代码的 Bug 到底与什么有关?代码的行数?项目的规模?还是开发者的人数?在本文中,将基于机器学习模型绘制的图形,告诉你诸多 Bug 的由来!
以下为译文:
怎样才能减少软件中的Bug?本文将告诉你传统观点是错误的,下列数据会让你感到惊讶。
软件开发人员普遍认为,代码量越大Bug就越多。虽然许多人并不是很清楚这两者之间的确切关系,但他们认为二者是线性的关系,即每千行代码中的Bug数与代码量成正比。然而,根据对GitHub中10万个代码库的研究发现,代码行数与Bug之间并不存在这种恒定的关系。而且,代码行数并不是Bug数的可靠指标。
注:在本文中,我用“bug”来指代软件中从一些从用户的角度来看的异常行为,例如:死机、视觉异常、不正确的数据等。“Bug”也常用于描述软件中可利用的缺陷,但这是从黑客的角度来看。本文不涉及安全漏洞,因为安全漏洞可能需要别的模型来分析。
相反,我们发现了两个更可靠的指标:贡献代码的开发人员数量和提交代码的次数。本文中的图片使用了一个拥有两个变量的模型,而且这个模型在预测Bug数目时,与我另一个拥有16个变量的模型表现几乎相同。我会详细解释这些模型的建模过程,但是首先:
如果存在这种因果关系,那么这对减少Bug意味着什么?
如果你需要可靠的软件,那么请不要使用会产生Bug的方法论。例如,敏捷主张直接写代码,然后通过迭代这些代码来优化需求,所以会产生很多提交(而提交次数与bug数息息相关)。
原型可以减少bug,但是你必须在使用完后丢弃这些原型。你需要通过数次提交来学习技术和客户的需求,然后编写一个非原型版本,其中包含更少量的提交次数和/或更小的团队。
刻意保障系统可靠性的工作可能会产生相反的效果。在采用测试驱动的开发和单元测试的情况下,如果提交的代码次数,或需要的开发人员的话,那么bug数也会,这可能与你的直觉恰恰相反。
对于个人而言,你应该将时间花费在写代码之外的事情上,例如思考、设计、和制作原型等等。
对于企业而言,雇佣的开发人员数量越少越好,当然开发人员的经验越多越好。
收集数据
首先,我通过GitHub API,查询了10万个项目(超过135颗星的项目)。这些项目并不是随机抽样,它们占据了GitHub上高端0.1%,所以我们更加自信会有很多人发现和报告bug。对于每个项目,我提取了项目的创建日期(GitHub上的日期),给星数量,问题数量,提交PR的次数,以及issue tracker是否被禁用。
接下来,我克隆了所有非私有的代码库,并直接从Git和文件系统收集了以下统计信息:

我针对每个代码库的HEAD信息,收集了Tokei的统计信息:每种检测到的语言的代码行数、注释、空格等等。然后,对于每种Tokei检测到的语言,我计算了总字节数和LZMA压缩后的字节数。
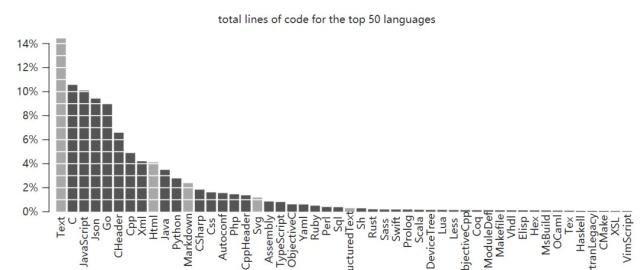
排名前50的总代码行数。被排除的语言(文本和标记)用灰色显示(Text、Html、Markdown、Sg、ReStructuredText)
控制受欢迎度等差异
我们以为,旧项目和受欢迎项目的平均bug数会更偏高。为了控制这些差异以及其他差异,我使用了如下模型:
