












根据一些度量指标,在过去两年,有关生成式对抗网络(GANs)的研究中已经取得了长足进步。图像合成模型的实际改进(如下所示),几乎快得让人跟不上。

然而,根据其它度量指标,研究并没有很大的进展。例如,关于评估GANs的方法仍存在着广泛的分歧。鉴于目前图像合成基准似乎有点处于饱和的状态,现在是时候要反思下这个子领域的研究目标。
本文将列出研究中的7个开放性问题,希望能在不久的将来,这些未解之谜能有答案。
如何在GANs和其它生成模型之间权衡?
除了GANs之外,目前还流行其它两种生成式模型:流动模型和自回归模型。粗略地说,流动模型可将一堆可逆变换应用于先验样本中,以便计算出观测数据中的对数似然性。另一方面,自回归模型可将观测数据的分布因式分解为条件分布,并一次处理一个观测成分(对于图像,该模型可以一次处理一个像素)。
最近的研究表明这些模型具有不同的性能特征和权衡。一个耐人寻味的开放性问题是:如何准确地描述这些权衡,并决定其是否是这些模型的基本特质?
具体来说,让我们暂时关注GANs和流动模型之间计算成本的差异。乍一看,使用流动模型似乎可能会使GANs的存在多余,原因是:流动模型还考虑到精确的对数似然性计算和精确推理。因此如果训练流动模型和GANs具有相同的计算成本,那么GANs可能没有什么用。既然花费了大量的精力训练GANs,那么看起来我们更要关心流动模型是否会把GANs淘汰掉。
但是,训练GANs和流动模型的计算成本似乎存在着巨大的差距。为了估计这个差距的大小,可以参考两个在人脸数据集上训练的模型。
GLOW模型经过训练,可以使用40个GPU连续2周生成256x256个名人的脸,涉及约2亿个参数。相比之下,逐步发展的GANs经过训练,可以在同样的数据集上使用8个GPU,连续4天使用大约4600万个参数,生成1024x1024个图像。
粗略地说,流动模型要花费17倍的使用GPU的天数,以及使用4倍多的参数,才能生成减少了16倍的像素。这种比较虽不严谨,但是还是能给我们提供一些参考的。
为什么流动模型效率较低?可能有以下两个原因:首先,极大似然训练在计算层面比对抗训练更难。特别是,如果训练集的任何元素被生成模型确定为零概率,那么其将受到极其严厉的惩罚!另一方面,GAN生成器只会因为给训练集元素确定为零概率而间接地受到惩罚,并且这种惩罚不那么严厉。其次,规范化流程可能是表示某些函数的低效方法。
我们已经讨论过GANs模型和流动模型之间的权衡,但是自回归模型的权衡又是什么呢?事实证明,自回归模型可以表示为不可并行的流动模型(因为二者都可逆)。结果还表明,自回归模型在时间和参数上比流动模型更有效率。总的来说,GANs是高效并行但不可逆的,流动模型是可逆并行但不高效的,而自回归模型是可逆高效但不并行的。
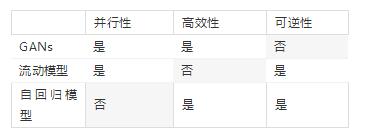
这引出了一个开放性问题:
问题1:GANs和其它生成模型之间的基本权衡是什么?特别是能否对可逆性、并行性和参数/时间效率做出某种CAP定理类型的声明。
解决这个问题的一种方法是研究混合了更多模型的模型混合体。该方法已被考虑用来混合GAN和流动模型,但是这种方法仍未得到充分探索。
我们也不确定极大似然训练是否一定比GAN训练更难。的确,在GAN训练损失的情况下,并没有明确禁止在训练数据点上放置零权值,但是如果生成器这样做,那么一个足够强大的判别器能够做得比这个更好。不过,看起来GANs在实践中似乎正在学习低支持度的分布。我们怀疑流动模型关于每个参数的表达能力根本不如任意解码器函数,而且这在某些假设下是可证明的。
GANs可以为哪种分布建模?
