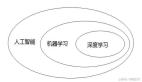
导语:这几年人工智能技术之所以能够获得快速发展,主要是有三个元素的融合:神经元网络、芯片以及大数据。人工智能是让机器像人一样思考甚至超越人类,而机器学习是实现人工智能的一种方法,它最基本的做法是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。深度学习又是机器学习的一种实现方式,它是模拟人神经网络的方式,用更多的层数和神经元,给系统输入海量的数据来训练网络。下面我以人工智能在医疗领域的平台架构为例,进行五层模型技术栈的讲解,分别是基础数据层,计算引擎层,分析引擎层,应用引擎层和典型应用层,重点讲解计算和分析引擎。

01
首先,探讨一下人工智能平台的计算引擎,目前最主流的五个大数据分布式计算框架包括Hadoop,Spark,Flink,Storm,Samaza。下面分别探讨其优势和应用场景。
1. Hadoop是***被商用的框架,在工业和产品界被广泛认可。如果数据可以批量处理,可以被分割成小的处理任务,分发到计算集群,然后综合计算结果,并且整个过程都是逻辑清晰,那么这个场景下很适合用Hadoop处理。
2. Spark是采用更先进的架构,其灵活性、易用性、性能等方面都比Hadoop更有优势,有取代Hadoop的趋势,但其稳定性需要大幅提高。
3. Flink既是批处理又是实时处理框架,但流处理还是放在***位的,Flink提供了一系列API,包括针对Java和Scala的流API,针对Java,Scala,Python的静态数据API,以及在Java和Scala中嵌入SQL查询的代码。它也自带机器学习和图像处理包。
4. Storm是占领一定市场份额的分布式计算框架,其应用被设计成有向无环图。被设计成容易处理***流,并且可用于任何编程语言。每个节点每秒处理上百万个元组,高度可伸缩,提供任务处理保证。用Clojure写的。可用于实时分析,分布式机器学习,以及大量别的情形,特别是数据流大的。Storm可以运行在YARN上,集成到Hadoop生态系统中。
5. Samza是由LinkedIn开源的一个分布式流处理框架,它是基于Kafka消息队列来实现类实时的流式数据处理的,非常像Twitter的流处理系统Storm。不同的是Samza基于Hadoop,而且使用了LinkedIn的Kafka分布式消息系统,并使用资源管理器Apache Hadoop YARN实现容错处理、处理器隔离、安全性和资源管理。
02
Spark是专为大规模数据处理而设计的快速通用的计算引擎,目前已经发行了2.4版本。Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,几乎拥有Hadoop MapReduce所具有的优点,借助内存分布数据集,除了能够提供交互式查询外,还可以优化迭代工作负载。Spark今年发布的2.4,除了持续提升Spark的稳定性、易用性和性能之外,还扩展了Spark的生态圈,引入了Spark on K8s, 让用户多了一种部署Spark的方式,还引入了Pandas UDF,可以让用户在Spark上直接运行Pandas函数。我们分析其内核运行架构如下:
1. SparkContext引擎构建分析:
通常而言,用户开发的Spark应用程序的提交与执行都离不开SparkContex的支持。在正式提交应用程序之前,首先需要初始化SparkContext。SparkContext隐藏了网络通信、分布式部署、消息通信、存储体系、计算引擎、度量系统、文件服务、Web UI等内容,应用程序开发者只需要使用SparkContext提供的API完成功能开发。
2. SparkEnv环境构建分析:
Spark执行环境SparkEnv是Spark中的Task运行所必需的组件。SparkEnv内部封装了RPC环境(RpcEnv)、序列化管理器、广播管理器(BroadcastManager)、map任务输出跟踪器(MapOutputTracker)、存储体系、度量系统(MetricsSystem)、输出提交协调器(OutputCommitCoordinator)等Task运行所需的各种组件。
3. 可交换的存储体系分析:
Spark优先考虑使用各节点的内存作为存储,当内存不足时才会考虑使用磁盘,这极大地减少了磁盘I/O,提升了任务执行的效率,使得Spark适用于实时计算、迭代计算、流式计算等场景。在实际场景中,有些Task是存储密集型的,有些则是计算密集型的,所以有时候会造成存储空间很空闲,而计算空间的资源又很紧张。Spark的内存存储空间与执行存储空间之间的边界可以是“软”边界,因此资源紧张的一方可以借用另一方的空间,这既可以有效利用资源,又可以提高Task的执行效率。此外,Spark的内存空间还提供了Tungsten的实现,直接操作操作系统的内存。由于Tungsten省去了在堆内分配Java对象,因此能更加有效地利用系统的内存资源,并且因为直接操作系统内存,空间的分配和释放也更迅速。
4. 双级调度系统分析:
调度系统主要由DAGScheduler和TaskScheduler组成,它们都内置在SparkContext中。DAGScheduler负责创建Job、将DAG中的RDD划分到不同的Stage、给Stage创建对应的Task、批量提交Task等功能。TaskScheduler负责按照FIFO或者FAIR等调度算法对批量Task进行调度;为Task分配资源;将Task发送到集群管理器的当前应用的Executor上,由Executor负责执行等工作。即使现在Spark增加了SparkSession和DataFrame等新的API,但这些新API的底层实际依然依赖于SparkContext。
5. 多维计算引擎分析:
