为数据而生,以 20 世纪***影响力的作家命名,一个很酷的开源项目——我们说的是Kafka。进入出生第九个年头的 Kafka 已经算不上年轻,但依旧活力四射。这篇文章简单梳理一下 Kafka 的发展脉络,文末给出了本文的参考资料,以及一个快速实用 Kafka 的课程,参考资料和课程以供感兴趣的读者深入学习。
诞生背景
每一次科学家们发生分歧,都是因为掌握的数据不够充分。所以我们可以先就获取哪一类数据达成一致。只要获取了数据,问题也就迎刃而解了。要么我是对的,要么你是对的,要么我们都是错的。然后我们继续研究。
——Neil deGrasse Tyson
2010 年前后, 跟不少互联网公司一样,Linkedin 每天采集的数据种类多(日志消息、度量指标、用户活动记录、响应消息,等等),规模大,其中很多数据由不同数据源实时生成。数据生产者和消费者之间点对点的数据传输方式和多个独立发布与订阅系统的维护成本越来越高,由此, 把不同来源数据整合到一起集中管理的需求越来越强,公司开始研究一套高效的数据管道。随后,Kafka 从 Linkedin 内部作为一套基于发布与订阅的消息系统诞生。
关键时间节点
2010 年 10 月,Kafka 在 Linkedin 诞生
2011 年 7 月,进入 Apache 孵化器,并发布***个开源版本 0.7.0
2012 年 10 月,从孵化器毕业,成为***开源项目,同时发布 0.8.0 版本
2014 年 11 月,Confluent 成立。同年,发布 0.8.2 和 0.9.0,在 0.9.0 版本加入了配额和安全性
2017 年 11 月,1.0.0 版本正式发布,Exactly-Once 与运维性能提升
2018 年 7 月,2.0.0 版本发布,注重流式数据平台的在线可进化性
2018 年 12 月,Kafka 团队修改 KSQL 等的开源许可
简单介绍
Kafka 数据关键词
消息与键
Kafka 的数据单元称为消息,可以把消息看成数据库里的一个“数据行”或一条“记录”。消息由字节数组组成,对于 Kafka 来说,消息里的数据没有特别的格式或含义。消息可以有一个可选的元数据——键。键也是一个字节数组,没有特殊含义。为消息选取分区的时候会用到键。
消息与批次
为提高效率,消息分批次写入 Kafka。批次就是一组消息,它们属于同一个主题和分区。把消息分成批次传输可以减少网络开销。
主题与分区
Kafka 的消息通过主题进行分类。主题就好比数据库的表。主题可以被分为若干个分区,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先入先出的顺序读取。一个主题一般包含几个分区。
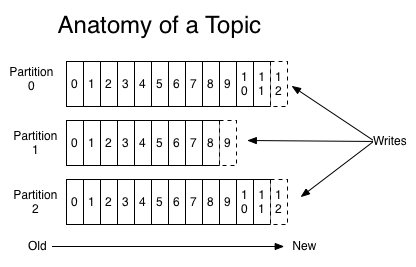
图片来自 https://kafka.apache.org
流
我们通常会使用流这个词来描述 Kafka 这类系统的数据。很多时候,人们把一个主题的数据看成一个流。流是一组从生产者移动到消费者的数据。
核心API
- Kafka Producer API:直接生成数据的应用程序(如日志、物联网)
- Kafka Connect Source API:用于数据集成的 API(如 MongoDB、REST API)
- Kafka Streams API / KSQL:用于流处理的 API,如果能够以 SQL 方式实现查询逻辑就使用 KSQL,如果需要编写复杂逻辑就用 Kafka Streams
- Kafka Consumer API:读取数据流并执行实时操作(如发送电子邮件)
