













前天,第 N 次在公开场合 diss 激光雷达的马斯克,再一次让自动驾驶圈对无人车不同的传感器应用方案展开了热议。
实际上,如果站在马斯克的角度,我们其实不难理解他对激光雷达的「痛恨心理」。
毕竟特斯拉是一家面向普通消费者卖车的企业,而不是一家卖自动驾驶技术和解决方案的公司。
在至少 3 年内,无论是从成本、技术可靠性、安全性、美观性甚至是用户对自动驾驶的信任度和品味来看,大多数车企的量产车型,都不会把激光雷达纳入考虑范畴。
当然,根据马斯克说话常常打脸的经典表现来看,或许在几年后他会自己站出来反驳自己坚持的观点。
事实上,在「自动驾驶汽车究竟应该用不用激光雷达」这个问题上长时间的争论不休,衍生出了「激光雷达派」与「纯计算机视觉派」。
目前,一个被激光雷达派以及大众普遍接受的观点是,考虑到纯视觉算法在数据形式和精度上的不足,L3 级以上的自动驾驶乘用车必须要采用激光雷达。
当然,从谷歌 Waymo、通用 Cruise,再到百度阿波罗和国内的 Pony.ai、文远知行等自称 L4 级自动驾驶乘用车解决方案的公司,车顶上的激光雷达一直都非常扎眼。
而「计算机视觉派」的重要组成部分则是自动驾驶技术解决方案初创公司,但这个解决方案到底是多高的级别,其实目前没有确切的定论。
通常情况下,「昂贵的成本」和「技术能力」是众多车企与计算机视觉技术公司反对采用激光雷达的主要理由。
譬如作为一家主打摄像头方案的技术创业公司,2017 年 AutoX 的「炫技首秀」就是让一辆只搭载 7 个摄像头的林肯 MKZ 跑在普通公路的车道上。虽然后来受到了来自激光雷达派的「反击」,其创始人兼 CEO 肖健雄也一直坚持以摄像头为主的传感器方案,
此外,部分高精地图创业公司也强调从成本出发,采用低成本的摄像头方案采集高精数据。
综合来看,截至目前自动驾驶圈内最主流的观点虽然是「该有的,一个都不能少」,但不难看出,做车厂的生意,对于计算机视觉公司来说,暂时性抛开激光雷达是个还不错的主意;
而另一层面,对于计算机视觉工程师来说,想要在高级别自动驾驶解决方案上摆脱激光雷达,就要持续研究和验证纯视觉技术方案替代激光雷达的可行性。
因此,当大家还在围观「马斯克骂激光雷达」时,我们想从机器之心擅长的角度出发,看看能否从技术上来「验证」这个看似不太靠谱的观点。
很凑巧,我们发现了一篇来自康奈尔大学的技术论文,作者中 Yan Wang 与 Wei-Lun Chao 均为华人。该论文提出了一种新方法来缩短纯视觉技术架构与激光雷达间的性能差距。
该论文提出的方法,改变了立体摄像机目标检测系统的 3D 信息呈现形式,甚至将其称之为——伪激光雷达数据(pseudo-LiDAR)。
研究者在挡风玻璃两侧各使用一个相对廉价的摄像机,采用其新方法之后,该摄像机在目标检测方面的性能接近激光雷达,且其成本仅为后者的一小部分。研究者发现以鸟瞰图而不是正视图来分析摄像机捕捉到的图像可以将目标检测准确率提升 2 倍,从而使立体摄像机成为激光雷达的可行替代方案,且其成本相比后者要低很多。
研究主题
可靠和稳健的 3D 目标检测是自动驾驶系统的基础要求。要想避免与行人、骑自行车的人、汽车相撞,自动驾驶汽车必须第一时间检测出它们。
现有的算法严重依赖激光雷达(LiDAR),它可以提供周边环境的准确 3D 点云。尽管激光雷达的准确率很高,但出于以下原因,自动驾驶行业急需激光雷达的替代品:
首先,激光雷达非常昂贵,给自动驾驶硬件增加了大量费用;
其次,过度依赖单个传感器会带来安全风险,在一个传感器出现故障时利用备用传感器是较优的选择。一个自然的选择是来自立体摄像机或单目摄像机的图像。光学相机性价比较高(比激光雷达便宜了多个数量级),且可以高帧率运行,能够提供稠密深度图,而激光雷达信号只有 64 个或 128 个稀疏旋转激光束。
近期的多项研究探索了在 3D 目标检测中使用单目摄像机和立体深度(视差)估计 [19, 13, 32]。但是,目前主要的成果仍然是激光雷达方法的补充。
例如,KITTI 基准上的一个算法 [17] 使用传感器融合(sensor fusion)将汽车的 3D 平均精度(AP)从激光雷达的 66% 提升到了激光雷达+单目图像的 73%。而在仅使用图像的算法中,当前最好算法的 AP 仅为 10% [30]。
对后者较差性能的一个直观且流行的解释是基于图像的深度估计准确率较低。
与激光雷达相反,立体深度估计的误差随着深度增加而呈现二阶增长。但是,对激光雷达和立体深度估计器生成的 3D 点云进行视觉对比后发现,这两种数据模态之间存在高质量的匹配,甚至远处的物体也是如此(详见图 1)。

