学习在 Linux 中进程是如何与其他进程进行同步的。
本篇是 Linux 下进程间通信(IPC)系列的***篇文章。这个系列将使用 C 语言代码示例来阐明以下 IPC 机制:
- 共享文件
- 共享内存(使用信号量)
- 管道(命名的或非命名的管道)
- 消息队列
- 套接字
- 信号
在聚焦上面提到的共享文件和共享内存这两个机制之前,这篇文章将带你回顾一些核心的概念。
核心概念
进程是运行着的程序,每个进程都有着它自己的地址空间,这些空间由进程被允许访问的内存地址组成。进程有一个或多个执行线程,而线程是一系列执行指令的集合:单线程进程就只有一个线程,而多线程的进程则有多个线程。一个进程中的线程共享各种资源,特别是地址空间。另外,一个进程中的线程可以直接通过共享内存来进行通信,尽管某些现代语言(例如 Go)鼓励一种更有序的方式,例如使用线程安全的通道。当然对于不同的进程,默认情况下,它们不能共享内存。
有多种方法启动之后要进行通信的进程,下面所举的例子中主要使用了下面的两种方法:
- 一个终端被用来启动一个进程,另外一个不同的终端被用来启动另一个。
- 在一个进程(父进程)中调用系统函数
fork,以此生发另一个进程(子进程)。
***个例子采用了上面使用终端的方法。这些代码示例的 ZIP 压缩包可以从我的网站下载到。
共享文件
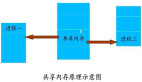
程序员对文件访问应该都已经很熟识了,包括许多坑(不存在的文件、文件权限损坏等等),这些问题困扰着程序对文件的使用。尽管如此,共享文件可能是最为基础的 IPC 机制了。考虑一下下面这样一个相对简单的例子,其中一个进程(生产者 producer)创建和写入一个文件,然后另一个进程(消费者 consumer)从这个相同的文件中进行读取:
writes +-----------+ readsproducer-------->| disk file |<-------consumer +-----------+
- 1.
- 2.
- 3.
在使用这个 IPC 机制时最明显的挑战是竞争条件可能会发生:生产者和消费者可能恰好在同一时间访问该文件,从而使得输出结果不确定。为了避免竞争条件的发生,该文件在处于读或写状态时必须以某种方式处于被锁状态,从而阻止在写操作执行时和其他操作的冲突。在标准系统库中与锁相关的 API 可以被总结如下:
- 生产者应该在写入文件时获得一个文件的排斥锁。一个排斥锁最多被一个进程所拥有。这样就可以排除掉竞争条件的发生,因为在锁被释放之前没有其他的进程可以访问这个文件。
- 消费者应该在从文件中读取内容时得到至少一个共享锁。多个读取者可以同时保有一个共享锁,但是没有写入者可以获取到文件内容,甚至在当只有一个读取者保有一个共享锁时。
共享锁可以提升效率。假如一个进程只是读入一个文件的内容,而不去改变它的内容,就没有什么原因阻止其他进程来做同样的事。但如果需要写入内容,则很显然需要文件有排斥锁。
标准的 I/O 库中包含一个名为 fcntl 的实用函数,它可以被用来检查或者操作一个文件上的排斥锁和共享锁。该函数通过一个文件描述符(一个在进程中的非负整数值)来标记一个文件(在不同的进程中不同的文件描述符可能标记同一个物理文件)。对于文件的锁定, Linux 提供了名为 flock 的库函数,它是 fcntl 的一个精简包装。***个例子中使用 fcntl 函数来暴露这些 API 细节。
示例 1. 生产者程序
#include <stdio.h>#include <stdlib.h>#include <fcntl.h>#include <unistd.h>-
#define FileName "data.dat"-
void report_and_exit(const char* msg) { [perror][4](msg); [exit][5](-1); /* EXIT_FAILURE */}-
int main() { struct flock lock; lock.l_type = F_WRLCK; /* read/write (exclusive) lock */ lock.l_whence = SEEK_SET; /* base for seek offsets */ lock.l_start = 0; /* 1st byte in file */ lock.l_len = 0; /* 0 here means 'until EOF' */ lock.l_pid = getpid(); /* process id */-
int fd; /* file descriptor to identify a file within a process */ if ((fd = open(FileName, O_RDONLY)) < 0) /* -1 signals an error */ report_and_exit("open to read failed...");-
/* If the file is write-locked, we can't continue. */ fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */ if (lock.l_type != F_UNLCK) report_and_exit("file is still write locked...");-
lock.l_type = F_RDLCK; /* prevents any writing during the reading */ if (fcntl(fd, F_SETLK, &lock) < 0) report_and_exit("can't get a read-only lock...");-
/* Read the bytes (they happen to be ASCII codes) one at a time. */ int c; /* buffer for read bytes */ while (read(fd, &c, 1) > 0) /* 0 signals EOF */ write(STDOUT_FILENO, &c, 1); /* write one byte to the standard output */-
/* Release the lock explicitly. */ lock.l_type = F_UNLCK; if (fcntl(fd, F_SETLK, &lock) < 0) report_and_exit("explicit unlocking failed...");-
close(fd); return 0;}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
上面生产者程序的主要步骤可以总结如下:
-
这个程序首先声明了一个类型为
struct flock的变量,它代表一个锁,并对它的 5 个域做了初始化。***个初始化lock.l_type = F_WRLCK; /* exclusive lock */
- 1.
