【51CTO.com原创稿件】21世纪以来的金融科技大潮汹涌澎湃。伴随着人工智能和互联网技术的兴起,传统金融行业受到了颠覆性的冲击。特别是在金融风控领域,伴随着机器学习理论的发展和成熟,以及人们对技术的信赖度逐渐增加,越来越多的金融企业和机构采纳了人工智能的方式来处理传统的业务问题。
站在人工智能的角度上来说,风控本身是一个不均衡分类问题。所谓不均衡分类问题,是指在分类的过程中正负样本的分布极为不均。因为在银行借贷的过程中,欺诈用户毕竟是少数人,互联网金融公开的数据欺诈率在 10% 到 20%,传统银行业的欺诈率通常更低。所以金融科技公司要解决的就是如何在数据分布不均衡的情况下通过分类的方法把恶意用户筛选掉。
因为本质上是分类问题,所以只要是分类算法,都可以用来尝试解决问题。像传统的浅层模型逻辑回归、随机森林、xgboost 以及后续的混合模型和深度学习模型都可以用来做风控。这里分享恒昌利通的研究人员在 2018 年的国际会议 DMKD 2018 发表的一篇介绍金融行业风控的论文《Detection of fraudulent users in P2P financial market》。
论文作者的数据输入主要是线下门店的用户填表信息,包括用户的家庭信息,工作单位信息,贷款信息等。作者尝试使用随机森林和 xgboost 的方法,并进行了对比。对比主要采用了 Grid Search 枚举了模型参数。评测指标为 AUC 。
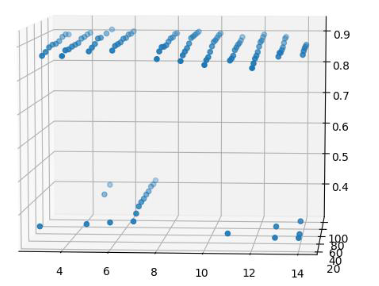
输入数据总共有 97 个特征,其中有 33 个特征是类别特征。类别特征用 one-hot 的形式进行了处理。实验数据分为训练集、测试集和验证集,数据比例为 4:1:1。因为数据总体维度较高,因此在分类前尝试用 PCA 的方法进行数据降维处理,得到随机森林 + PCA 的 Grid Search 效果图如下所示:

随机森林+PCA 在测试集上的 AUC 为 0.78 ,在训练集上的 AUC为 0.797。随后作者比较了 xgboost + PCA 的效果。因为数据集合的分布跨度很大,因此考虑采用 tanh 对数据进行归一化处理,归一化处理后 xgboost + tanh 的效果***,排除奇异点得到的 AUC基本在 0.88 左右,如下图所示:
作者也尝试了 PCA + tanh 结合的方式,但是效果并不如 xgboost + tanh 理想,所以最终采纳的模型为 xgboost + tanh 。
风控反欺诈领域的人工智能探索持续了多年,早在 2000 年初期美国的研究者就已经在研究相关领域的技术。然而相关技术真正得到人们的信任,也是等到了许多年的时间检验之后。直到人工智能技术日趋成熟的今天,仍然会有许多的门户之见:例如只有精通金融业务的人才能真正做好风控,风控数据重要还是模型重要等带有严重偏见的无聊办公室政治话题经常影响公司内部正常的业务开展。
2018年 Kaggle 上 Home Credit 这家公司组织了一次反欺诈比赛,提供的基本数据都是一样的,参赛的基本都是技术人员,差别只在大家对特征工程和模型的选择和处理上,最终的结果千差万别。这样的比赛活动能够打消许多人对于人工智能技术的偏见和误解。所以说很多时候影响一项技术或者事业进步的,不是技术本身,而是人的固有执念。
当然,这也并不是说技术不成熟就要硬上。比如深度学习模型在金融风控领域其实现在还没有取得比 xgboost 或者浅层模型更好的效果。为了绩效或者面子工程而拿深度学习模型作秀实属浪费公司的资源和开发者个人的宝贵时间。
总之,金融科技行业近几年来发展迅猛,但是在发展的过程中泥沙俱下。作为金融科技从业者对于自己的事业要有清晰的认知和定位。
作者简介:
汪昊,区块链公司科学家,前恒昌利通大数据部负责人,美国犹他大学本科/硕士,在百度,新浪,网易,豆瓣等公司有多年的研发和技术管理经验,擅长机器学习,大数据,推荐系统,社交网络分析等技术。在 TVCG 和 ASONAM 等国际会议和期刊发表论文 10 篇。本科毕业论文获国际会议 IEEE SMI 2008 ***论文奖。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】