我们在今年2月跨越了YugaByte DB三年开发阶段,到目前为止,这是一段惊心动魄的旅程,但并非没有公平的技术挑战。有时我们不得不回到绘图板,甚至筛选学术研究,以找到比我们手头的更好的解决方案,在这篇文章中,我们将概述在构建开源,云原生,高性能分布式SQL数据库的过程中我们必须解决的一些最难的架构问题。
好的,让我们开始探讨从最简单到***挑战性的问题:
1.架构:亚马逊Aurora还是谷歌Spanner?
我们早期做出的一个决定是找到一个我们可以用作YugaByte DB架构灵感的数据库。我们密切关注两个系统,Amazon Aurora和Google Spanner。
Amazon Aurora是一个提供高可用性的SQL数据库。它具有与流行的RDBMS数据库(如MySQL和PostgreSQL)的兼容性,使其易于入门并可运行各种应用程序。Amazon Aurora也是AWS历史上发展最快的服务之一。
Amazon Aurora服务与MySQL和PostgreSQL兼容,是AWS历史上发展最快的服务。
Amazon Aurora具有可扩展的数据存储层,但查询层不是这样。以下是我们发现的Amazon Aurora的一些关键可扩展性限制:
- 写入不是水平可伸缩的。扩展写入吞吐量的唯一方法是垂直扩展处理所有写入的节点(称为主节点)。这种扩展方案只是到目前为止,因此数据库能处理多少写入IOPS存在固有的限制。
- 写入不是全局一致的。许多现代的云原生应用程序本质上是全局性的,需要跨多个区域部署底层数据库。但是,Aurora仅支持多主机部署,在发生冲突时***一个写入程序(具有***时间戳)获胜。这可能导致不一致。
- 通过使用牺牲一致性的从属副本以获得读取的伸缩扩展。为了扩展读取,应用程序需要连接到从属节点才能实现读取。当使用这些从属节点实现读取时,应用程序需要面对降级的一致性语义,以及一个单独的连接端点。这使得应用程序架构非常复杂。
另外,Google Spanner是一个可水平扩展的SQL数据库,专为大规模可扩展和地理分布式应用程序而构建。
Cloud Spanner是唯一为云构建的企业级、全局分布且高度一致的数据库服务,专门用于将关系数据库结构的优势与非关系水平扩展相结合。
这意味着Spanner可以无缝扩展读写,支持需要全局一致性的地理分布式应用程序,并在不牺牲正确性的情况下从多个节点执行读取。
但是,它放弃了RDBMS数据库提供给开发人员期望的许多熟悉功能集。例如,Google Spanner文档中突出显示了不支持外键约束或触发器的事实。
我们决定采用混合方法。
- YugaByte DB的核心存储架构受到Google Spanner的启发,该架构专为水平可扩展性和地理分布式应用程序而构建。
- YugaByte DB保留了与Amazon Aurora类似的PostgreSQL兼容查询层,它可以支持丰富的功能集,并支持最广泛的用例。
2. SQL协议:PostgreSQL还是MySQL?
我们想要对广泛采用的SQL方言进行标准化。我们还希望它是开源的,并且在数据库周围拥有成熟的生态系统。权衡的自然选择是PostgreSQL和MySQL?
我们之所以选择PostgreSQL(而不是MySQL),原因如下:
- PostgreSQL有一个更宽松的许可证,更符合YugaByte DB的开源精神。
- 与任何其他SQL数据库相比,PostgreSQL在过去几年中的流行度一直在飙升,这绝对没有受到影响!
在目前排在DB-Engines排名网站前10位的五个SQL数据库中,自2014年以来,只有PostgreSQL的受欢迎程度越来越高,而其他数据库则趋于平稳或正在失去理智。
此外,对于许多应用程序,PostgreSQL是Oracle的***替代品。组织正在被PostgreSQL所吸引,因为它是开源的,供应商中立(MySQL由Oracle拥有),拥有一个参与的开发者社区,一个繁荣的供应商生态系统,一个强大的功能集,以及一个成熟的代码库,一直在战斗 - 经过20多年的严格使用而坚固。
3.分布式事务:Google Spanner或Percolator?
关于我们应该如何设计分布式事务,我们查看了Google Spanner和Percolator。
总而言之,Google Percolator提供高吞吐量但使用单个时间戳。这种方法本质上是不可扩展的,仅适用于单个数据中心,面向实时分析(称为HTAP)的应用程序,而不是OLTP应用程序。另一方面,Google Spanner的分散时间跟踪方法对于地理分布式OLTP和单数据中心HTAP应用程序来说都是一个很好的解决方案。
Google Spanner是在Google Percolator之后构建的,用于替换广告后端中手动分片的MySQL部署,以实现水平可扩展性和地理分布式用例。但是,考虑到其真正的分布式特性以及对时钟偏移跟踪的需求,Google Spanner的构建难度要高一个数量级。
有关此主题的更多详细信息,您可以详细了解Percolator与Spanner的权衡。
我们决定采用Google Spanner方法,因为它可以支持:
