本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
随着训练数据量的增加和深度神经网络(DNN)的日益复杂,分布式计算环境(如GPU集群)被广泛采用,以加速DNN的训练。分布式计算网络在机器学习方面的瓶颈在于节点之间的数据传输效率,那如何在这一网络下高效地进行AI训练?
2018年,中国香港浸会大学异构计算实验室与MassGrid合作,通过研究提出一种可用于低带宽网络的全局Top-k稀疏化的分布式同步SGD算法,并通过实验论证出在低带宽网络下也能高效进行AI训练。目前实验结果及相关论文已被ICDCS workshop收录。
数据并行的分布式同步随机梯度下降(S-SGD)方法是训练大规模神经网络常用的优化器之一。与单节点的SGD相比,S-SGD将工作负载分配给多个计算节点以加速训练,但它也引入了在每次迭代中交换模型参数或梯度的通信开销。
举例说明
假设有P个节点用S-SGD训练DNN模型。在每次迭代中,所有计算节点都会采用不同的小批量(mini-batch)数据来并行计算模型的梯度。然后,对每个节点的梯度进行平均后来更新模型,这便引入较大的通信开销。
由于计算节点的加速器(如GPU和TPU)的计算能力比网络速度的增长快得多,网络通信性能通常成为训练的性能瓶颈,特别是当通信与计算比率很高时。
许多大型IT公司使用昂贵的高速网络(如40 / 100Gbps IB或以太网)来减少通信压力,但仍有许多研究人员和小公司只能使用由1Gig-Ethernet等低带宽网络连接的消费级GPU。
为了克服通信的性能瓶颈,可以通过使用更大的mini-batch来增加工作负载从而降低通信与计算比,或者减少每次通信过程中所需的通信量:
- 一方面,许多大批量SGD技术已经提出了一些优化策略来提高mini-batch而不会丢失模型准确性。
- 另一方面,研究人员也已经提出了梯度稀疏化,量化和压缩等方法,在不影响收敛速度的情况下显着减小交换梯度的数量以降低通信量。
在模型/梯度压缩技术中,Top-k稀疏化是关键方法之一,它可以将每个节点梯度稀疏到约为原来的千分之一(即 99.9%的梯度置为零而无需传输这些零值)。
Top-k稀疏化是一种较有效的梯度压缩方法,相关研究已做进行了实验和理论论证。
Top-k稀疏化的S-SGD在每次迭代中只需传输少量的梯度进行平均也不影响模型收敛或精度。然而,稀疏化后的非零值梯度所在的索引位置在不同的计算节点是不一致的,这使得高效的稀疏化梯度聚合成为一项挑战。
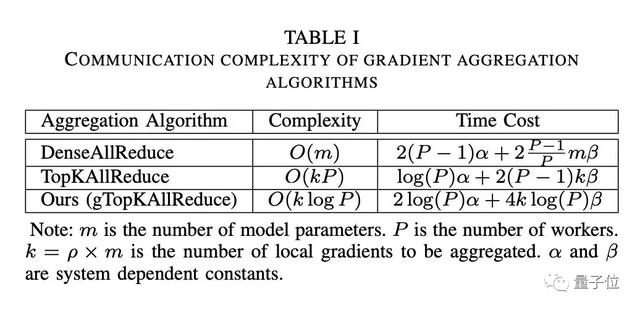