- Kafka Connect Sink API :读取数据流并将其存储到目标存储中(如 Kafka 到 HDFS、Kafka 到 MongoDB 等)
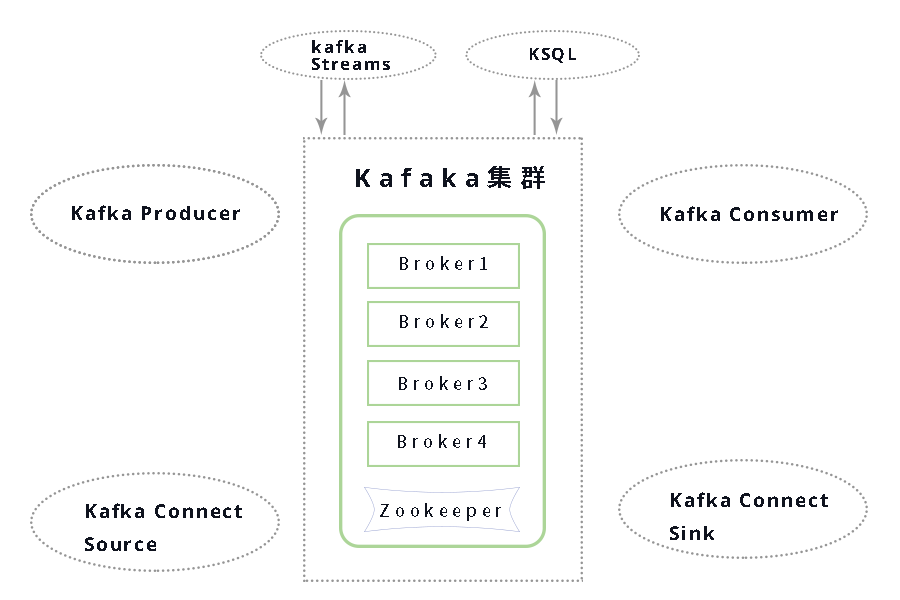
中间部分的 Kafka 集群,由多个 broker 组成。一个独立的 Kafka 服务器被称为 broker。broker 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个 broker 可以轻松处理数千个分区以及每秒***的消息量。
应用场景
活动跟踪
Kafka 最初的使用场景是跟踪用户的活动。网站用户与前端应用程序发生交互,前端应用程序生成用户活动相关的消息。这些消息可以是一些静态的信息,比如页面访问次数和点击量,也可以是一些复杂的操作,比如添加用户资料。这些消息被发布到一个或多个主题上,由后端应用程序负责读取。这样,我们就可以生成报告,为机器学习系统提供数据,更新搜索结果,或者实现其他更多的功能。
传递消息
Kafka 的另一个基本用途是传递消息。应用程序向用户发送通知(比如邮件)就是通过传递消息来实现的。这些应用程序组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何被发送的。一个公共应用程序会读取这些消息,对它们进行处理:
- 格式化消息(也就是所谓的装饰);
- 将多个消息放在同一个通知里发送;
- 根据用户配置的***项来发送数据。
使用公共组件的好处在于,不需要在多个应用程序上开发重复的功能,而且可以在公共组件上做一些有趣的转换,比如把多个消息聚合成一个单独的通知,而这些工作是无法在其他地方完成的。
度量指标和日志记录
Kafka 也可以用于收集应用程序和系统度量指标以及日志。Kafka 支持多个生产者的特性在这个时候就可以派上用场。应用程序定期把度量指标发布到 Kafka 主题上,监控系统或告警系统读取这些消息。Kafka 也可以用在像 Hadoop 这样的离线系统上,进行较长时间片段的数据分析,比如年度增长走势预测。日志消息也可以被发布到 Kafka 主题上,然后被路由到专门的日志搜索系统(比如 Elasticsearch)或安全分析应用程序。更改目标系统(比如日志存储系统)不会影响到前端应用或聚合方法,这是 Kafka 的另一个优点。
提交日志
Kafka 的基本概念来源于提交日志,所以使用 Kafka 作为提交日志是件顺理成章的事。我们可以把数据库的更新发布到 Kafka 上,应用程序通过监控事件流来接收数据库的实时更新。这种变更日志流也可以用于把数据库的更新复制到远程系统上,或者合并多个应用程序的更新到一个单独的数据库视图上。数据持久化为变更日志提供了缓冲区,也就是说,如果消费者应用程序发生故障,可以通过重放这些日志来恢复系统状态。另外,紧凑型日志主题只为每个键保留一个变更数据,所以可以长时间使用,不需要担心消息过期问题。
流处理
流处理是又一个能提供多种类型应用程序的领域。可以说,它们提供的功能与 Hadoop 里的 map 和 reduce 有点类似,只不过它们操作的是实时数据流,而 Hadoop 则处理更长时间片段的数据,可能是几个小时或者几天,Hadoop 会对这些数据进行批处理。通过使用流式处理框架,用户可以编写小型应用程序来操作 Kafka 消息,比如计算度量指标,为其他应用程序有效地处理消息分区,或者对来自多个数据源的消息进行转换。
为什么选择 Kafka
基于发布与订阅的消息系统那么多,为什么 Kafka 会是一个更好的选择呢?