使得这个锁为排斥锁(read-write)而不是一个共享锁(read-only)。假如生产者获得了这个锁,则其他的进程将不能够对文件做读或者写操作,直到生产者释放了这个锁,或者显式地调用
fcntl,又或者隐式地关闭这个文件。(当进程终止时,所有被它打开的文件都会被自动关闭,从而释放了锁) -
上面的程序接着初始化其他的域。主要的效果是整个文件都将被锁上。但是,有关锁的 API 允许特别指定的字节被上锁。例如,假如文件包含多个文本记录,则单个记录(或者甚至一个记录的一部分)可以被锁,而其余部分不被锁。
-
***次调用
fcntlif (fcntl(fd, F_SETLK, &lock) < 0)
- 1.
尝试排斥性地将文件锁住,并检查调用是否成功。一般来说,
fcntl函数返回-1(因此小于 0)意味着失败。第二个参数F_SETLK意味着fcntl的调用不是堵塞的;函数立即做返回,要么获得锁,要么显示失败了。假如替换地使用F_SETLKW(末尾的W代指等待),那么对fcntl的调用将是阻塞的,直到有可能获得锁的时候。在调用fcntl函数时,它的***个参数fd指的是文件描述符,第二个参数指定了将要采取的动作(在这个例子中,F_SETLK指代设置锁),第三个参数为锁结构的地址(在本例中,指的是&lock)。 -
假如生产者获得了锁,这个程序将向文件写入两个文本记录。
-
在向文件写入内容后,生产者改变锁结构中的
l_type域为unlock值:lock.l_type = F_UNLCK;
- 1.
并调用
fcntl来执行解锁操作。***程序关闭了文件并退出。
示例 2. 消费者程序
#include <stdio.h>#include <stdlib.h>#include <fcntl.h>#include <unistd.h>-
#define FileName "data.dat"-
void report_and_exit(const char* msg) { [perror][4](msg); [exit][5](-1); /* EXIT_FAILURE */}-
int main() { struct flock lock; lock.l_type = F_WRLCK; /* read/write (exclusive) lock */ lock.l_whence = SEEK_SET; /* base for seek offsets */ lock.l_start = 0; /* 1st byte in file */ lock.l_len = 0; /* 0 here means 'until EOF' */ lock.l_pid = getpid(); /* process id */-
int fd; /* file descriptor to identify a file within a process */ if ((fd = open(FileName, O_RDONLY)) < 0) /* -1 signals an error */ report_and_exit("open to read failed...");-
/* If the file is write-locked, we can't continue. */ fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */ if (lock.l_type != F_UNLCK) report_and_exit("file is still write locked...");-
lock.l_type = F_RDLCK; /* prevents any writing during the reading */ if (fcntl(fd, F_SETLK, &lock) < 0) report_and_exit("can't get a read-only lock...");-
/* Read the bytes (they happen to be ASCII codes) one at a time. */ int c; /* buffer for read bytes */ while (read(fd, &c, 1) > 0) /* 0 signals EOF */ write(STDOUT_FILENO, &c, 1); /* write one byte to the standard output */-
/* Release the lock explicitly. */ lock.l_type = F_UNLCK; if (fcntl(fd, F_SETLK, &lock) < 0) report_and_exit("explicit unlocking failed...");-
close(fd); return 0;}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
相比于锁的 API,消费者程序会相对复杂一点儿。特别的,消费者程序首先检查文件是否被排斥性的被锁,然后才尝试去获得一个共享锁。相关的代码为:
lock.l_type = F_WRLCK;...fcntl(fd, F_GETLK, &lock); /* sets lock.l_type to F_UNLCK if no write lock */if (lock.l_type != F_UNLCK) report_and_exit("file is still write locked...");
- 1.
