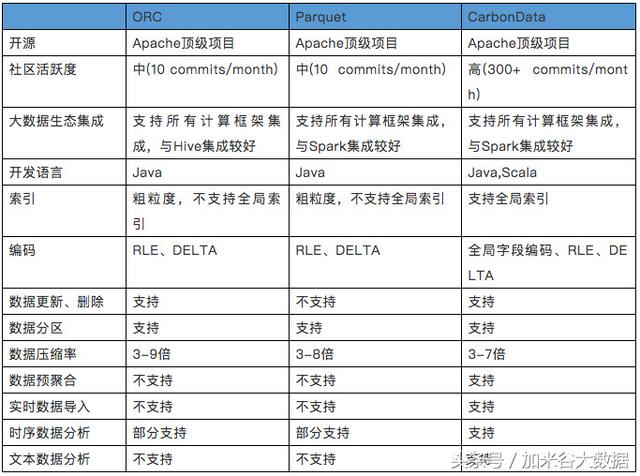
CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。目前官网发布版本1.3.0与***的spark稳定版Spark2.2.1集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性,相信会有越来越多的项目会使用到。
一、评测环境
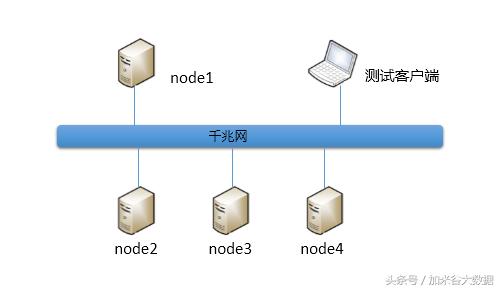
1)网络拓扑图
2)配置参数
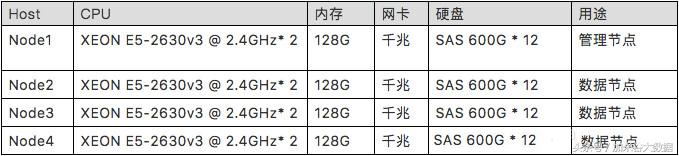
Ø 服务器配置
二、性能对比
目前主流hadoop的文件存储格式有行存储的CSV格式,列式存储的ORC和Parquet等。本章给出的是Parquet+Spark和CarbonData+Spark在过滤查询场景和聚合计算场景的性能测试结果。
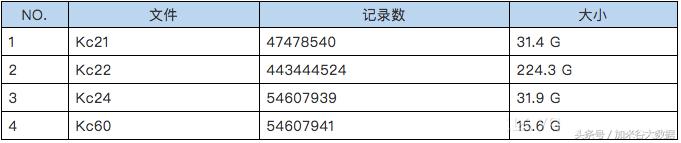
1)测试数据
创建沈阳社保的数据仓库,导入、集成1年的测试数据,如下表:
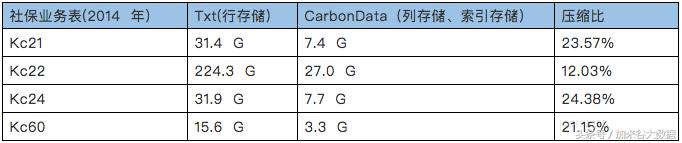
生成CarbonData格式文件,如下表:
2)过滤查询场景测试
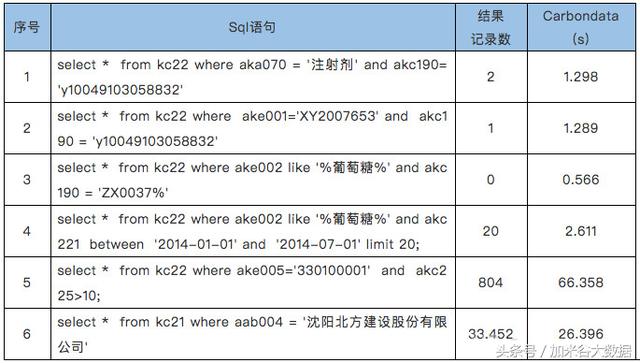
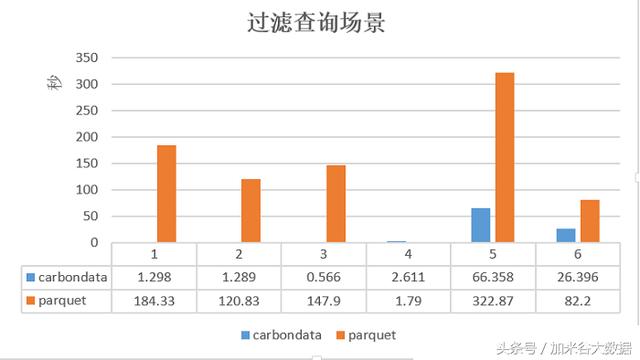
Parquet和CarbonData在过滤查询场景下的性能对比
3)聚合计算场景测试
Parquet和CarbonData在聚合计算场景下的性能对比
4)总结分析
在过滤查询中,CarbonData的查询效率比parquet效率好,主要体现在列数据的索引查询,极大地提高了精确查询的性能。在聚合查询中,CarbonData通过使用全局字典编码来加快计算速度,这使得处理、查询引擎可以直接在编码好的数据上进行处理而不需要转换数据,数据只有在返回结果给用户的时候才转换成用户可读的形式,通过索引有效过滤文件数据块减少磁盘的IO,提高查询性能。
三、小结
CarbonData在数据查询的性能表现比Parquet好很多,在写一次读多次的场景下非常适合使用;社区比较活跃,响应也很及时。目前官网发布版本1.3.0与***的spark稳定版Spark2.2.1集成,增加了支持标准的Hive分区,支持流数据准实时入库等新特性,相信会有越来越多的项目会使用到。