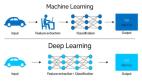
有些人认为 AI 和 ML 被过分夸大了,认为它们只不过是写一些 if 语句,或者仅仅是和编程有关的玩意儿,但我建议你对这些观点进行仔细的思考和分辨。在本文中,我将对它们涉及到的术语进行比较,并展示这两个领域的专家之间的区别:他们究竟是做什么的?软件工程师、软件开发人员、机器学习专家、数据科学家......有些人甚至用程序员或码农称呼他们,有些人甚至可以成为大佬、大师或明星!但是他们真的一样吗?如果是这样的话,那机器学习和传统编程之间究竟有什么区别?
首先,什么是机器学习?
尽管说起来很容易,AI 和 ML 只不过是 if 编程,或者更深入一点,它只是简单的统计数据。我们还能知道些什么呢? ML 只是一个描述数学 + 算法的新词吗?尽管有时这种简化似乎很有趣,但很明显,ML更复杂。
但是让我们来看一个更合适的解释。
因此,简单来说,人工智能是一个包含其他领域的大筐,如图像处理、认知科学、神经网络等等。机器学习也是这个大筐中的一个组成部分。它的核心思想是:计算机不只是使用了预先编写的算法,还学习如何解决问题本身。或者,换句话说,Arthur Samuel 给出了一个很好的定义(他实际上创造了ML的术语):
机器学习是一个研究领域,使计算机无需明确编程即可学习。
是的,ML 教一台机器来解决难以通过算法解决的各种复杂任务。那些任务是什么?好吧,你可能已经在实践中偶然发现了它们。例如它可以是你的手机上的面部识别或语音识别,驾驶汽车(Google自动驾驶汽车),按症状诊断疾病(Watson),推荐商品(如:书籍(亚马逊),电影(Netflix),音乐(Spotify) ),个人助理(Siri,Cortana)的功能......这个列表可以列的很长很长。
我希望说得已经足够清楚了,接下来继续谈论关于 ML 的另一个重要的问题。
任何有效的 ML 技术都可以有条件地归于三个级别的可访问性。这是什么意思?嗯,***个层面是 Google 或 IBM 等这种科技巨头的特殊用例。第二个层次是,比方说,具有一定知识的学生可以使用它。而***一个也就是 ML 可访问性的第三个层次是甚至一个老奶奶能够应对它。
我们目前的发展阶段是机器学习正处在第二级和第三级交界处。因此借助这项技术,世界的变化将会日新月异。
关于 ML ***还有一点点说明:大多数 ML 任务可以分为跟着老师学(监督学习)和没有老师去教(无监督学习)。如果你想象一个程序员一只手拿鞭子,另一只手拿着糖,那就有点误会了。
“老师”这个名字意味着人为干预数据处理的想法。在有老师参与培训时,这是监督学习,我们有数据,需要在其基础上预测一些事情。另一方面,当没有老师进行教学时,这是无监督学习时,我们仍然有数据,但需要自己去找到它的属性。
好的,那么它与编程有什么不同?

在传统编程中,你需要对程序的行为进行硬编码。在机器学习中,你将大量内容留给机器去学习数据。
所以这些工作内容无法互换:数据工程师无法取代传统编程的工作,反之亦然。尽管每个数据工程师都必须使用至少一种编程语言,但传统编程只是他所做的一小部分。另一方面,我们不能说软件开发人员正在用 ML 算法来启动网站。
ML 不是替代品,而是传统编程方法的补充。例如,ML 可用于为在线交易平台构建预测算法,而平台的 UI、数据可视化和其他元素仍然用主流编程语言(如Ruby或Java)编写。
所以最主要的是:ML 被用在传统编程策略无法满足的场景,而且它不足以独立完全完成某项任务。
那么这在实施中意味着什么呢?我们用一个汇率预测的经典 ML 问题的需求来进行解释:
传统的编程方法
对于任何解决方案,***个任务是创建最合适的算法并编写代码。之后必须设置输入参数,如果实现的算法没问题,将会产生预期的结果。
软件开发人员如何制定解决方案
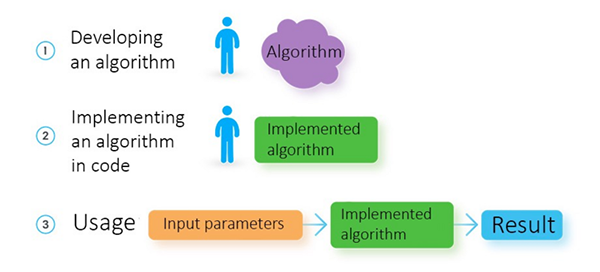
但是当我们要对某些东西进行预测时,需要用到有各种输入参数的算法。若要预测汇率,必须添加昨天的汇率的详细信息,以及发行货币的国家的外部和内部经济变化等数据。
因此,我们需要设计一个能够接受一组参数的解决方案,并能够根据输入的数据预测新的汇率。
我们需要添加成百上千个参数,用它们的有限集去构建一个非常基本同时不可扩展的模型。是的,任何人都很难处理如此庞大的数据阵列。
对于这个任务,我们可以用机器学习方法,那么它是怎么做的呢?