- 2.
- 3.
- 4.
- 5.
在 fcntl 调用中的 F_GETLK 操作指定检查一个锁,在本例中,上面代码的声明中给了一个 F_WRLCK 的排斥锁。假如特指的锁不存在,那么 fcntl 调用将会自动地改变锁类型域为 F_UNLCK 以此来显示当前的状态。假如文件是排斥性地被锁,那么消费者将会终止。(一个更健壮的程序版本或许应该让消费者睡会儿,然后再尝试几次。)
假如当前文件没有被锁,那么消费者将尝试获取一个共享(read-only)锁(F_RDLCK)。为了缩短程序,fcntl 中的 F_GETLK 调用可以丢弃,因为假如其他进程已经保有一个读写锁,F_RDLCK 的调用就可能会失败。重新调用一个只读锁能够阻止其他进程向文件进行写的操作,但可以允许其他进程对文件进行读取。简而言之,共享锁可以被多个进程所保有。在获取了一个共享锁后,消费者程序将立即从文件中读取字节数据,然后在标准输出中打印这些字节的内容,接着释放锁,关闭文件并终止。
下面的 % 为命令行提示符,下面展示的是从相同终端开启这两个程序的输出:
% ./producerProcess 29255 has written to data file...-
% ./consumerNow is the winter of our discontentMade glorious summer by this sun of York
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
在本次的代码示例中,通过 IPC 传输的数据是文本:它们来自莎士比亚的戏剧《理查三世》中的两行台词。然而,共享文件的内容还可以是纷繁复杂的,任意的字节数据(例如一个电影)都可以,这使得文件共享变成了一个非常灵活的 IPC 机制。但它的缺点是文件获取速度较慢,因为文件的获取涉及到读或者写。同往常一样,编程总是伴随着折中。下面的例子将通过共享内存来做 IPC,而不是通过共享文件,在性能上相应的有极大的提升。
共享内存
对于共享内存,Linux 系统提供了两类不同的 API:传统的 System V API 和更新一点的 POSIX API。在单个应用中,这些 API 不能混用。但是,POSIX 方式的一个坏处是它的特性仍在发展中,并且依赖于安装的内核版本,这非常影响代码的可移植性。例如,默认情况下,POSIX API 用内存映射文件来实现共享内存:对于一个共享的内存段,系统为相应的内容维护一个备份文件。在 POSIX 规范下共享内存可以被配置为不需要备份文件,但这可能会影响可移植性。我的例子中使用的是带有备份文件的 POSIX API,这既结合了内存获取的速度优势,又获得了文件存储的持久性。
下面的共享内存例子中包含两个程序,分别名为 memwriter 和 memreader,并使用信号量来调整它们对共享内存的获取。在任何时候当共享内存进入一个写入者场景时,无论是多进程还是多线程,都有遇到基于内存的竞争条件的风险,所以,需要引入信号量来协调(同步)对共享内存的获取。
memwriter 程序应当在它自己所处的终端首先启动,然后 memreader 程序才可以在它自己所处的终端启动(在接着的十几秒内)。memreader 的输出如下:
This is the way the world ends...
- 1.
