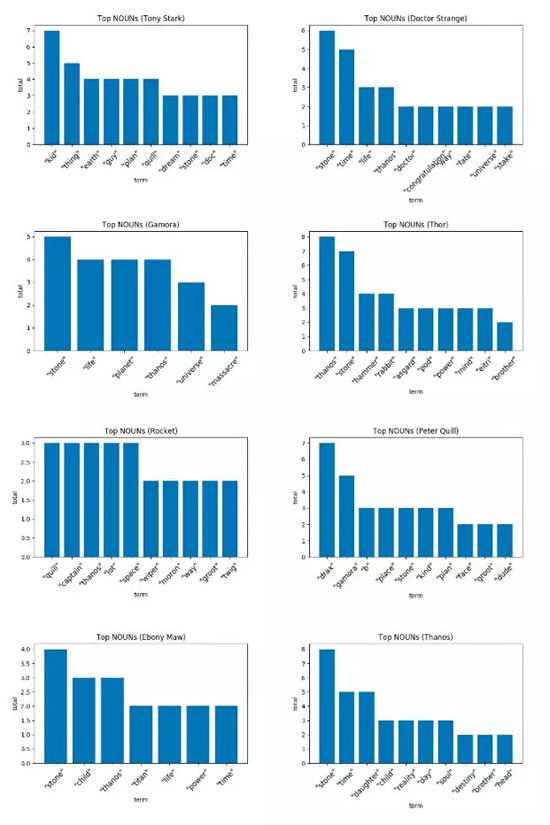
星爵到底为什么这么频繁地叫德拉克斯?
意料之外的是,大多数情况下,亲爱的英雄们最常提及的名词都是同伴的名字。例如,钢铁侠提及“孩子”(指蜘蛛侠)9次,火箭浣熊叫了奎尔(星爵)3次,而星爵叫了(其实是大吼)德拉克斯7次。
通过进一步的观察,可以推断出每个角色心中最重要的东西。拿钢铁侠的情况举例,统计数据表明“地球”对他来说十分重要。卡魔拉的情况也很相似,她总是念叨着“生命”、“宇宙”和“星球”这些涵义更广阔的实体,并为之付出了自己的生命。奇异博士反复提及他与其余英雄不甚相同的目标——保护时间宝石。还有雷神,由于他和灭霸之间的国仇家恨,他提及灭霸的名字多达8次,当然还少不了新的“干脆面”好友——长得像只“兔子”的火箭浣熊。一张图的数据表明灭霸不断念叨着要集齐所有宝石,并且多次呼唤他的女儿。
名词表达意义,但动词可能无法像名词这样鲜明地表达角色的特征。在下面的图片中你会看到,动词的表达能力相比名词的来说产生的效果甚微。像“know”(了解)、“want”(想要)和“get”(获得)这样缺乏特征性的普遍被使用的单词出现的频数都很高。然而,灭霸的头号粉丝——乌木喉可能拥有整个语料库中最独特的动词。乌木喉就像一个忠仆:除了想方设法获取时间宝石,他主要从事的工作就是用“聆听”、“感到荣幸”等词鼓吹他主子的使命。啧啧,真谄媚。
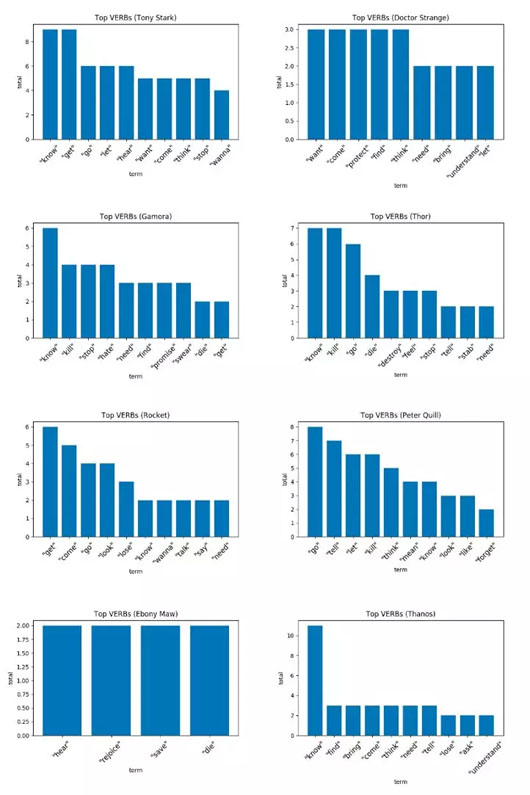
“Hear me, and rejoice. You have had the privilege of being saved by the Great Titan…”(跪下聆听并感到荣幸吧!你有幸被最伟大的救世主拯救……)——乌木喉
末尾来个彩蛋(大雾):格鲁特说得最多的是——
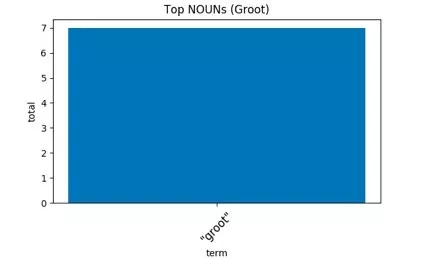
“I am Groot.”(我是格鲁特。)
命名实体
到目前为止,我们已经完成了全篇电影、各位英雄和反派最常用的动词、名词、副词和形容词的探索。然而,为了充分理解一直在研究的所有词,需要加入一些上下文,即命名实体,进行研究。
根据有关spaCy的网页说明,命名实体是“指定名称的实际对象——例如,一个人、一个国家、一个产品或一本书的标题。”所以,了解这些实体就意味着了解角色在说些什么。在spaCy程序源库中,实体都有一个预测的标签,该标签将实体分成人、产品、艺术词汇等等类型(https://spacy.io/api/annotation#named-entities),从而为后续实验提供额外的粒度级别,有助于对实体进行进一步分类。但是,为了简化过程,本次实验中将使用实体本身而不是实体分类。
这些是出现次数排名前30的实体。