在稠密梯度上使用基于环形的AllReduce方法(DenseAllReduce)的通信复杂度为 O(P + m),其中 P为计算节点个数,m为参数/梯度的数量。而在Top-k稀疏化中,假设每个节点的梯度稠密度为ρ,即 k = ρ×m ,因为每个节点非零值的对应的索引在不同节点是不一致的。
因此,每次通信需要传输 2k个值(梯度值和索引)。采用AllGather对这2k个值进行聚合(简称TopKAllReduce)则需要O(kP)的通信复杂度。当扩展到大规模集群时(即P很大),即使k较小也仍会产生显着的通信开销。
Top-k稀疏化的主要思想是基于这样一个事实,即具有较大绝对值的梯度可以为模型收敛做出更多贡献。因为在Top-k算法中,即使P个计算节点在聚合后***可生成 k×P个非零值梯度,但***绝对值***的 k个梯度值对于模型更新则更重要。
基于这一观察,香港浸会大学异构计算实验室与MassGrid的研究人员,提出了一种有效的Top-k稀疏化方法来解决TopKAllReduce的低效问题。
具体而言,根据不同节点的梯度绝对值来选择全局的Top-k(简称gTop-k)梯度。在本文中,研究人员主要讨论使用AllReduce的分布式S-SGD来应用gTop-k稀疏化,但它也适用于基于参数服务器的分布式S-SGD。
gTop-k可以很好地利用树结构从所有节点中选择全局top-k值,并称之为gTopKAllReduce,而通信复杂性从原来的O(kP)减少到O(klogP)。表1中总结了不同梯度聚合方法的通信复杂度。
在实验研究及所发表的论文中主要贡献如下:
- 研究人员观察到Top-k稀疏化的聚合结果可以在更新模型前做进一步稀疏化。
- 在分布式SGD上提出了一种有效的全局Top-k稀疏化算法,称为gTop-k S-SGD,用于加速深度神经网络的分布式训练。
- 在主流的深度学习框架PyTorch和MPI上实现了gTop-k S-SGD,代码和参数配置将在GitHub上开源。
- 在多种神经网络和数据集进行了实验验证,实验结果表明gTop- k S-SGD在低带宽网络GPU集群上(MassGrid矿机集群)显着地提高系统的扩展效率。
- MassGrid分布式计算网络使用虚拟化技术将全球范围可用的计算资源虚拟成通用计算设备,可快速部署连接组网进行大规模分布式计算,具有成本低,使用灵活等优势。本次实验中MassGrid提供了配置如下的矿机集群:

训练方法
gTop-k的关键思想
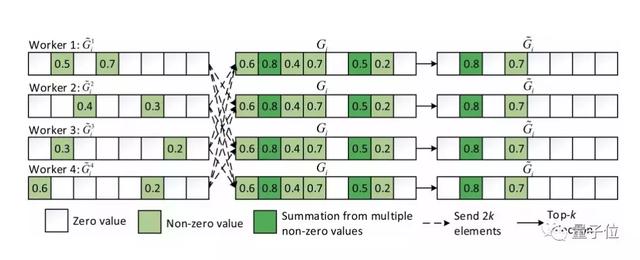
在Top-k S-SGD中,每个节点在本地选出k个梯度值,然后所有节点进行聚合得到。研究人员发现并非所有(其非零元素数量为且)都有助于模型收敛。