ln(issues) = β1created age + β2first commit age + β3ln(stars) + β4ln(contributors) + β5ln(all commits) +β6ln(code) + β7ln(comments + 1) + β8ln(pull requests + 1) + β9ln(files) + ε
我通过这个模型做了拟合,并通过10折交叉验证测试了模型与线性回归的拟合度,然后在一个组合图中绘制了每个折叠的预测误差。在此之前,我删除了所有私有、归档、镜像和分叉项目,没有启用issue tracker的项目,以及数据集中bug数为零的项目。
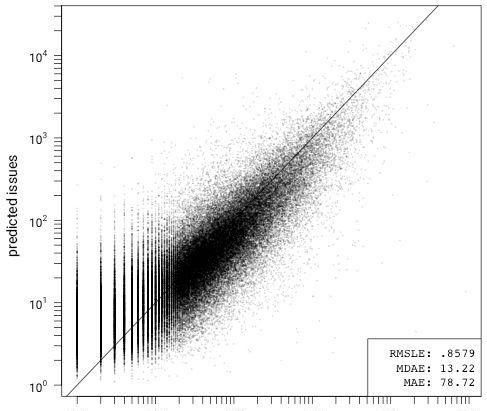
9个变量模型的预测误差
这个模型有一些偏差,但其他方面的拟合度还不错。它高估了GitHub上问题数量很少(<10)的项目的bug数(相反低估了问题数量偏高的项目)。我怀疑这是由于github的api中没有将分叉项目标记出来,还有一些包含第三方代码的项目导致的。这些项目夸大了与issue>
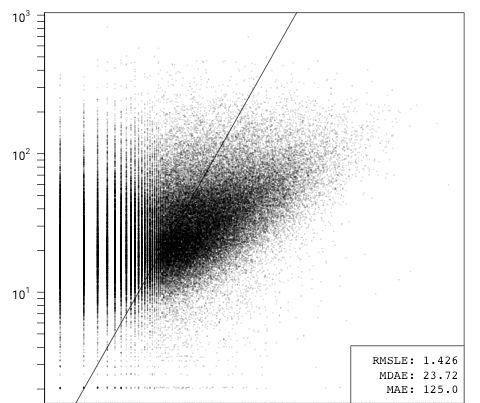
ln(issues) = β1ln(code) + ε
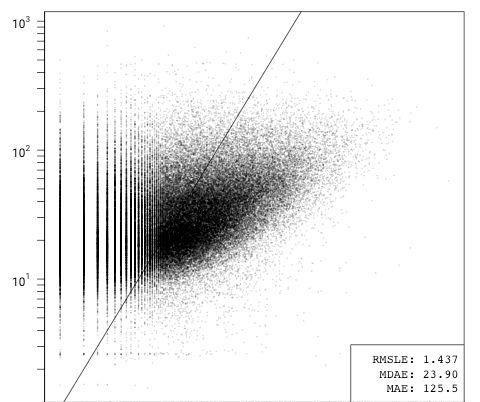
ln(issues) = β1ln(lzma bytes) + ε
仅包含代码行或lzma压缩的代码字节的模型(说明了语言之间代码密度的差异)表现同样糟糕。
用9个变量的模型拟合完整的数据集后,得出了以下近似值:
ln(issues) = 0.022created age – 0.017first commit age + 0.315ln(stars) + 0.071ln(contributors) + 0.266ln(all commits) +0.072ln(code) + 0.034ln(comments + 1) + 0.413ln(pull requests + 1) – 0.069ln(files) – 1.690
我们可以看出,模型中的主导变量是PR数(0.413)、给星数(0.315)和提交次数(0.266)。将这二者与代码行数(0.072)和注释(0.034)相比较,就会发现这些差异更加明显,尤其是再考虑到变量尚未规范化,而且几乎所有项目中代码行数都会高于PR数、给星数或提交次数。
由于PR数和给星数是GitHub特有的功能,我还构建了一个没有这两个数据项的模型。然后,根据拟合模型的系数,再进一步将其简化为只包含提交代码的人数和提交次数。这种只有3个变量的模型的表现几乎与其他模型完全相同,而且还可以显示成3G图形:
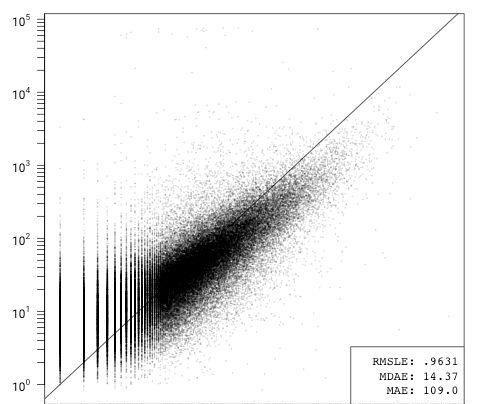
ln(issues) = β1first commit age + β2ln(contributors) + β3ln(all commits) + β4ln(code) + β5ln(comments + 1) + β6ln(files) + ε
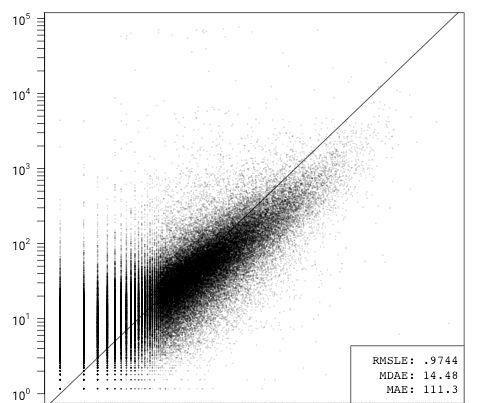
ln(issues) = β1ln(contributors) + β2ln(all commits) + ε
在删除了GitHub特有的数据项后,提交代码的人数和提交次数就占据了主导地位,从删除所有其他变量时错误数轻微的减少就可以看出。
会不会是这个模型搞错了?