图 1
图 1:来自视觉深度估计的伪激光雷达(pseudo-LiDAR)信号。左上:KITTI 街景图像,其中汽车周围的红色边界框是通过激光雷达获取的,而绿色边界框是通过伪激光雷达获取的。左下:估计到的视差图。右:伪激光雷达vs 激光雷达。其中伪激光雷达点与激光雷达的点很好地对齐。
解决方案
这篇论文提供了另一种解释——研究者假设立体摄像机和激光雷达之间性能差距的主要原因不在于深度准确率的差异,而是在于在立体摄像机上运行的 ConvNet 3D 目标检测系统的 3D 信息表示。
具体来说,激光雷达信号通常被表示为 3D 点云或者「鸟瞰」视角图,并据此进行处理。在这两种情况下,目标的形状和大小都不会随着深度而发生变化。
而基于图像的深度估计主要是针对每个像素,通常被表示为额外的图像通道,使得远处的对象很小,不易被检测到。更糟糕的是,这种表示的像素近邻将 3D 空间中较远区域的点聚集在一起,这就使得在这些通道上执行 2D 卷积的卷积网络更难推理,以及准确地定位 3D 空间中的物体。
为了验证这一论断,该研究引入了一种适用于立体摄像机 3D 目标检测的两步法。首先将来自立体摄像机或单目摄像机的估计深度图转换为 3D 点云,即模拟激光雷达信号的伪激光雷达;然后利用现有的基于激光雷达的 3D 目标检测流程 [23, 16],直接在伪激光雷达表示上进行训练。
通过改变伪激光雷达的 3D 深度表示,使基于图像的 3D 目标检测算法获得大幅的准确率提升。具体来说,在 KITTI 基准上获得 0.7 交并比(IoU)的汽车实例在验证集上获得了 37.9% 的 3D AP,比之前图像方法的准确率提升了 2 倍。这样就能把基于立体摄像机和基于激光雷达的系统之间的差距减半。

图 2
图 2:用于 3D 目标检测的两步 pipeline。给定立体或单目摄像机图像,研究者首先预测深度图,然后将其转换为激光雷达坐标系统中的 3D 点云,即伪激光雷达。然后像处理激光雷达一样处理它,因此任何基于激光雷达的 3D 检测算法都能在其上使用。
研究者对立体深度估计和 3D 目标检测算法的多种组合进行了评估,并得到了非常一致的结果。这表明性能的提升是由于使用了伪激光雷达表示,它较少依赖于 3D 目标检测架构的创新或深度估计技术。
总之,该论文有以下贡献:
- 首先,通过实验证明,基于立体摄像机和基于激光雷达的 3D 目标检测技术之间的性能差异不是因为估计深度的质量,而是因为表示。
- 其次,研究者提出了一种新型 3D 目标检测估计深度表示——伪激光雷达,将之前的性能提升了 2 倍,达到了当前最佳水平。
- 这一研究结果表明,在自动驾驶汽车中使用立体摄像头是可能的,这样既能够极大地降低成本,又能够改进安全性能。
论文:
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving

论文链接:https://arxiv.org/abs/1812.07179
摘要:3D 目标检测是自动驾驶的一项重要任务。如果 3D 输入数据是通过精确但昂贵的激光雷达获得的,那么目前的技术可以获得高度精确的检测率。基于较便宜的单目摄像机或立体摄像机图像数据的方法目前能够达到的准确率较低,这种差距通常被归因于基于图像的深度估计技术缺陷。
然而,在本文中,研究者认为,数据表示(而非其质量)是造成这种差距的主要原因。研究者将卷积神经网络的内部工作原理考虑在内,提出将基于图像的深度图转换为伪激光雷达表示——本质上是模拟激光雷达信号。有了这种表示,我们就能应用当下基于激光雷达的各种不同检测算法。
在流行的 KITTI 基准上,该论文提出的方法在基于图像的性能方面取得了令人印象深刻的改进,超越当前最佳方法,将 30 米范围内的目标检测准确率从当前最佳的 22% 提高到了 74%。截至论文提交时,该论文提出的算法在基于立体图像方法的 KITTI 3D 目标检测排行榜上达到了当前最高水平。
实验
研究者通过不同的深度估计和目标检测算法,在不同的设置下评估了有/没有伪激光雷达的情况下 3D 目标检测的结果(如下表)。伪激光雷达得到的结果显示为蓝色,真实激光雷达的结果显示为灰色。
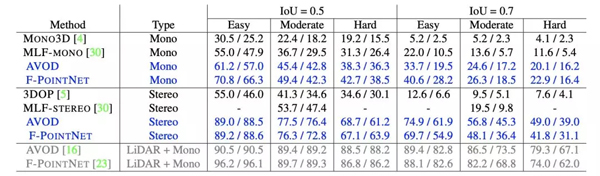
表 1
表 1:3D 目标检测结果。表中显示了汽车分类的 AP_BEV / AP_3D 百分率、对应于鸟瞰图和 3D 目标框检测的平均精度。
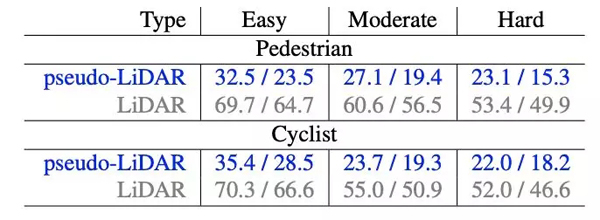
表 4
表 4:行人和骑车人类别的 3D 目标检测结果。研究者报告了 IoU = 0.5(标准度量)时的 AP_BEV / AP_3D,并将 PSMNET(蓝色)估计的伪激光雷达和激光雷达(灰色)进行比较,两者都使用 F-POINTNET 算法。

图 4
图 4:定性比较。研究者使用 AVOD 算法对激光雷达、伪激光雷达和正视图(立体)进行了比较。红色框中的是 Groundtruth,绿色框中的是预测框;伪激光雷达图像(下面一行)中的观测者在最左边向右看。正视图方法(右)甚至错误计算了附近目标的深度,并且完全忽视了远处的目标。
参考链接:
- https://arxiv.org/abs/1812.07179
- https://www.sciencedaily.com/releases/2019/04/190423145508.htm
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】
