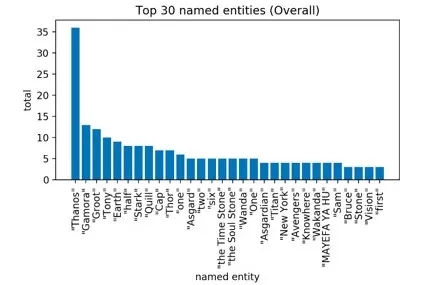
“MATEFAYA HU”(必胜)是瓦坎达贾巴里部落战士战斗前的口号。
首先,考虑到整部电影都是关于灭霸的,所以灭霸出现次数最多是情理之中。紧随其后的是他的女儿、影片的核心人物之一——卡魔拉。然后在第三位的是格鲁特(不需要解释了吧),紧随其后的是钢铁侠和其他复仇者,以及一些地点,如纽约,阿斯加德和瓦坎达(瓦坎达万岁)。除了英雄名字和地点之外,“六颗宝石”(“six Infnity Stones”)的“六”、时间宝石(the Time Stone)和灵魂宝石(theSoul Stone)分别出现在第14、15和16位。意料之外的是,将灭霸吸引到地球来的心灵宝石不在前30名之列。
可以通过以下代码读取Doc文件中各个单词的实物标签‘ents’:
- importspacy
- # load a medium-sized language model
- nlp = spacy.load("en_core_web_md")
- with open('cleaned-script.txt', 'r') as file:
- text = file.read()
- doc = nlp(text)
- # create an entity frequency map
- entities = {}
- # named entities
- for ent in doc.ents:
- #Print the entity text and its label
- ifent.text in entities:
- entities[ent.text] += 1
- else:
- entities[ent.text] = 1
- print("top entities{}".format(sorted(entities.items(),
- key=lambda kv: kv[1], reverse=True)[:30]))
台词对白间的相似性
当讨论每个角色最常用动词时,我们意识到他们使用的动词都非常相似,表达出了相同的感觉,而这与分析名词得到的结论不甚相同。像“go”(去)、“come”(来)这样的词语,营造出角色们想要去或抵达某个特定地方的感觉和趋向;而像“kill”(谋杀)和“stop”(制止)这样的动词暗示着,确实存在一个巨大的威胁必须得到阻止。
考虑到这个结果,为了继续研究相似性,实验提出计算分数衡量各个角色的台词对白的相似度。
NLP中相似度的定义为,描述两段文本的结构或句法涵义有相关性的度量——通常,相似度得分介于0到1之间,0表示完全不同,1表示完全相似(或者两段文本完全相同)。从技术上讲,相似性是通过测量单词向量(单词的多维表征)之间的距离来计算的。如果你有兴趣进一步了解单词向量的相关内容,建议搜索了解一下生成单词向量的常用算法——word2vec。下图就是各个角色台词对白的相似性矩阵。