大多数GAN的研究都侧重于图像合成,特别是在一些标准的(在深度学习社区中)图像数据集上训练GANs,包括:MNIST、CIFAR-10、STL-10、CelebA 和Imagenet。
关于哪些数据集最容易建模,有一些非官方的说法。比如MNIST和CelebA被认为比Imagenet、CIFAR-10、或STL-10更容易建模,因为它们“非常有规律”。其他人注意到,“大量的类使得ImageNet的图像合成对GANs来说非常困难。”这些观察得到了经验事实的支持,即CelebA上图像合成模型生成的图像看起来比Imagenet上图像合成模型更具说服力。
然而,在这个费时费力而且争论不休的过程中,必须通过在越来越大和越复杂的数据集上进行GANs的训练尝试才能得出结论。这个过程主要研究了GANs对碰巧存在于对象识别的数据集的执行方法。
与任何科学一样,我们希望有一个简单的理论来解释实验观察数据。理想情况下,可以查看一个数据集,执行一些需要计算而无需实际训练的模型,然后说出“这个数据集对于GAN来说很容易建模,但是对于VAE来说就不一样。”这个问题上已经取得了一些进展,但仍存在以下问题:
问题2:给定一个分布,用GAN对该分布建模的难度有多大?
“为分布建模”是什么意思?是否对低支持表示感到满意还是想要真正的密度模型?有没有GAN永远无法学到的为分布建模的方法?对于一些合理的资源消耗模型,原则上是否有为GAN学习,但是不能有有效学习的分布呢?对于GAN而言,这些问题的答案是否与其它生成模型不同?
以下两种策略可以回答这些问题:
- 合成数据集:通过研究合成数据集来探究影响可学习性的特征。例如,作者创建了合成三角形的数据集。这个领域尚未得到充分的研究。为了进行系统研究,合成数据集甚至可以由感兴趣的量参数化,例如连接度或平滑度。这样的数据集也可用于研究其它类型的生成模型。
- 修改现有的理论结果:现有理论结果加上尝试修改假设导致数据集有不同的属性。例如,可以获取GANs应用于给定单峰分布数据的结果,并了解当数据分布变为多模态时会发生什么。
如何在图像合成之外扩展GANs?
除了图像到图像的转化和域适应等应用之外,大多数GAN的成功应用都是在图像合成方面。GAN在图像之外的应用主要集中在以下三个领域:
- 文本:文本的离散性使得 GANs的应用变得困难。这是因为GANs依赖于从判别器开始将信号通过生成的内容反向传播到生成器。有两种方法可以解决这个问题。首先,GAN只对离散数据的连续表示起作用,如下所示。第二种是使用实际的离散模型,并尝试使用梯度估计来训练GAN。其实还有其它更复杂的处理方法,但就我们所知,它们与基于可能性的语言模型相比,都不能产生具有竞争性(就困惑而言)的结果。
- 结构化数据:其它如图表等非欧几里得式的结构化数据是什么呢?对这类数据的研究称为几何深度学习。GANs在这方面成果有限,但其它的深度学习技术也是如此,因此很难理清GAN的重要性。在该领域,有过使用GANs的尝试,即让生成器生成(和判别器“评判”)随机游动,这些随机游动与从源图中采样的随机游动相似。
- 音频:音频是GANs最接近成功实现合成图像的领域。作者对GANs在音频上操作做了各种特殊的考虑。最近研究表明,GANs甚至可以在一些感知指标上超越自回归模型。尽管已经存在这些尝试,图像仍然是GANs最容易处理的领域。对此引出第三个问题。
问题3:如何使GANs在非图像数据上表现良好?将GANs扩展到其它领域是否需要新的训练技术?还是仅仅需要为每个领域提供更好的隐式先验?
期望GANs最终能够在其它连续数据上实现图像合成级别的成功,但它需要更好的隐式先验。找到这些先验需要仔细思考在给定的领域里什么是有意义的,什么是可计算的。
结构化数据或非连续数据的界限比较模糊,一种可能的方法是使生成器和判别器推动强化学习训练。要使这种方法有效,可能需要大规模的计算资源。解决这个问题可能只需要基础研究。
如何描述GAN训练的全局收敛性?
