【51CTO.com原创稿件】推荐系统自从问世以来解决了许多不同的商业产品问题,深受广大互联网从业者的喜爱。传统的互联网电商公司像阿里巴巴和京东已经把推荐系统当成了自己的核心技术资产之一,而新兴的互联网产品像今日头条和抖音,也早已把推荐系统作为了自己的技术立足之本。然而伴随着推荐系统的蓬勃发展,一些推荐系统在技术上的挑战和困难却总是挥之不去。
在优化算法的过程中,工程师总是强调分析数据进一步提高算法性能。但是对于一些老大难问题怎样分析数据,业内目前还没有一些较为全面和体系化的方法论。2018年在成都举行的 ICCCBDA 2018 会议刊登了一篇题为 Quantitative Analysis of Matthew Effect and Sparsity Problem in Recommender Systems 的论文,尝试着精准量化协同过滤算法中的两个常见难题:马太效应和稀疏性问题。
协同过滤是推荐系统最基本的方法。虽然如今推荐系统已经是深度学习的各种算法像 DeepFM 等的天下,但是一些基本的推荐系统的方法仍然是被用作 baseline 的工具。并且在一些并不具备深度学习能力的企业,协同过滤仍然是流行的算法。
协同过滤面临的两个主要挑战,一个是马太效应,另一个是数据稀疏性问题。马太效应是指在协同过滤的相似性计算中与某个物品相似的物品数量极大,导致这个物品对所有的物品都有影响。另外马太效应会导致数据分布不均衡,直接造成在 MapReduce 计算的过程中效率低下。而数据稀疏性问题指的是有的用户对应的物品过少或者有的物品对应的用户过少,导致算法的计算结果覆盖率很低。研究界和工业界针对这两个问题提出了很多不同的算法意图解决相应问题。但是在 ICCCBDA 2018 的论文之前,并没有人明确的用数学公式对这两个问题进行量化,以方便数据分析和算法的进一步优化。
作者用相似度的期望值来衡量协同过滤中的马太效应,而用相似度计算中关联的用户/物品数来衡量协同过滤中的稀疏性问题。因为推荐系统的应用场景大部分是长尾物品,作者假设了物品的分布服从 Zipf’s Law,也就是热度排名第 i 位的物品的分布占比是 1/i。利用组合数学的方法,我们可以得到一系列的公式。推导过程论文中有详细的记载。最终的推导结果如下:
针对于基于用户的协同过滤的马太效应,我们有用户 A 和用户 B 的平均期望为:
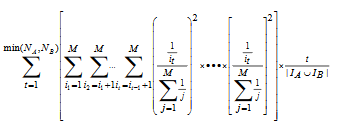
针对基于物品的协同过滤的马太效应,我们有用户 A 和用户 B 的平均期望为:
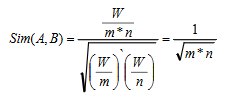
针对基于用户的协同过滤的稀疏性问题,参与相似性计算的物品数量期望为:
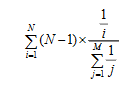
针对基于物品的协同过滤的稀疏性问题,参与相似度计算的物品数量期望为:
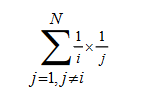
作者随后进行了实验,对于推导的公式进行了验证:

上图显示的是基于物品的协同过滤的稀疏性在真实数据集合 LastFM 中的分布,与公式中的马太效应基本吻合。
本文的数学公式推导过程以及整个的数据分析思路并不复杂。主要贡献在于***提出了量化推荐系统马太效应和数据稀疏性的方法,使得系统化的解决这两个问题成为可能。
汪昊,区块链公司科学家,前恒昌利通大数据部负责人,美国犹他大学本科/硕士,在百度,新浪,网易,豆瓣等公司有多年的研发和技术管理经验,擅长机器学习,大数据,推荐系统,社交网络分析等技术。在 TVCG 和 ASONAM 等国际会议和期刊发表论文 10 篇。本科毕业论文获国际会议 IEEE SMI 2008 ***论文奖。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】