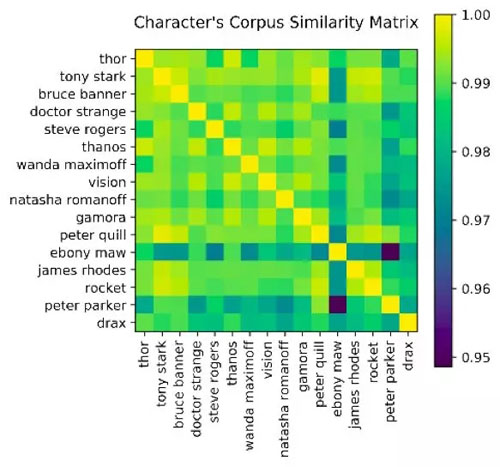
这个图再次证明,乌木喉真的是最独特的角色。
这个结果可谓是“惊不惊喜!意不意外!”了。一方面,由于这部电影只有一个主要情节,所以可以理解,对话中的关联性导致所有的角色的台词对白相似性都接近于1。然而,没想到的是,他们的分数过于太接近了。实验的研究期望是,至少灭霸与其他英雄的台词对白相似性较低。毕竟对于灭霸这样一个反派来说,其他英雄都是在一个劲的讨论着怎么阻止他啊。可喜可贺地是,蜘蛛侠的台词相似性得分变化起伏不定;毕竟,他只是个在上学路上被叫来拯救世界的小孩儿,所以有这样的结果也不奇怪。
下面代码演示了如何在spaCy环境下计算两段台词对白之间的相似性:
- # for the full example onhow I obtained all the similarities
- # see the full code at:https://github.com/juandes/infinity-war-spacy/blob/master/script.py
- import spacy
- # load a medium-sized language model
- nlp = spacy.load("en_core_web_md")
- with open('tony-script.txt', 'r') as file:
- tony_lines =file.read()
- with open('thor-script.txt', 'r') as file:
- thor_lines = file.read()
- tony_doc = nlp(tony_lines)
- thor_doc = nlp(thor_lines)
- similarity_score = tony_doc.similarity(thor_doc)
- print("Similarity between Tony's and Thor's docs is{}".format(similarity_score))
结论
在电影《复仇者联盟3》中,一群超级英雄展开了阻止灭霸消灭宇宙半数生命的旅程。在整部电影中,通过英雄们的表达方式,观众从字里行间中逐渐了解到这些英雄拯救世界的动机和动力。
在Python、NLP和spaCy的帮助下,本文通过研究各个人物的台词,探索了英雄和反派进行表达和交流的方式。通过观察他们最常用的动词、名词和语言特点,我们了解、确认并重温了钢铁侠对地球的忠诚、奇异博士保护时间宝石的誓言、雷神对复仇的渴望以及灭霸完成自己野心的坚决。















