一般来说,白盒与黑盒分别从内部和外部来监控系统的运行状况,例如机器存活、CPU内存使用率、业务日志、JMX等监控都属于白盒监控,而外部端口探活、HTTP探测以及端到端功能监控等则属于黑盒监控的范畴。
下面将主要从白盒监控的采集入手,解答上面关于新系统如何添加监控的问题。
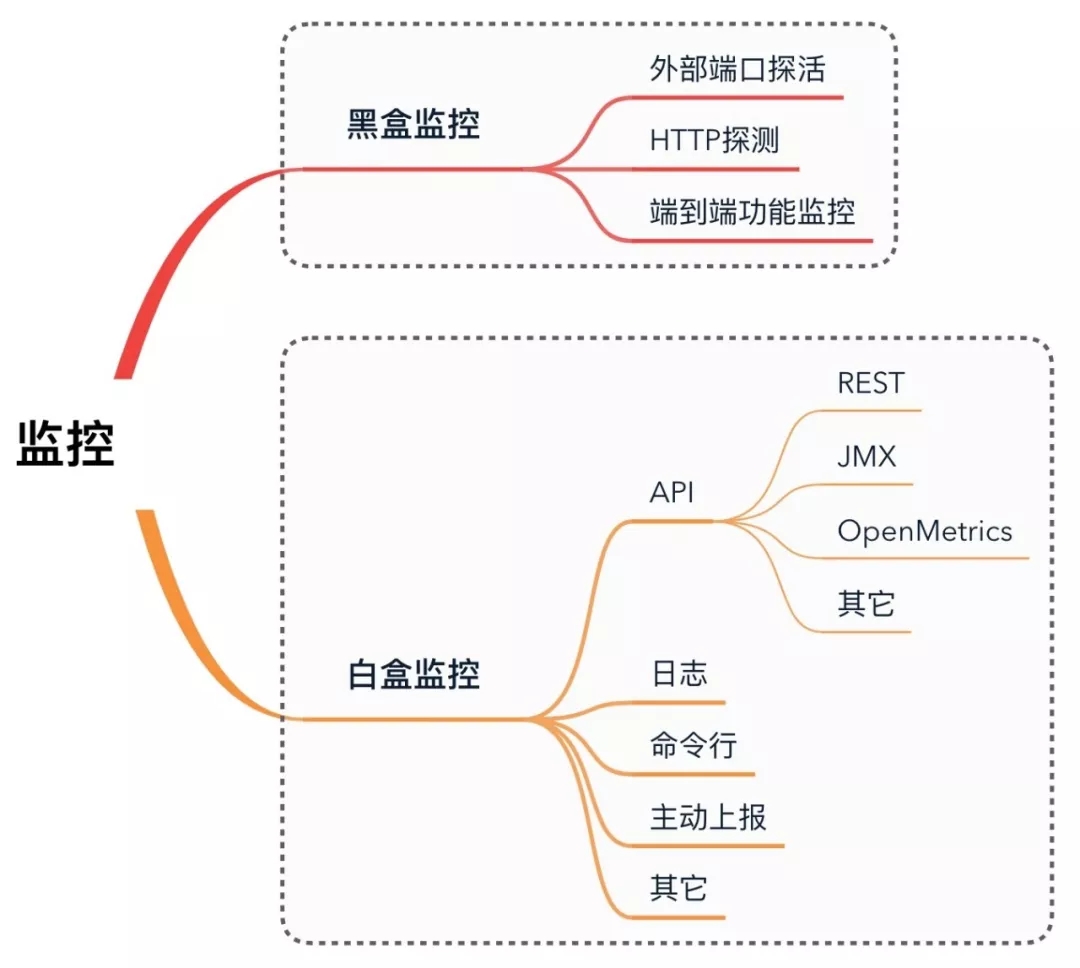
图 1 黑盒与白盒监控
监控指标的采集
配置监控时,我们首要面对的是监控数据如何采集的问题。一般我们可以把监控指标分为两类:基础监控和业务监控。
基础监控
包括CPU、内存、磁盘、端口和进程等机器、网络的操作系统级别的信息。通常情况下,成熟的监控系统(例如开源的Prometheus、Zabbix等)均会提供基础监控项的采集能力,这里不做过多介绍。但需要注意的一点,机器级别的基础监控指标一般并不能代表服务的真实运行状况,例如单台实例的故障对一个设计合理的分布式系统来说并不会带来严重后果。所以只有结合业务相关监控指标,基础监控指标才有意义。
业务监控
业务监控指标由业务系统内部的服务产生,一般能够真实反应业务运行状态。设计合理的系统一般都会提供相关监控指标供监控系统采集。监控数据的采集方法一般可以分为以下几大类:
- 日志:日志可以包含服务运行的方方面面,是重要的监控数据来源。例如,通过Nginx access日志可以统计出错误(5xx)、延迟(响应时间)和流量,结合已知的容量上限就可以计算出饱和度。一般除监控系统提供的日志采集插件外,如Rsyslog、Logstash、Filebeat、Flume等都是比较优秀的日志采集软件
- JMX:多数Java开发的服务均可由JMX接口输出监控指标。不少监控系统也有集成JMX采集插件,除此之外我们也可通过jmxtrans、jmxcmd工具进行采集
- REST:提供REST API来进行监控数据的采集,如Hadoop、ElasticSearch
- OpenMetrics:得益于Prometheus的流行,作为Prometheus的监控数据采集方案,OpenMetrics可能很快会成为未来监控的业界标准。目前绝大部分热门开源服务均有官方或非官方的exporter可供使用
- 命令行:一些服务提供本地的命令来输出监控指标
- 主动上报:对于采用PUSH模型的监控系统来说,服务可以采取主动上报的方式把监控指标push到监控系统,如Java服务可使用Metrics接口自定义sink输出。另外,运维也可以使用自定义的监控插件来完成监控的采集