现在我们知道了提交代码的人数和提交次数的影响,下面我们来看看,如果不采用任何根据提交代码的人数和提交次数绘制图形的模型,那么代码行数与问题数量之间有何关系。
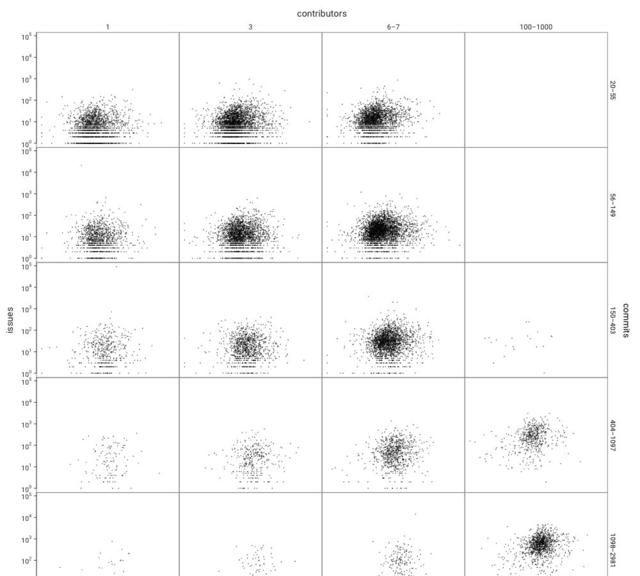
针对GitHub,绘制代码行数(x轴)与GitHub上的问题数(y轴)的关系图,并根据提交代码的人数和提交次数分组。
为了节省空间,我没有显示所有的10万个项目。我按照提交代码的人数和提交次数进行了分组,因为我觉得这种分组方式最有意思,且具代表性。为了避免选择偏差,我只在选择分组之后进行绘图。
你只看到了一团团杂乱的点,对吧?这就对了:上图证实了代码行数与bug数之间的关联性非常弱。而且请记住,这些图是用对数绘制的,而且这个模型使用的是ln(code)(代码行数的对数):因为相关性会随着代码行数的大小而变化。
随着代码行数的增加,bug数却增长缓慢
我见过有人说每千行代码的bug数在0.5-50个。但是我发现得出这样的结论的人只研究了1-2个成熟的软件项目在某一个时间点或两个版本之间的代码。只查看某个项目在一个时间点的快照,凭什么认为这个项目在早期或后期的情况会保持不变?
根据上述数据,认为bug数和代码行数之间存在任何常量的关系是不明智的。相反,我们应该认识到bug数目增长的速度会随着项目的成熟而越来越慢。原因是了什么?我认为:
我们观察到的频率呈对数分布,而不是正常分布。一小部分bug能被更快、更频繁地发现,而系统中处于“长尾”的bug发现速度和频率要低得多。
bug数量与功能数有关,而跟代码行数无关,而代码行数与功能数呈超线性分布。(随着项目的增长,添加新功能所需的代码行数会增加。)
项目的核心应该随着时间的推移变得更加稳定,因为我们会修复bug,但不会做出重大改变。随着项目的成熟,新来的开发人员不太可能改动关键的代码,而且新功能的开发需要的核心变化更少。
那么哪些不是问题的bug和不是bug的问题呢?
对于这种大小和范围的研究,GitHub的issue是我所知道的记录bug的形式。自动bug检测软件仅适用于某些语言,而且只能检测到“结构性”的bug(比如无效的内存访问),而却无法检测到逻辑错误(例如错误的计算),而且手动统计bug数是不切实际的(或者根本不可能)。我们必须假设处于开放状态的issue能够代表用户遇到的bug数。
异常值和替代假设
在查看这些数据之前,我没有猜到仅靠提交代码的人数就可以预测bug数。这表明项目的开发人员数量蕴含了有关项目的其他大量信息。一种合理的解释是“大型开发团队有向平均数回归的趋势”:即随着团队开发人员数量的增加,项目的提交次数/功能/代码行数与开发人数的比率倾向于一个平均值。
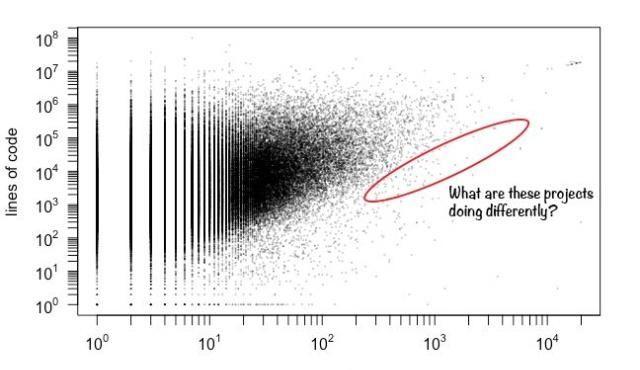
随着开发人员数量的增加,代码行数的范围变窄。
在浏览异常值时,我遇到了一个特别有趣的类别:游戏机模拟器。该类软件拥有测试输入(游戏),测试人员(游戏玩家)和其他实现(其他模拟器和系统本身)等数据,可以为将来的软件bug数的比较研究提供更加可控的实验环境。