多个生产者
Kafka 可以无缝地支持多个生产者,不管客户端在使用单个主题还是多个主题。所以它很适合用来从多个前端系统收集数据,并以统一的格式对外提供数据。例如,一个包含了多个微服务的网站,可以为页面视图创建一个单独的主题,所有服务都以相同的消息格式向该主题写入数据。消费者应用程序会获得统一的页面视图,而无需协调来自不同生产者的数据流。
多个消费者
除了支持多个生产者外,Kafka 也支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。这与其他队列系统不同,其他队列系统的消息一旦被一个客户端读取,其他客户端就无法再读取它。另外,多个消费者可以组成一个群组,它们共享一个消息流,并保证整个群组对每个给定的消息只处理一次。
基于磁盘的数据存储
Kafka 不仅支持多个消费者,还允许消费者非实时地读取消息,这要归功于 Kafka 的数据保留特性。消息被提交到磁盘,根据设置的保留规则进行保存。每个主题可以设置单独的保留规则,以便满足不同消费者的需求,各个主题可以保留不同数量的消息。消费者可能会因为处理速度慢或突发的流量高峰导致无法及时读取消息,而持久化数据可以保证数据不会丢失。消费者可以在进行应用程序维护时离线一小段时间,而无需担心消息丢失或堵塞在生产者端。消费者可以被关闭,但消息会继续保留在 Kafka 里。消费者可以从上次中断的地方继续处理消息。
伸缩性
为了能够轻松处理大量数据,Kafka 从一开始就被设计成一个具有灵活伸缩性的系统。用户在开发阶段可以先使用单个 broker,再扩展到包含 3 个 broker 的小型开发集群,然后随着数据量不断增长,部署到生产环境的集群可能包含上百个 broker。对在线集群进行扩展丝毫不影响整体系统的可用性。也就是说,一个包含多个 broker 的集群,即使个别 broker 失效,仍然可以持续地为客户提供服务。要提高集群的容错能力,需要配置较高的复制系数。
高性能
上面提到的所有特性,让 Kafka 成为了一个高性能的发布与订阅消息系统。通过横向扩展生产者、消费者和 broker,Kafka 可以轻松处理巨大的消息流。在处理大量数据的同时,它还能保证亚秒级的消息延迟。
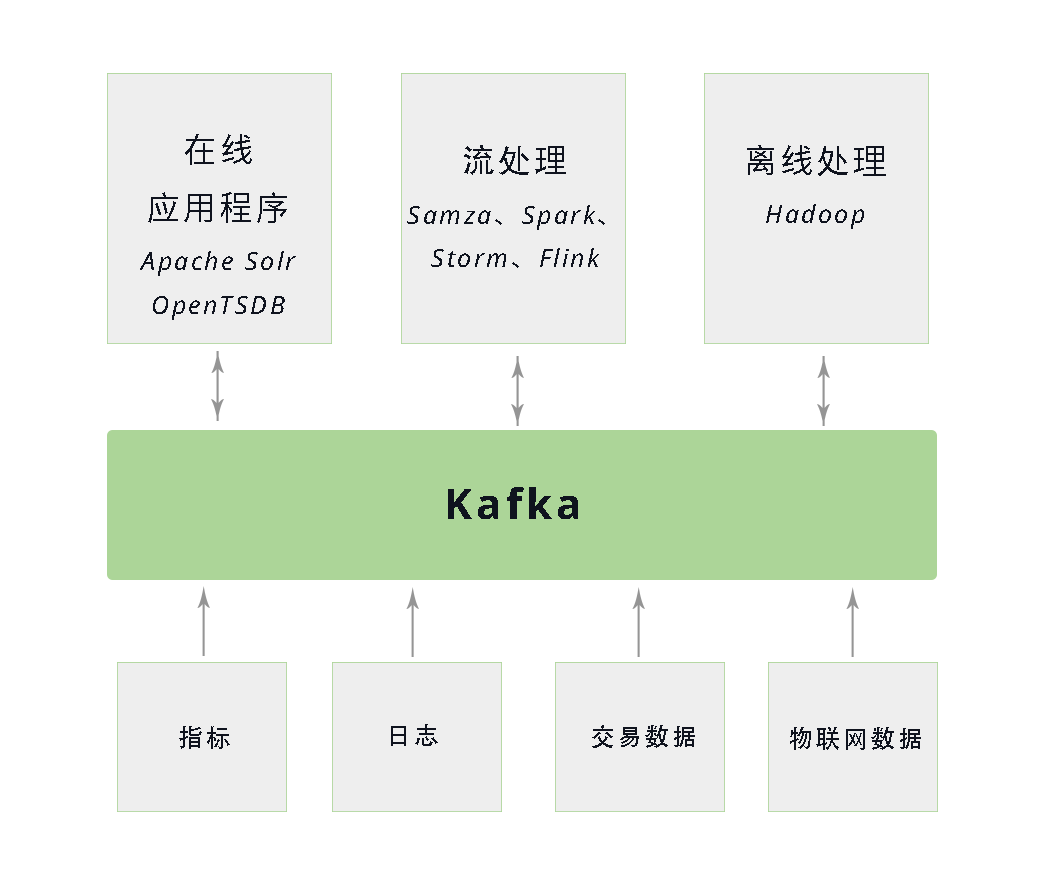
生态系统
Kafka 为数据生态系统带来了循环系统,如图所示。它在基础设施的各个组件之间传递消息,为所有客户端提供一致的接口。当与提供消息模式的系统集成时,生产者和消费者之间不再有紧密的耦合,也不需要在它们之间建立任何类型的直连。我们可以根据业务需要添加或移除组件,因为生产者不再关心谁在使用数据,也不关心有多少个消费者。
受欢迎程度
王国璋在 “Kafka从0.7到1.0:过去7年我们踩过哪些坑?” 这篇文章中提到如下数据:2018 年上半年,Confluent 做过一个统计,在福布斯 500 强公司里,大概有 35% 的公司都在使用 Kafka。具体到不同的行业,全世界前 10 大旅行公司中有 6 个在使用 Kafka,全世界***的 10 个银行有 7 个在用 Kafka,***的 10 个保险公司有 8 个在用 Kafka,***的 10 个通讯公司中有 9 个在用 Kafka。在国外,Netflix、Uber、Airbnb、PayPal、The New York Times 等都是 Kafka 的重度用户。