- 埋点:埋点是侵入式的监控数据采集方式,其优点是其可以更灵活地为我们提供业务内部的监控指标,当然缺点也很明显:需要在代码层面动手脚(常常需要研发支持,成本较高)
- 其它方式:以上未涵盖的监控指标采集方式,例如Zookeeper的四字命令,MySQL的show status命令
以上列出了几种常见的监控指标采集方法,在实际工作,如果没有现成的监控采集插件,则需要我们自行开发采集脚本。
四个黄金指标
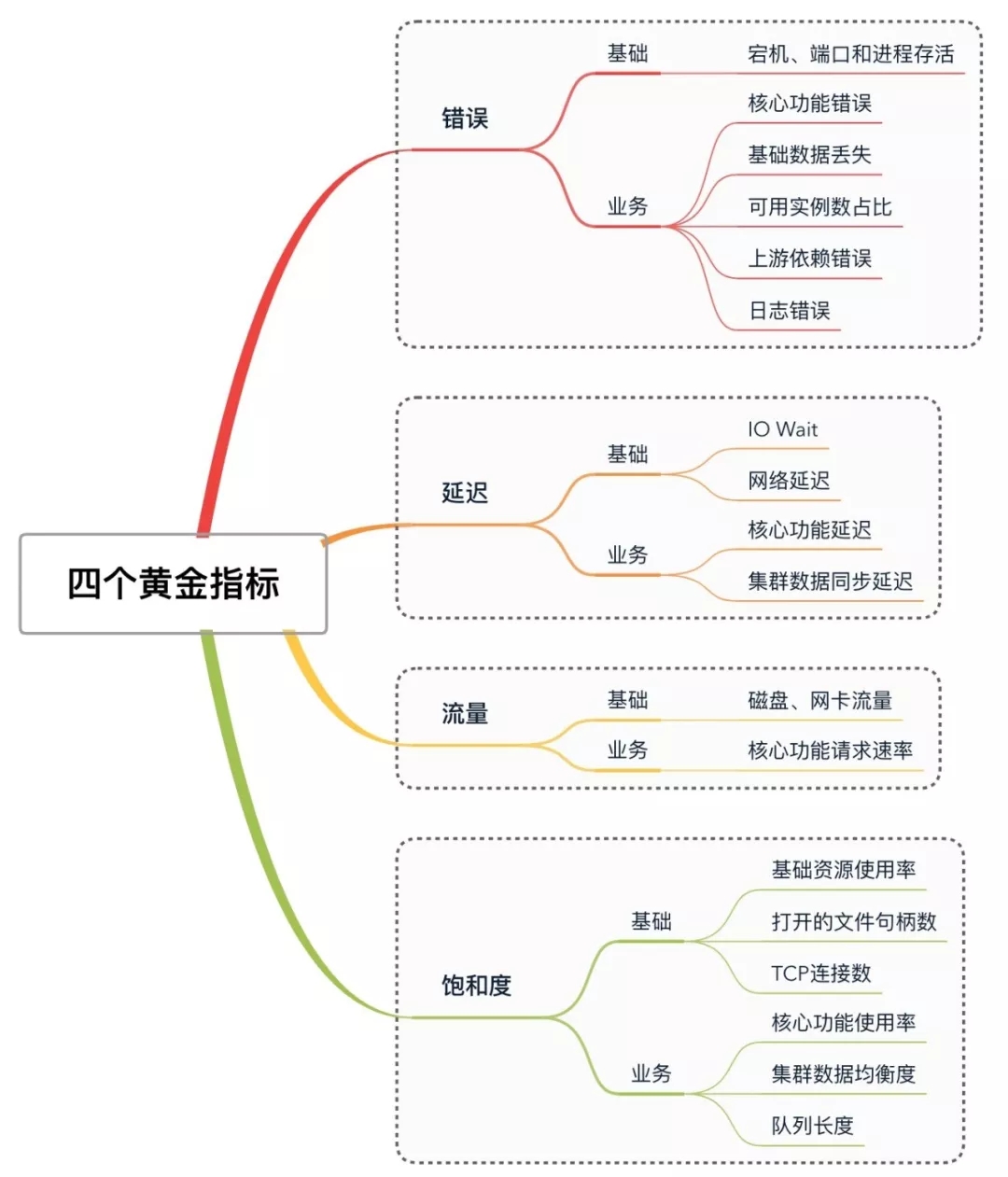
图 2 四个黄金指标
无论业务系统如何复杂,监控指标如何眼花缭乱,但万变不离其宗,监控的目的无非是为了解服务运行状况、发现服务故障和帮助定位故障原因。为了达成这个目的,Google SRE总结的监控四个黄金指标对我们添加监控具有非常重要的指导意义。图 2给出四个黄金指标所包含的主要监控指标,下面我们就这四个黄金指标分别展开说明,并给出一些监控项的采集实例。
错误:错误是指当前系统发生的错误请求
和错误率
说明:
错误是需要在添加监控时首要关注的指标。在添加错误相关监控时,我们应该关注以下几个方面:
基础监控:宕机、磁盘(坏盘或文件系统错误)、进程或端口挂掉、网络丢包等故障
业务监控:
- 核心功能处理错误,每种系统都有特定的核心功能,比如HDFS的文件块读写、Zookeeper对Key的读写和修改操作
- 基础功能单元丢失或异常,这里的基础功能单元是指一个系统功能上的基本单位,例如HDFS的Block、Kafka的Message,这种基础数据的丢失一般都会对业务功能造成直接的影响
- Master故障,对于中心化的分布式系统来说,Master的健康状况都是重中之重。例如HDFS的NameNode、Zookeeper的Leader,ElasticSearch的MasterNode
- 可用节点数,对于分布式系统来说,可用节点数也是非常重要的,比如Zookeeper、ETCD等系统需要满足可用节点数大于不可用节点数才能保证功能的正常
注意:除白盒监控外,主要功能或接口、以及内部存在明显边界的功能模块和上游依赖模块,都应该添加黑盒端到端监控。
延迟:服务请求所需时间
说明:
服务延迟的上升不仅仅体现在用户体验的下降,也有可能会导致请求堆积并最终演变为整个业务系统的雪崩。以下为延迟指标的主要关注点:
- 基础监控:IO等待、网络延迟
- 业务监控:业务相关指标主要需要关注核心功能的响应时长。比如Zookeeper的延迟指标zk_avg_latency,ElasticSearch的索引、搜索延迟和慢查询