在每个源程序的最上方注释部分都解释了在编译它们时需要添加的链接参数。
首先让我们复习一下信号量是如何作为一个同步机制工作的。一般的信号量也被叫做一个计数信号量,因为带有一个可以增加的值(通常初始化为 0)。考虑一家租用自行车的商店,在它的库存中有 100 辆自行车,还有一个供职员用于租赁的程序。每当一辆自行车被租出去,信号量就增加 1;当一辆自行车被还回来,信号量就减 1。在信号量的值为 100 之前都还可以进行租赁业务,但如果等于 100 时,就必须停止业务,直到至少有一辆自行车被还回来,从而信号量减为 99。
二元信号量是一个特例,它只有两个值:0 和 1。在这种情况下,信号量的表现为互斥量(一个互斥的构造)。下面的共享内存示例将把信号量用作互斥量。当信号量的值为 0 时,只有 memwriter 可以获取共享内存,在写操作完成后,这个进程将增加信号量的值,从而允许 memreader 来读取共享内存。
示例 3. memwriter 进程的源程序
/** Compilation: gcc -o memwriter memwriter.c -lrt -lpthread **/#include <stdio.h>#include <stdlib.h>#include <sys/mman.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>#include <semaphore.h>#include <string.h>#include "shmem.h"-
void report_and_exit(const char* msg) { [perror][4](msg); [exit][5](-1);}-
int main() { int fd = shm_open(BackingFile, /* name from smem.h */ O_RDWR | O_CREAT, /* read/write, create if needed */ AccessPerms); /* access permissions (0644) */ if (fd < 0) report_and_exit("Can't open shared mem segment...");-
ftruncate(fd, ByteSize); /* get the bytes */-
caddr_t memptr = mmap(NULL, /* let system pick where to put segment */ ByteSize, /* how many bytes */ PROT_READ | PROT_WRITE, /* access protections */ MAP_SHARED, /* mapping visible to other processes */ fd, /* file descriptor */ 0); /* offset: start at 1st byte */ if ((caddr_t) -1 == memptr) report_and_exit("Can't get segment...");-
[fprintf][7](stderr, "shared mem address: %p [0..%d]\n", memptr, ByteSize - 1); [fprintf][7](stderr, "backing file: /dev/shm%s\n", BackingFile );-
/* semahore code to lock the shared mem */ sem_t* semptr = sem_open(SemaphoreName, /* name */ O_CREAT, /* create the semaphore */ AccessPerms, /* protection perms */ 0); /* initial value */ if (semptr == (void*) -1) report_and_exit("sem_open");-
[strcpy][8](memptr, MemContents); /* copy some ASCII bytes to the segment */-
/* increment the semaphore so that memreader can read */ if (sem_post(semptr) < 0) report_and_exit("sem_post");-
sleep(12); /* give reader a chance */-
/* clean up */ munmap(memptr, ByteSize); /* unmap the storage */ close(fd); sem_close(semptr); shm_unlink(BackingFile); /* unlink from the backing file */ return 0;}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
下面是 memwriter 和 memreader 程序如何通过共享内存来通信的一个总结:
-
上面展示的
memwriter程序调用shm_open函数来得到作为系统协调共享内存的备份文件的文件描述符。此时,并没有内存被分配。接下来调用的是令人误解的名为ftruncate的函数ftruncate(fd, ByteSize); /* get the bytes */
- 1.
它将分配
ByteSize字节的内存,在该情况下,一般为大小适中的 512 字节。memwriter和memreader程序都只从共享内存中获取数据,而不是从备份文件。系统将负责共享内存和备份文件之间数据的同步。 -
接着
memwriter调用mmap函数:caddr_t memptr = mmap(NULL, /* let system pick where to put segment */ByteSize, /* how many bytes */PROT_READ | PROT_WRITE, /* access protections */MAP_SHARED, /* mapping visible to other processes */fd, /* file descriptor */0); /* offset: start at 1st byte */
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
来获得共享内存的指针。(
memreader也做一次类似的调用。) 指针类型caddr_t以c开头,它代表calloc,而这是动态初始化分配的内存为 0 的一个系统函数。memwriter通过库函数strcpy(字符串复制)来获取后续写操作的memptr。 -
到现在为止,
memwriter已经准备好进行写操作了,但首先它要创建一个信号量来确保共享内存的排斥性。假如memwriter正在执行写操作而同时memreader在执行读操作,则有可能出现竞争条件。假如调用sem_open成功了:sem_t* semptr = sem_open(SemaphoreName, /* name */O_CREAT, /* create the semaphore */AccessPerms, /* protection perms */0); /* initial value */
- 1.
- 2.
- 3.
- 4.
那么,接着写操作便可以执行。上面的
SemaphoreName(任意一个唯一的非空名称)用来在memwriter和memreader识别信号量。初始值 0 将会传递给信号量的创建者,在这个例子中指的是memwriter赋予它执行写操作的权利。 -
在写操作完成后,
memwriter* 通过调用sem_post` 函数将信号量的值增加到 1:if (sem_post(semptr) < 0) ..
- 1.
增加信号了将释放互斥锁,使得
memreader可以执行它的读操作。为了更好地测量,memwriter也将从它自己的地址空间中取消映射,munmap(memptr, ByteSize); /* unmap the storage *
- 1.