道且长
Kafka 一直是***的消息队列解决方案。近年,Kafka 努力转型为一个流数据平台。随着基础设施的云化和容器化,跟容器化架构的整合,与既有框架的结合等是 Kafka 面临的主要挑战。在计算与存储分离、更好地适应容器化架构方面,Pulsar 的呼声渐高。Jesse Anderson 详细比较了使用 Kafka 和 Pulsar 创建工作队列的优缺点,你可以访问jesse-anderson的网站参考这篇文章《Creating Work Queues with Apache Kafka and Apache Pulsar》。未来,不管哪个架构都需要不断进化。
深入了解与使用
如果你想深入细致了解使用 Kafka 快速高效地构建生产者和消费者实例,使用 Kafka Streams、Kafka Connect 和 KSQL 在流处理和运维上提升 Kafka 的平台性能,以及整个生态系统的发展趋势,那么——
资深大数据工程师、培训师 Jesse Anderson 在O’Reilly主办的 AI Conference 2019北京站上主讲的「Kafka 专业开发」课程值得学习。
即使你并不会编写复杂的代码, KSQL 也会让你快速上手流处理。
导师:Jesse Anderson (Big Data Institute)
Topic: Professional Kafka Development
下面是一个为期两天的培训大纲。
周三(6月18日)
Data at scale
- Data movement concepts
- Moving data at scale
Kafka concepts
- Kafka system
- Basic concepts
- Advanced concepts
Developing with Kafka
- Using Apache Maven
- Kafka APIs
- Kafka API caveats
Advanced Kafka development
- Advanced consumers and producers
- Advanced offset handling
- Transactions
- Multithreading consumers
周四(6月19日)
Kafka and Avro
- Why serialize
- Avro and serialization formats
Kafka Connect
- Using Kafka Connect
- Importing from JDBC
- Exporting to HDFS
Kafka Streams
- Kafka Streams
- The Kafka Streams API
KSQL
- Using KSQL
Wrap-up and Q&A

参会指南
AI Conference 2019北京站正在火热报名中,请搜索AI大会或人工智能大会,进入官网查看讲师和议题详情。