概述
近两年研究人员通过对AI模型的安全性分析发现,机器学习模型和神经网络模型都容易受到恶意用户的对抗攻击,攻击者可以通过生成对抗样本的方式攻击AI模型并误导AI模型做出错误的判断,这一安全问题备受关注。
目前已有的机器学习模型和神经网络模型都是通过提取数据特征,构建数学判别公式然后根据数学模型进行学习。提取数据特征的过程中容易提取到错误特征、而且判别公式也可能出现与真实决策面分布不同的问题,因此攻击者可以利用AI模型的弱点,生成欺骗模型的对抗样本。例如在图像识别领域,可以通过在正常图片上加入一个微小的噪声从而使图像识别分类器无法正常识别图像,导致错误分类的效果。这一问题存在严重的安全隐患。
对抗攻击往往是指攻击者利用特定的模型算法对AI模型进行攻击,其不仅包括攻击者熟悉AI模型的条件下,对实际输入进行修改从而误导AI模型的判别结果,而且包括攻击者在不了解AI模型的结构和参数的情况下,借助机器学习模型之间算法迁移的特性对AI模型进行攻击。
对抗样本通常是指经过特定的算法处理之后,模型的输入发生了改变从而导致模型错误分类。假设输入的样本是一个自然的干净样本。那么经过攻击者精心处理之后的样本则称为对抗样本,其目的是使该样本误导模型做出判断。
对抗攻击
对抗攻击可以从几个维度进行分类。例如可以通过攻击者对AI模型的了解程度进行分类。
- 白盒攻击。攻击者拥有模型的全部知识,包括模型的类型,模型结构,所有参数和可训练权重的值。
- 有探针的黑盒攻击。攻击者只了解模型的部分知识,可以探测或者查询模型,比如使用一些输入,观察模型的输出结果。这种场景有很多的变种,比如攻击者知道模型结构,但是不知道参数的值,或者攻击者甚至连模型架构都不知道;攻击者可能能够观测到模型输出的每个类别的概率,或者攻击者只能够看到模型输出最可能的类别名称。
- 无探针的黑盒攻击。在没有探针的黑盒攻击中,攻击者只拥有关于模型有限的信息或者根本没有信息,同时不允许使用探测或者查询的方法来构建对抗样本。在这种情况下,攻击者必须构建出能够欺骗大多数机器学习模型的对抗样本。
此外还可以通过攻击者攻击的目标将对抗攻击分类。
- 无目标攻击(non-targeted attack)。在这种情况下,攻击者的目标仅仅是使得分类器给出错误预测,具体是哪种类别产生错误并不重要。
- 有目标攻击(targeted attack)。在这种情况下,攻击者想要将预测结果改变为某些指定的目标类别中。
1. 白盒攻击
传统的白盒攻击是指在我们已知神经网络模型的网络结构以及模型参数的情况下,我们针对该神经网络生成对抗样本实现误导该模型的效果。攻击者能够获取机器学习所使用的算法以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够和机器学习的系统有所交互。这种“透明”的攻击方式称之为白盒攻击,通常是利用模型的梯度、logits输出等模型本身的知识来设计对抗性扰动生成对抗样本对该模型进行攻击。白盒攻击流程示意图如下所示。
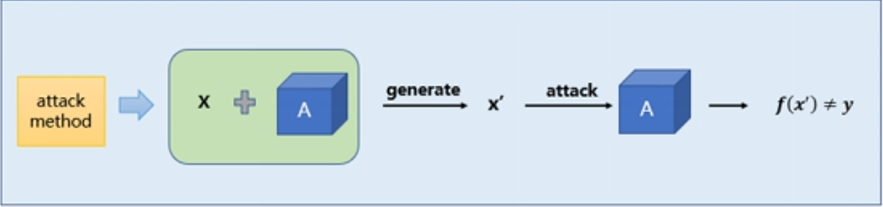
白盒攻击示意图
根据对抗样本生成原理的不同,白盒攻击通常可以分为三类:基于梯度(gradient-based)的攻击、基于优化(optimization-based)的攻击、基于模型(model-based)的攻击。根据生成对抗样本是否对类别有针对性分为有目标攻击和无目标攻击。
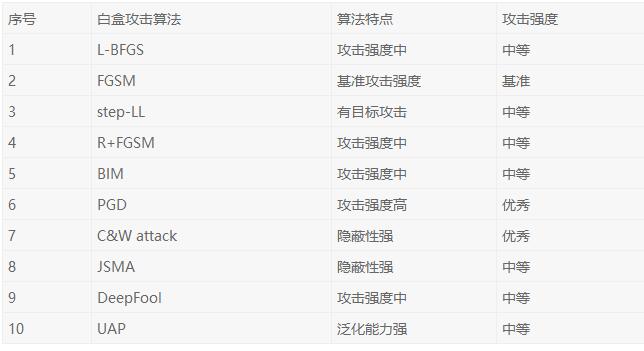
下表中总结了当前常用的十种白盒攻击算法的特点,以作为白盒攻击算法的比较参考。
常用的十种白盒攻击算法总结
2. FGSM白盒攻击算法
FGSM(Fast gradient sign method)是一种常见的白盒攻击算法。该攻击方法的思路非常简单,主要是利用模型损失函数对输入求梯度得到对抗性扰动,然后将对抗性扰动添加到原始样本中生成对抗样本。通过在原始样本的邻域中线性化损失函数,并通过如下闭合形式的方程找到精确的线性化函数的最大值。