具体来说,可以进一步稀疏化为,这样每次模型更新只需要更少数量的非零梯度。换句话说,可以进一步从中选择top-k个***绝对值的梯度(表示为)来更新模型,同时保证模型的收敛速度。一个4节点的示例如图1所示。
△ 图1 从Top-k算法中的最多k×P个非零值进一步选择k个梯度示例
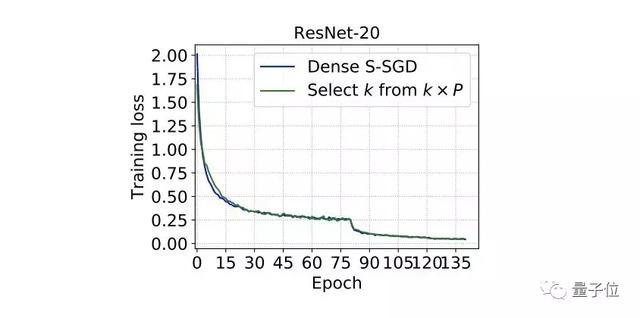
为验证相比对收敛速度没有影响,通过训练ResNet 来进行对比,实验结果如图2所示。
△ 图2 从Top-k算法中选择k个梯度进行模型更新的收敛结果
gTopKAllReduce:gTop-k稀疏化的高效AllReduce算法
从表1可以看到AllGather集合对从不规则索引进行AllReduce操作效率很低,特别是P对通信性能的影响。而新提出的有效算法的主要目的是减轻变量P对通信开销的影响。因为最终只需要选择k个值对模型进行更新,所以在通信过程中,每次只需要传输k个非0值。
利用树状结构进行两两通信,每次只传输k个非0值,而接收者则会有2k个值,为下次传输也只传输k个值,接收者从2k个值中再选出k个值传递给下一个接收者。由于两两通信是可以同时进行,因此对于P个节点,只需要logP轮通信,一个8节点的示例如图3所示。
由图3可以看出,第1个节点在每一轮通信中都会接收另一个节点的k个非0元素,在***一轮通信后,第1个节点则选出了k个非0元素然后广播给其他节点,所以整体的通信开销为:2αlogP + 4kβlogP。当机器规模P变大时,gTop-k还能维持较高的扩展性。算法伪代码为图4所示。
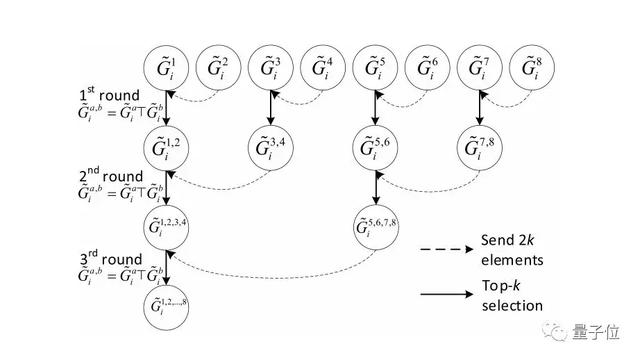
△ 图3 对8个节点,共需要3轮通信,每轮通信只传输k个非0值

△ 图4 gTopKAllReduce算法伪代码
实验结果
中国香港浸会大学异构计算实验室与MassGrid的研究人员在32台矿机环境上进行实验,每台矿机使用一个Nvidia P102-100显卡。
首先验证gTop-k S-SGD的收敛性。之后,对三种S-SGD算法(即基于稠密梯度的S-SGD,Top-k S-SGD和gTop-k S-SGD)的训练效率进行了比较。
实验具体硬件配置如表II所示

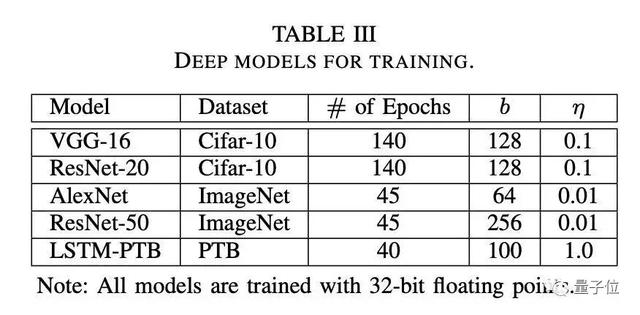
用于实验的神经网络配置如表III所示
gTop-k的收敛性能
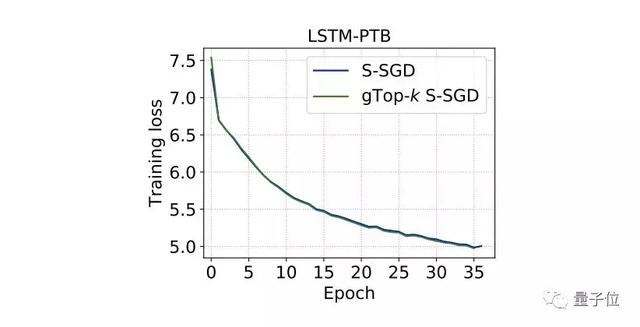
总体来看,在不同数据集上三种不同类型的DNN的收敛结果表明研究人员提出的gTop-k S-SGD在训练期间不会损坏模型性能。