这将使得
memwriter不能进一步地访问共享内存。
示例 4. memreader 进程的源代码
/** Compilation: gcc -o memreader memreader.c -lrt -lpthread **/#include <stdio.h>#include <stdlib.h>#include <sys/mman.h>#include <sys/stat.h>#include <fcntl.h>#include <unistd.h>#include <semaphore.h>#include <string.h>#include "shmem.h"-
void report_and_exit(const char* msg) { [perror][4](msg); [exit][5](-1);}-
int main() { int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* empty to begin */ if (fd < 0) report_and_exit("Can't get file descriptor...");-
/* get a pointer to memory */ caddr_t memptr = mmap(NULL, /* let system pick where to put segment */ ByteSize, /* how many bytes */ PROT_READ | PROT_WRITE, /* access protections */ MAP_SHARED, /* mapping visible to other processes */ fd, /* file descriptor */ 0); /* offset: start at 1st byte */ if ((caddr_t) -1 == memptr) report_and_exit("Can't access segment...");-
/* create a semaphore for mutual exclusion */ sem_t* semptr = sem_open(SemaphoreName, /* name */ O_CREAT, /* create the semaphore */ AccessPerms, /* protection perms */ 0); /* initial value */ if (semptr == (void*) -1) report_and_exit("sem_open");-
/* use semaphore as a mutex (lock) by waiting for writer to increment it */ if (!sem_wait(semptr)) { /* wait until semaphore != 0 */ int i; for (i = 0; i < [strlen][6](MemContents); i++) write(STDOUT_FILENO, memptr + i, 1); /* one byte at a time */ sem_post(semptr); }-
/* cleanup */ munmap(memptr, ByteSize); close(fd); sem_close(semptr); unlink(BackingFile); return 0;}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
memwriter 和 memreader 程序中,共享内存的主要着重点都在 shm_open 和 mmap 函数上:在成功时,***个调用返回一个备份文件的文件描述符,而第二个调用则使用这个文件描述符从共享内存段中获取一个指针。它们对 shm_open 的调用都很相似,除了 memwriter 程序创建共享内存,而 `memreader 只获取这个已经创建的内存:
int fd = shm_open(BackingFile, O_RDWR | O_CREAT, AccessPerms); /* memwriter */int fd = shm_open(BackingFile, O_RDWR, AccessPerms); /* memreader */
- 1.
- 2.
有了文件描述符,接着对 mmap 的调用就是类似的了:
caddr_t memptr = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
- 1.
mmap 的***个参数为 NULL,这意味着让系统自己决定在虚拟内存地址的哪个地方分配内存,当然也可以指定一个地址(但很有技巧性)。MAP_SHARED 标志着被分配的内存在进程中是共享的,***一个参数(在这个例子中为 0 ) 意味着共享内存的偏移量应该为***个字节。size 参数特别指定了将要分配的字节数目(在这个例子中是 512);另外的保护参数(AccessPerms)暗示着共享内存是可读可写的。
当 memwriter 程序执行成功后,系统将创建并维护备份文件,在我的系统中,该文件为 /dev/shm/shMemEx,其中的 shMemEx 是我为共享存储命名的(在头文件 shmem.h 中给定)。在当前版本的 memwriter 和 memreader 程序中,下面的语句
shm_unlink(BackingFile); /* removes backing file */
- 1.
将会移除备份文件。假如没有 unlink 这个语句,则备份文件在程序终止后仍然持久地保存着。
memreader 和 memwriter 一样,在调用 sem_open 函数时,通过信号量的名字来获取信号量。但 memreader 随后将进入等待状态,直到 memwriter 将初始值为 0 的信号量的值增加。
if (!sem_wait(semptr)) { /* wait until semaphore != 0 */
- 1.
一旦等待结束,memreader 将从共享内存中读取 ASCII 数据,然后做些清理工作并终止。
共享内存 API 包括显式地同步共享内存段和备份文件。在这次的示例中,这些操作都被省略了,以免文章显得杂乱,好让我们专注于内存共享和信号量的代码。
即便在信号量代码被移除的情况下,memwriter 和 memreader 程序很大几率也能够正常执行而不会引入竞争条件:memwriter 创建了共享内存段,然后立即向它写入;memreader 不能访问共享内存,直到共享内存段被创建好。然而,当一个写操作处于混合状态时,***实践需要共享内存被同步。信号量 API 足够重要,值得在代码示例中着重强调。
总结
上面共享文件和共享内存的例子展示了进程是怎样通过共享存储来进行通信的,前者通过文件而后者通过内存块。这两种方法的 API 相对来说都很直接。这两种方法有什么共同的缺点吗?现代的应用经常需要处理流数据,而且是非常大规模的数据流。共享文件或者共享内存的方法都不能很好地处理大规模的流数据。按照类型使用管道会更加合适一些。所以这个系列的第二部分将会介绍管道和消息队列,同样的,我们将使用 C 语言写的代码示例来辅助讲解。