计算引擎由内存管理器(MemoryManager)、Tungsten、任务内存管理器(TaskMemory-Manager)、Task、外部排序器(ExternalSorter)、Shuffle管理器(ShuffleManager)等组成。MemoryManager除了对存储体系中的存储内存提供支持和管理外,还为计算引擎中的执行内存提供支持和管理。Tungsten除用于存储外,也可以用于计算或执行。TaskMemoryManager对分配给单个Task的内存资源进行更细粒度的管理和控制。ExternalSorter用于在map端或reduce端对ShuffleMapTask计算得到的中间结果进行排序、聚合等操作。ShuffleManager用于将各个分区对应的ShuffleMapTask产生的中间结果持久化到磁盘,并在reduce端按照分区远程拉取ShuffleMapTask产生的中间结果。
6. 强大的SparkMLlib机器学习库:
旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。
然后,分析一下人工智能平台分析引擎的处理过程。分析引擎的主要技术是机器学习和深度学习。机器学习框架涵盖用于分类,回归,聚类,异常检测和数据准备的各种学习方法,也可以包括神经网络方法。深度学习框架涵盖具有许多隐藏层的各种神经网络拓扑,包括模式识别的多步骤过程。网络中的层越多,可以提取用于聚类和分类的特征越复杂。常见的深度学习框架有Caffe,CNTK,DeepLearning4j,Keras,MXNet和TensorFlow。其中Deeplearning4j是应用最广泛的JVM开源深度学习工具,面向Java、Scala和Clojure用户群。它旨在将深度学习引入生产栈,与Hadoop与Spark等主流大数据框架紧密集成。DL4J能处理图像、文本、时间序列和声音等所有主要数据类型,提供的算法包括卷积网络、LSTM等循环网络、Word2Vec和Doc2Vec等NLP工具以及各类自动编码器。Deeplearning4j自带内置Spark集成,用于处理在集群上开展的分布式神经网络训练,采用数据并行来将网络训练向外扩展至多台计算机,每个节点靠一个(或四个)GPU运行。
03
深度学习框架的计算需要大量的图像数据,数据从前端传输到后端进行预处理,然后进行标注,获得训练数据集。数据整理好之后,进行模型训练,这是一个计算和通信非常密集的过程;模型训练完之后,我们进行推理预测,其主要是一个前向计算过程。其需要对批量样本的高吞吐高并发响应和单个样本的低延时响应。下面以图像识别的过程为例说明如下:
1. 数据的采集和获取:
是通过物联网传感器,将光或声音等信息转化为电信息。信息可以是二维的图象如文字、图象等,可以是一维的波形如声波、心电图、脑电图,也可以是物理量与逻辑值。
2. 数据预处理:
包括A\D、二值化、图象的平滑、变换、增强、恢复、滤波等, 主要指图象处理。
3. 特征抽取和选择:
在模式识别中,需要进行特征的抽取和选择,例如,一幅64x64的图象可以得到4096个数据,这种在测量空间的原始数据通过变换获得在特征空间最能反映分类本质的特征。这就是特征提取和选择的过程。
4. 分类器设计:
分类器设计的主要功能是通过训练确定判决规则,使按此类判决规则分类时,错误率***。
5. 分类决策:
在特征空间中对被识别对象进行分类。
***,探讨人工智能平台分析引擎的深度学习,它是如何针对多层神经网络上运用各种机器学习算法解决图像、文本等问题?深度学习从大类上可以归入神经网络,不过在具体实现上有许多变化。深度学习的核心是特征学习,旨在通过分层网络获取分层次的特征信息,从而解决以往需要人工设计特征的重要难题。深度学习是一个框架,包含多个重要算法: CNN卷积神经网络、AutoEncoder自动编码器、Sparse Coding稀疏编码、RBM限制波尔兹曼机、DBN深信度网络、RNN多层反馈循环神经网络神经网络,对于不同问题(图像,语音,文本),需要选用不同网络模型才能达到更好效果。
04
重点讲一下卷积神经网络,它就是至少包含一层的神经网络,该层的功能是:计算输入f与可配置的卷积核g的卷积,生成输出。卷积的目的就是把卷积核应用到某个张量的所有点上,通过卷积核的滑动生成新的滤波后的张量。卷积的价值在于对输入降维能力,通过降维改变卷积核的跨度strides参数实现。设置跨度是调整输入张量维数的方法,strides参数格式与输入向量相同,面临挑战:如果应对输入在边界,可以采用对图像边界填充方式。数据格式NHWC(数目,高度,宽度,通道数)。卷积核的作用常常是增强卷积核中心位置像素的灰度。卷积神经网络CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。
由于CNN的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显式的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。
激活函数:为神经网络的输入引入非线性,通过曲线能够刻画输入中更为复杂的变化,设计模型常推荐tf.nn.relu,tf.sigmoid,tf.tanh,tf.nn.dropout,性能较为突出,评价一个激活函数是否有用的因素如下:单调,采用梯度下降法寻找局部极值点;可微分,保证任何一个点可以求导数,可以使梯度下降法用到激活函数的输出上。模型的评价指标是敏感度、特异度和精度。灵敏度(敏感度,召回率recall,查全率sensitive)=TP/P =TPR;特异度(特效度specificity)=TN/N;精度(查准率,准确率precision)=TP/TP+FP。
总之,人工智能的框架时代已经成熟了,不是我们科学家和技术专家的主战场,我们是要重新定义一些计算模型和算法实现,来创新网络结构和训练方法,这样的深度学习算法会更加有效,能够在普通的移动设备端工作,甚至不需要多余的硬件支持或抑制内存开销,会触发人工智能技术进入大规模商用阶段,人工智能产品全面进入消费级市场。
【本文为51CTO专栏作者“移动Labs”原创稿件,转载请联系原作者】