注意:与错误指标类似,白盒延迟指标通常仅能代表系统内部延迟,建议为主要功能或接口添加黑盒监控来采集端到端的延迟指标。
流量:当前系统的流量
说明:
流量指标可以指系统层面的网络和磁盘IO,服务层面的QpS、PV和UV等数据。流量和突增或突减都可能预示着系统可能出现问题。
- 基础监控:磁盘和网卡IO
- 业务监控:核心功能流量,例如通过QpS/PV/UV等通常能够代表Web服务的流量,而ElasticSearch的流量可用索引创建速率、搜索速率表示
饱和度:用于衡量当前服务的利用率
说明:
更为通俗的讲,饱和度可以理解为服务的利用率,可以代表系统承受的压力。所以饱和度与流量息息相关,流量的上升一般也会导致饱和度的上升。通常情况下,每种业务系统都应该有各自的饱和度指标。在很多业务系统中,消息队列长度是一个比较重要的饱和度指标,除此之外CPU、内存、磁盘、网络等系统资源利用率也可以作为饱和度的一种体现方式。
基础监控:CPU、内存、磁盘和网络利用率、内存堆栈利用率、文件句柄数、TCP连接数等
业务监控:
- 基础功能单元使用率,大多数系统对其基础的功能单元都有其处理能力的上限,接近或达到该上限时可能会导致服务的错误、延迟增大。例如HDFS的Block数量上升会导致NameNode堆内存使用率上升,Kafka的Topics和Partitions的数量、Zookeeper的node数的上升都会对系统产生压力
- 消息队列长度,不少系统采用消息队列存放待处理数据,所以消息队列长度在一定程度上可以代表系统的繁忙程度。如ElasticSearch、HDFS等都有队列长度相关指标可供采集
总结
以上总结了常见的监控指标采集方法,以及四个黄金指标所包含的常见内容。在实际工作中,不同的监控系统的设计多种多样,没有统一标准,并且不同的业务系统通常也有着特定的监控采集方法和不同的黄金指标定义,具体如何采集监控指标和添加告警都需要我们针对不同系统特点灵活应对。
本期作者:葫芦瓜
京东云 应用研发部
在前面的监控系列文章中,我们介绍了Kafka、Zookeeper、ElasticSearch、Hadoop以及电商平台等一系列开源软件和业务系统的监控实践。但通常情况下,线上业务一般是由众多开源或自研中间件加上层业务系统组成。而业务系统的复杂度会随着系统变更和新业务上线而发生快速增长。不断变化的业务环境下,新业务层出不穷。当面临一个新系统时,监控工作应该如何开展?
【本文为51CTO专栏作者“京东云”的原创稿件,转载请通过作者微信公众号JD-jcloud获取授权】