- 更好的水平可扩展性
- 高度可用且性能更佳的多区域部署。
我们坚信,大多数现代云应用都需要上述两种功能。实际上,GDPR和总共提供100个地区的公共云等合规性要求已经使这成为现实。
4. Raft是否适用于地理分布式工作负载?
Raft和Paxos是众所周知的分布式共识算法,并且已被正式证明是安全的,Spanner使用Paxos,但是,我们选择了Raft,因为:
- 对于开发人员和运营团队Raft比Paxos更容易理解。
- 它提供动态更改成员资格的能力,这是至关重要的(例如:在不影响性能的情况下更改机器类型)。(banq注:Raft与Paxos主要区别在于Raft候选人可以是任何一个服务器节点,不需要专门指定候选人,否则这些候选人全部宕机怎么办?如同一些TCC分布式事务中存在事务协调器一样有单点风险)
然而,为了确保可线性化的读取,Raft要求接收读取查询的每个***在实际提供读取查询之前首先将心跳消息传播到Raft组中的大多数节点。在某些情况下,这可能会严重降低读取性能。这种情况的一个示例是地理分布式部署,其中往返会显着增加延迟,并且在诸如临时网络分区之类的事件的情况下增加失败查询的数量。
为了避免Raft高延迟,我们实施了***的租赁机制,这将允许我们无需往返实现***服务,同时保留了Raft的线性化特性。此外,我们使用单调时钟而不是实时时钟,以容忍时钟偏差。
5.我们可以构建软件定义的原子钟吗?
作为分布式数据库,YugaByte DB支持跨多个节点的多键ACID事务(快照和可序列化隔离级别),即使存在故障也是如此。这需要一个可以跨节点同步时间的时钟。
Google Spanner使用TrueTime,这是一个具有严格错误界限的高可用性全局同步时钟的示例。但是,许多部署中都没有此类时钟。
物理时钟(或挂钟)不能在节点之间***同步。因此,他们无法跨节点排序事件(建立因果关系)。除非存在中央时间戳权限,否则诸如Lamport时钟和向量时钟之类的逻辑时钟不会跟踪物理时间,这成为可扩展性瓶颈。
我们的方案: 混合逻辑时钟(HLC)通过将使用NTP粗略同步的物理时钟与跟踪因果关系的Lamport时钟相结合来解决该问题。
YugaByte DB使用HLC作为高可用性群集宽时钟,具有用户指定的***时钟偏差上限值。HLC值在Raft组中用作关联更新的方式,也用作MVCC读取点。结果是符合ACID的分布式数据库,如Jepsen测试所示。
6.重写或重用PostgreSQL查询层?
***但同样重要的是,我们需要决定是否重写或重用PostgreSQL查询层。
我们的初步决定
YugaByte数据库查询层在设计时考虑了可扩展性。通过在C ++中重写API服务器,已经在这个查询层框架中构建了两个API(YCQL和YEDIS),首先重写PostgreSQL API似乎更容易和自然。
我们的最终决定
在我们意识到这不是一条理想的道路之前,我们沿着这条路走了大约5个月。与PostgreSQL成熟,完整的数据库相比,其他API要简单得多。然后我们重新完成整个工作,回到绘图板并重新开始重新使用PostgreSQL的查询层代码。虽然这在开始时很痛苦,但回顾起来它是一个更好的策略。
这种方法也有其自身的挑战。我们的计划是首先将PostgreSQL系统表移动到DocDB(YugaByte DB的存储层),最初支持一些数据类型和一些简单查询,并随着时间的推移添加更多数据类型和查询支持。
不幸的是,这个计划并没有完全解决。要从psql执行看似简单的最终用户命令,实际上需要支持大量SQL功能。例如,\d用于列出所有表的命令在内部执行以下查询:
- c.relname as "Name",
- CASE c.relkind
- WHEN 'r' THEN 'table'
- WHEN 'v' THEN 'view'
- WHEN 'm' THEN 'materialized view'
- WHEN 'i' THEN 'index'
- WHEN 'S' THEN 'sequence'
- WHEN 's' THEN 'special'
- WHEN 'f' THEN 'foreign table'
- END as "Type",
- pg_catalog.pg_get_userbyid(c.relowner) as "Owner"
- FROM pg_catalog.pg_class c
- LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
- WHERE c.relkind IN ('r','')
- AND n.nspname <> 'pg_catalog'
- AND n.nspname <> 'information_schema'
- AND n.nspname !~ '^pg_toast'
- AND pg_catalog.pg_table_is_visible(c.oid)
- ORDER BY 1,2;
WHERE支持操作符,例如IN,不等于,正则表达式匹配等。满足上述查询需要支持以下功能:
- CASE 条款
- 加入,特别是 LEFT JOIN
- ORDER BY
- 内建等 pg_table_is_visible()
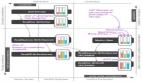
显然,这代表了各种各样的SQL功能,因此我们必须在创建单个用户表之前使所有这些功能都可用!我们在Google Spanner架构上发布分布式PostgreSQL - 查询层突出显示了查询层的详细工作方式。
结论
即使对于专家用户来说,不得不在市场上可用的许多数据库之间进行选择,一开始看起来似乎势不可挡。这是因为为给定类型的应用程序选择数据库取决于这些数据库在其体系结构中所做的权衡。
通过YugaByte DB,我们以一种新颖的方式组合了一组非常实用的架构决策,以创建一个独特的开源分布式SQL数据库。PostgreSQL强大的SQL功能现在可供您使用,零数据丢失,水平写入可扩展性,低读取延迟以及在公共云或Kubernetes中本机运行的能力。