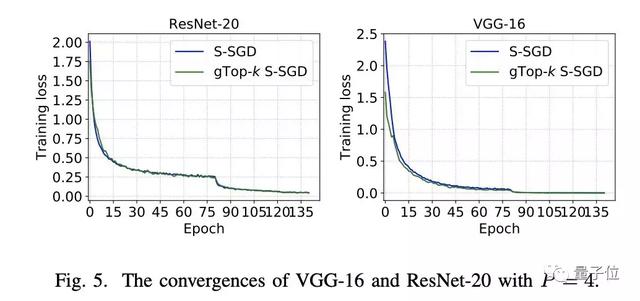
△ 图5 gTop-k S-SGD收敛性能
gTop-k的扩展性能
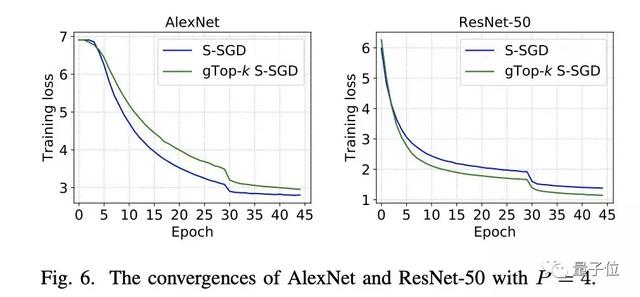
与S-SGD和Top-k S-SGD相比,在32个计算节点的集群环境上,gTop-k S-SGD比S-SGD快6.7倍,比Top-k S-SGD平均快1.4倍。不同的模型和不同节点数加速比如图6和表IV所示。
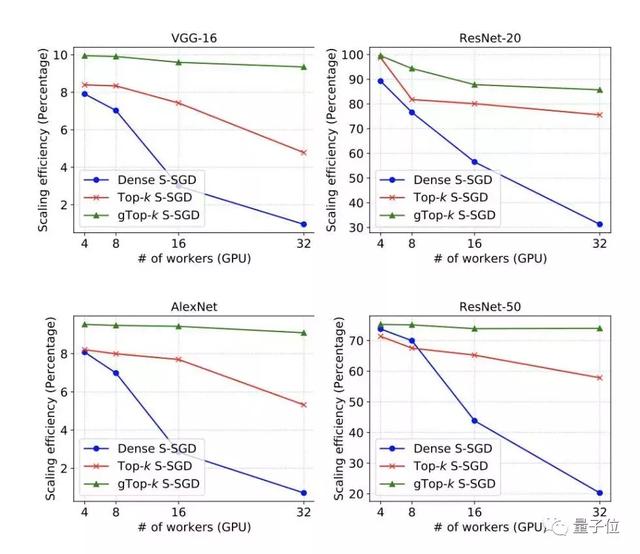
△ 图6不同节点数的扩展效率对比
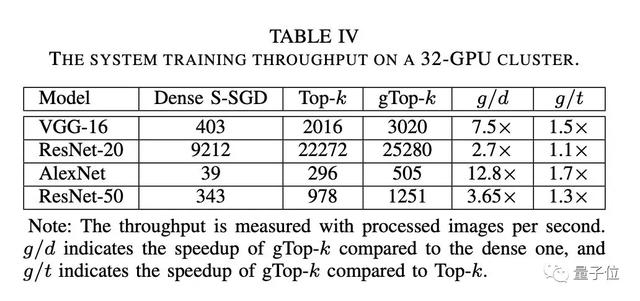
△ 表7不同模型的扩展效率对比
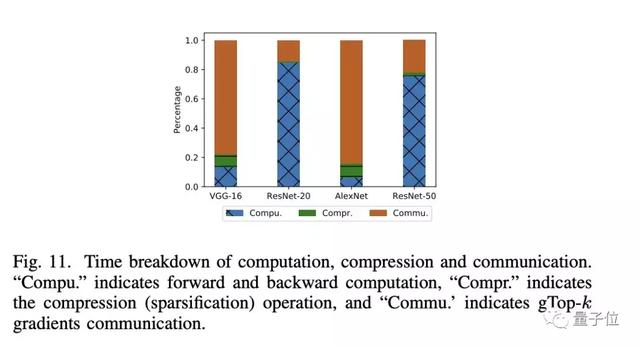
局部稀疏化时间(tcompr.)和通信时间(tcommu.)。结果如图11所示。
一方面,在VGG-16和AlexNet型号的时间细分中通信开销远大于计算。因为VGG-16和AlexNet有三个完全连接的层,具有大量参数,而计算速度相对较快。这些也反映出即使使用gTop-k稀疏化,图6中S-SGD的缩放效率也很低。
另一方面,通信和稀疏化的时间远小于使用ResNet20和ResNet-50计算的时间,这表明通信计算比率低,因此即使在低带宽网络上,扩展效率也可高达80%。
此外,应注意梯度稀疏化所用的时间是与VGG-16和AlexNet型号的计算时间相当。主要原因是GPU上的Top-k选择效率低下,并且在SIMD架构上高度并行化可能并非易事。研究人员将此作为未来的优化方向。
实验总结
分布式同步随机梯度下降(S-SGD)已经广泛用于训练大规模深度神经网络(DNN),但是它通常需要计算工作者(例如,GPU)之间非常高的通信带宽以迭代交换梯度。
最近,已经提出了Top-k稀疏化技术来减少工人之间要交换的数据量。Top-k稀疏化可以将大部分梯度归零,而不会影响模型收敛。
通过对不同DNN的广泛实验,这一研究验证了gTop-k S-SGD与S-SGD具有几乎一致的收敛性能,并且在泛化性能上只有轻微的降级。
在扩展效率方面,研究人员在具有32个GPU机器的集群上(MassGrid矿机集群)评估gTop-k,这些机器与1 Gbps以太网互连。
实验结果表明,该方法比S-SGD实现了2.7-12倍的缩放效率,比现有的Top-k S-SGD提高了1.1-1.7倍。
传送门
论文原文链接:https://arxiv.org/abs/1901.04359
更多关于MassGrid的应用场景请查询:www.massgrid.com