GAN训练与其他神经网络训练不同,因为我们会交替优化生成模型和判别模型来对抗目标。在特定假设的前提下,这种交替优化会逐渐达到局部稳定。
然而,从总体来看,一些有趣的事情很难进行证明。这是因为判别模型/生成模型的参数均为非凸性损失函数。不过,这是所有神经网络的通病。我们希望有方法能重点解决交替优化所造成的问题。于是就产生了下面的疑问:
问题4:何时能够证明GAN具有全局收敛性?哪一种神经网络收敛性结果能够应用于GAN?
以上问题已经取得了不少进展。一般来说,目前有3种技术均取得了可喜的成果,但对这3种技术的研究尚不完善:
- 简化假设——一种策略是对生成模型和判别模型做出简单化假设。例如,通过某些特殊技术及条件假设进行优化后,简化后的LGQ GAN(L代表线性生成模型,G代表满足高斯分布的数据,Q代表二次判别模型)能够表现出全局收敛性。逐渐放开这些假设并观察结果似乎前景广阔。例如,避免单峰分布。单峰分布是一种自然的松弛(relaxation),因为“模式崩溃”(Mode Collapse)是标准的GAN异常状态。
- 使用常规神经网络技术——第二种策略是应用分析常规神经网络(非凸)的技术来解答有关GAN收敛性的问题。例如,《TheLoss Surfaces of Multilayer Networks》一文提出深度神经网络的非凸性并不是问题,因为随着神经网络扩大,损失函数的低质量局部极小值点的数量呈指数级减少。这一分析结果是否可以“应用于GAN领域”?事实上,对用作分类器的深度神经网络进行分析,并看其是否适用于GAN,这种启发式算法似乎通常行之有效。
- 博弈理论——一种策略是根据博弈论的原理进行GAN训练。这些技术能够得出可收敛到某种接近于纳什均衡点的训练步骤(这一点可进行验证),而且这一过程是在资源限制的情况下完成的。显然,下一步就是要尽可能减少资源限制。
应该如何评估GAN,又该何时使用GAN?
目前评估GAN的方法有很多,但尚未达成统一。这些方法包括:
- 初始分数和FID(Fréchet 距离)——二者都使用经过预先训练的图像分类器,且都存在已知问题。而且,二者测量的是“样本质量”,并没有真正捕捉到“样本多样性”,这一点常为人诟病。
- MS-SSIM——该方法可以使用MS-SSIM单独评估多样性,但这一技术还存在一定问题,并没有真正流行起来。
- AIS——该方法建议在GAN的输出后串接一个高斯观测模型(Gaussian observation model),并使用退火重要性采样代码(annealedimportance sampling)估算该模型下的对数似然值。然而,由于GAN生成模型也是流模型,这种计算方法并不准确。
- 几何分数——该方法建议计算生成的数据流形的几何属性,并将这些属性与实际数据进行对比。
- 精确和召回——该方法建议测量GAN的“精确率”和“召回率”。
- 技能等级——该方法已表明, 经过训练的GAN判别模型能够包含可用于评估的有用信息。
这些只是GAN评估方案中的一小部分。尽管初始分数和FID相对更受欢迎,但究竟用那种方法进行GAN评估显然尚未有定论。我们认为,不知道如何评估GAN是因为不知道何时使用GAN。因此,将这两个问题合为问题5:
问题5:什么时候该使用GAN而不是其他生成模型?如何评估GAN在这些背景下的表现?