为了用 ML 方法解决相同的问题,数据工程师使用完全不同的过程。他们需要收集一系列历史数据用于半自动模型的构建,而不是自己去开发算法。
在得到一组令人满意的数据之后,数据工程师将其加载到已定制的 ML 算法中。结果会得到一个模型,这个模型可以接收新数据作为输入并预测新结果。
数据工程师如何用机器学习设计解决方案
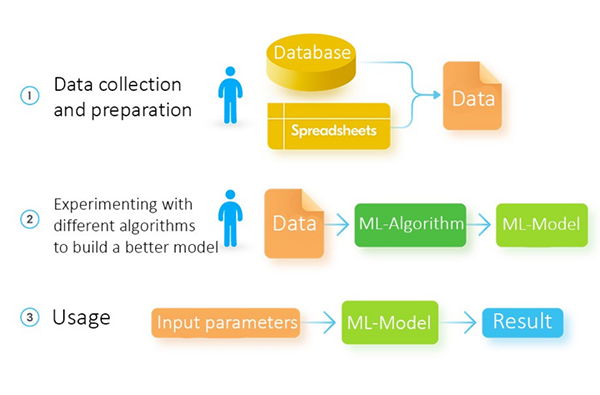
ML 的一个显著的特点是不需要建立模型。这种复杂但有意义的事由 ML 算法完成。 ML 专家只会对其做一个小小的编辑。
ML 与编程的另一个明显差异取决于模型能够处理的输入参数的数量。为了能够准确预测,你必须添加数千个参数并以高精度执行,因为每个参数都会影响最终结果。人类很难以合理的方式使用所有这些细节去构建一种算法。

但是对于 ML 没有这样的限制。只要你有足够的处理能力和内存,就可以根据需要使用尽可能多的输入参数。毫无疑问,这一事实使得 ML 现在变得如此强大和广泛。
总结一下:ML专家,数据科学家,程序员和软件工程师......究竟谁是谁?
根据 Wiki 上的定义,Data Science 是一个多学科领域,它使用科学方法、流程、算法和系统从结构化和非结构化数据中提取知识和见解。
看上去并不是那么酷。
但接下来还有一些有趣的东西:
使用***大的硬件,***大的编程系统,以及解决问题的最有效算法。
后面还有更有趣的部分:
2012年,“哈佛商业评论”称其为“21世纪最性感的工作”。
因此数据科学是另一个筐,就像计算机科学一样,数据科学旨在处理数据并从中提取有用的信息。
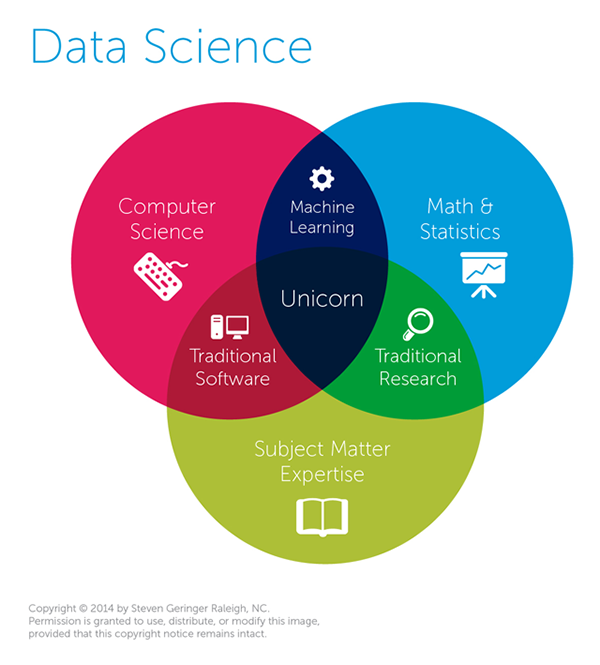
那么编程呢?现在的数据科学家为了研究的目的而而需要掌握这种技能。他们不仅是程序员,也应该具有应用统计或研究背景。有些人还从事软件工程,特别是在他们的产品中提供数据科学或机器学习技术的公司。最有趣的是,数据科学可以不必编程,但是会被限定在 Matlab、SPSS、SAS等工具上。
机器学习工程师的职位是怎样的?
机器学习工程师的位置更具有“技术性”。换句话说,机器学习工程师与传统的软件工程有着比数据科学更多的相同点。
ML 工程师的标准任务通常和数据科学家类似,但是你还需要处理数据,尝试用不同的机器学习算法来解决问题、创建原型和现成的解决方案。
我要强调一下关键的区别:
- 一种或多种语言(通常是Python)的强大编程技能;
- 不太重视在数据分析过程中工作的能力,而是更加重视机器学习算法;
- 能够基于现成的库使用不同的技术,例如,NumPy 或 SciPy;
- 使用 Hadoop 创建分布式应用的能力等。
现在让我们回到编程并仔细研究分配给程序员的任务。
程序员实际上就像数据分析师或业务系统开发人员。他们不必自己构建系统,只需针对现有系统编写松散结构的代码。是的,我们可以将数据科学称为新的编程浪潮,但编码只是其中的一小部分。所以不要误会。
但如果深入挖掘,我们会发现还有其他术语,如 Software Engineer 和 Software Developer,两者并不相同。例如软件工程师必须设计工程。它们涉及生产应用程序、分布式系统、并发、构建系统、微服务等。而软件开发人员需要了解软件开发的所有周期,而不仅仅是实现(有时甚至不需要任何编程或编码)。
那么,你现在感受到编程和机器学习的不同了吗?我希望本文可以帮你避免对这些术语产生混淆。毫无疑问,这些人都有一些共同点,那就是技术,但之间的差异要大得多。因此机器学习工程师、软件工程师和软件开发人员完全不可互换。