FGSM是通过计算单步梯度快速生成对抗样本。基于梯度的攻击方法的原理在于绝大多数神经网络模型中都是通过梯度下降算法最小化损失函数来进行训练的,因此利用损失函数对输入求梯度,沿着梯度上升方向是使样本朝着损失增大的方向移动,就有可能导致预测输出改变。
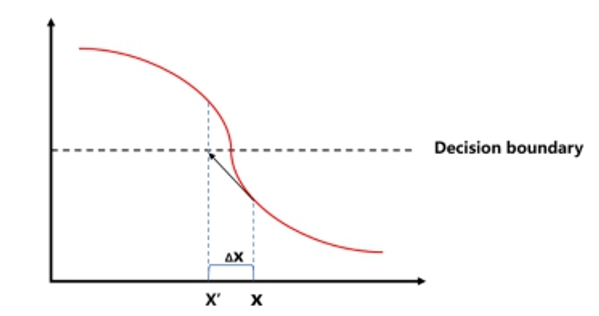
FGSM原理示意图
FGSM方法优点是计算成本低、生成速度快,缺点是攻击能力较弱,适用于对攻击效率有较高要求的应用场景。
3. C&W白盒攻击算法
C&W攻击算法是一种基于迭代优化的低扰动对抗样本生成算法。该算法设计了一个损失函数,它在对抗样本中有较小的值,但在原始样本中有较大的值,因此通过最小化该损失函数即可搜寻到对抗样本。
C&W算法主要对多步迭代攻击中的优化函数进行重新设计,采用以下目标函数:

上式中第一项ξ 是一个需要经验确定的权重参数,用来平衡攻击的隐蔽性与攻击强度。第一项的最小化意味着需要尽量使样本在模型中的输出不为其对应标签。第二项中的τ 初始化为最大允许的扰动幅度,通常为数据最大变化量的无穷范数的6.25%,每当第二项优化到0时,τ会以0.9x的速度递减。如下图所示逐步更新第二项的意义在于逐渐限制最大允许扰动幅度,从而增强对抗攻击的隐蔽性。
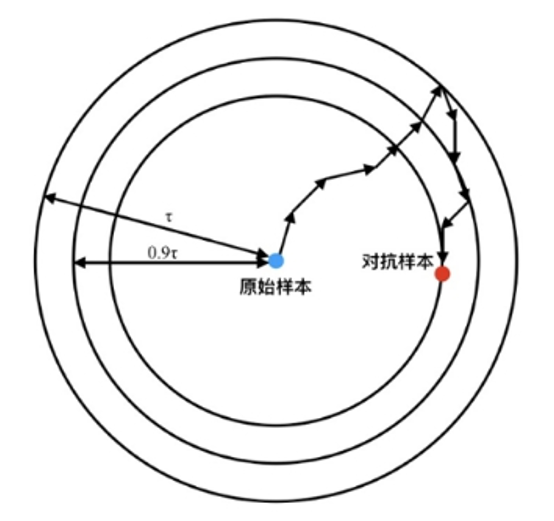
综上所述, C&W算法在继承简单多步迭代攻击的基础之上,改进其目标优化函数,使其逐步收紧对扰动幅度的限制,从而达到减小对抗样本扰动幅度的要求,进而使对抗样本的隐蔽性提升。
4. 基于集成的黑盒攻击算法
在实际的应用场景中,攻击者可能无法获取到AI模型的一些详细信息,例如模型的参数和神经网络的结构,但是攻击者可以利用神经网络模型之间具有迁移特性的特点,采用黑盒攻击算法对目标进行攻击。
基于logits集成的黑盒攻击算法是利用集成学习思路的一种黑盒攻击方法。基于logits集成是通过集成多个模型的logits输出,以生成能够使得多个模型分类错误的对抗样本为目标进行训练,从而使得对抗样本能够对另外的零知识的模型具有黑盒攻击能力。常用的对抗攻击方法是利用单个模型的梯度进行快速生成或者利用logits输出进行优化来找到对抗样本。而基于logits集成是利用多个模型的logits输出,以得到对所有模型都具备攻击能力的对抗样本为目的,即这个对抗样本是所有模型的对抗样本,实现上通过攻击多个模型的集成模型来实现。另外还可以考虑给各个模型赋上权重,权衡不同模型之间的相对重要性,以适用于不同的实际应用场景。集成后的logits表达式如下式所示。