用GAN来做些什么?要想得到真正的密度模型,GAN可能不是很好的选择。目前已有实验表明,GAN学习了目标数据集的“低支撑集(low support)”表征,这意味着GAN可能(隐式地)给测试集大部分数据分配为零似然度。
将GAN研究的重点放在支撑集不会造成问题甚至还有一定帮助的任务上。GAN可能非常适合感知类型的任务,如图像合成,图像转换,图像填充和属性操作等图形应用程序。
如何评估GAN在完成这些感知任务中的表现?理想状态下,可以使用人力判断,但这样成本很高。低成本的代理服务器能够查看分类器是否可以区分真实和假的样本,这一过程即为分类器双样本测试(C2STs)。这一测试的主要问题是,生成模型哪怕出现一个跨越样本系统性的微小缺陷,那么这个缺陷将会对评估结果产生决定性影响。
在理想状态下,整体评估不受单一因素的支配。可行的方法之一是引入一个忽略显性缺陷的critic(批评者)。但是,一旦这样做,可能会有其他缺陷占据主导地位,于是就需要另一个critic,然后这一过程不断重复。如果采取迭代的方式,就可以得到一种“Gram-Schmidt procedure for critics”,并创建一个有序列表,其中包含最重要的缺陷和能够将其忽略的critic。也许这可以通过在critic激活上执行PCA(主成分分析),并逐步抛弃越来越多的更高方差分量来完成。
尽管有所取舍,我们仍可以对人类进行评估。这将使我们得以测量我们真正关心的事情。通过预测人类答案,并在预测不确定时仅与真人交互,可以减少这种方法的成本。
GAN训练如何改变批量大小?
已知大规模minibatch有助于扩展图像分类,那么它们是否也可以帮助扩展GAN?对于有效使用高度并行化的硬件加速器,规模较大的minibatch或能起到重要作用。
乍一看,答案似乎是肯定的——毕竟,大多数GAN中的判别模式不过是一个图像分类器。如果在梯度噪声上遇到瓶颈,则大规模的minibatch可以加速训练过程。然而,GAN有一个分类器所没有的特殊瓶颈,也就是说,二者的训练过程可能有所不同。因此,我们提出如下问题:
问题6:GAN训练时如何确定批量?梯度噪声在GAN训练中的作用有多大?是否可以修改GAN训练,使其更好地改变批量大小?
有证据表明,增大minibatch的规模能够改进量化结果并缩短训练时间。如果这种现象始终存在,则表明梯度噪声是一个主导因素。不过,这一点尚未得到系统研究,因此我们认为这个问题仍待解决。
交替训练程序是否可以更好地利用大规模批训练?理论上,传输GAN的收敛性比普通GAN更好,但需要更大规模的批量,因为传输GAN需要将批量样本和训练数据对齐。因此,传输GAN很有可能用于将GAN的批量扩展至非常大的规模。
异步SGD算法(异步随机梯度下降)可以成为利用新硬件的不错选择。在这种设定中,限制因素往往在参数的“陈旧”副本上进行计算更新梯度。但实际上,GAN似乎真正得益于对过去的参数快照(snapshots)的训练,因此我们可能会产生疑问,异步SGD是否以特殊方式与GAN训练进行交互?
GAN与对抗性例子之间有什么关系?
众所周知,对抗性例子会对图像分类器造成影响:人类不易察觉的扰动会导致分类器在添加图像时输出错误结果。有的分类问题通常可以进行有效学习,但是要想学得稳健,难度就非常大了。
由于GAN判别模型是一种图像分类器,有人可能担心它会遇到对抗性例子。尽管研究GAN和对抗性例子的文献浩如烟海,但关于二者如何联系在一起的文献少之又少。因此,提出以下问题:
问题7:判别模型对抗性的稳健性如何影响GAN训练?
对这个问题,该从哪里入手呢?在给定一个判别模型D的情况下,如果生成样本G(z)被正确地判别为假样本,且存在小扰动p,使得G(z)+ p即被判别为真样本,则D就有了对抗性例子。对于GAN,我们要关注的是生成模型的梯度更新将产生新的发生器G',其中,G'(z)= G(z)+ p。
这个问题是现实存在的吗?生成模型的对抗性例子表明,对生成模型的故意威胁起到了作用。我们有理由相信这些意外威胁发生的可能性较小。首先,在判别模型再次更新前,生成模型只能进行一次梯度更新;而目前对抗性威胁通常会进行几十次迭代。其次,给出一部分来自先验分布的梯度不同的样本,能够优化生成模型。该优化过程发生在生成模型的参数空间(而非像素空间)。但是,这些论点都没有完全排除生成模型创造对抗性例子的可能。因此,进一步探讨这一话题能够取得丰硕的成果。

