其中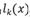 表示第k个模型的logits输出,
表示第k个模型的logits输出,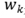 表示第k个模型的logits的权重。模型的损失函数如下:
表示第k个模型的logits的权重。模型的损失函数如下:
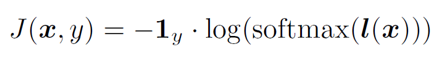
基于logits集成的思想借鉴了集成学习的思想,从原来的单模型对抗样本目标,升级为多模型集成对抗样本目标。基于logits线性加权集成的结构如下图所示。
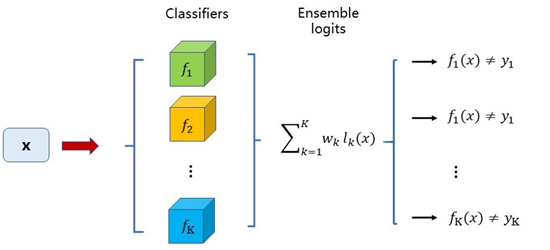
这种方法的优点在于,首先在大规模数据集上具有好的迁移能力;其次既可以迁移无目标攻击,也可以对有目标攻击进行迁移,即可以带着目标标签一起迁移。此外,理论表明,基于logits集成的攻击能力明显优于预测集成和损失函数集成的攻击能力。
对抗样本
通过上面介绍了对抗攻击的几种算法,我们可以借助这些对抗攻击算法来生成对抗样本。目前对抗样本应用最多的领域是图像识别方向,攻击者可以利用攻击算法对图像中的像素点进行修改,改变了输入图像之后可以误导AI模型识别系统做出错误的判断。
我们利用FGSM算法对VGG模型进行攻击,生成对抗样本的关键过程如下。
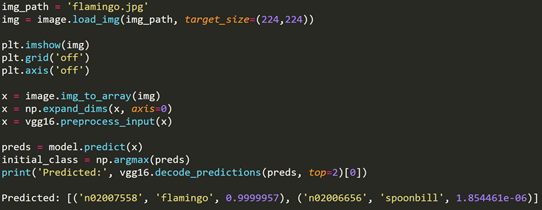
首先我们载入一张火烈鸟的图片,并利用VGG模型进行预测。结果发现VGG模型可以正常识别火烈鸟的图片。

当我们在火烈鸟图片的梯度上升方向上增加一个噪声信号之后,迭代增加400次并限制噪声信号的幅度范围。再次用VGG模型识别图片是发现模型会将火烈鸟识别成鹤。根据FGSM算法的原理对火烈鸟图片进行修改,在原始图像上叠加的噪声就是在限制幅度范围内对图像的梯度进行上升计算。
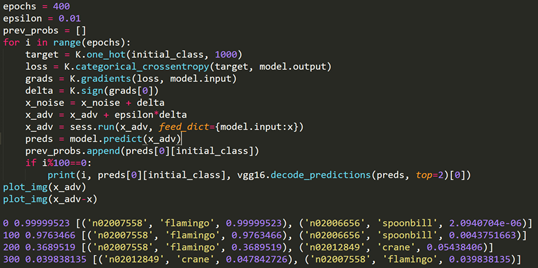

注意到叠加了噪声信号的对抗样本和原始样本实际上肉看观察不到区别,利用程序绘制出噪声信号也会发现噪声幅度很小几乎可以忽略。但是对于VGG模型而言是别的结果却是完全不同的。随着梯度上升迭代次数的增加,噪声信号越来越大、生成的对抗样本迷惑性越来越强,最终导致VGG模型受到了FGSM算法的攻击。
总结
经过对对抗攻击的调研发现,对抗攻击受到越来越多的研究人员和大众的关注。虽然已经有不少研究提出了许多新颖的攻击算法用于产生对抗样本,但是与攻击对应的防御问题一直没有得到很好地解决。
目前的对抗攻击防御解决方法主要包括对抗学习过程加入对抗样本进行训练,以及引入胶囊网络等集成的方式对攻击方法进行防御。然而这些方法都还不成熟,而且没有形成完整的体系,至于防御效果也不明显。可以说目前还没有一个完善的抵御对抗攻击的模型或者方法产生。因此无论是对抗攻击领域还是防御方法都还存在着很大的发展空间。
【本文是51CTO专栏作者“绿盟科技博客”的原创稿件,转载请通过51CTO联系原作者获取授权】