













数据分析,包括大数据分析,在企业的业务中,特别是在传统的商务行业,已有多年的应用实践,在消费者市场的营销中已成了必不可缺的技术。随着工业互联网和智能制造的兴起和发展,工业大数据技术也越来越受到各方关注。
在“中国制造2025”的技术路线图中,工业大数据是作为重要突破点来规划的,而在未来的十年,以数据为核心构建的智能化体系会成为支撑智能制造和工业互联网的核心动力。
对制造企业而言,不论是新实施的系统还是老旧系统,要实施大数据分析平台,就需要先弄明白自己到底需要采集哪些数据。因为考虑到数据的采集难度和成本,大数据分析平台并不是对企业所有的数据都进行采集,而是相关的、有直接或者间接联系的数据,企业要知道哪些数据是对于战略性的决策或者一些细节决策有帮助的,分析出来的数据结果是有价值的。
比如企业只是想了解产线设备的运行状态,这时候就只需要对影响产线设备性能的关键参数进行采集。
再比如,在产品售后服务环节,企业需要了解产品使用状态、购买群体等信息,这些数据对支撑新产品的研发和市场的预测都有着非常重要的价值。
因此,建议企业在进行大数据分析规划的时候针对一个项目的目标进行精确的分析,比较容易满足业务的目标。明确目标以后,就要着手开始搜集数据并进行预处理了。本期格物汇将跟大家介绍,企业如何实现对工业大数据的预处理。
数据采集
首先我们看看数据是如何获取的,在现实生活中,我们所面对的问题,往往都是抽象复杂的。我们来看如下两个例子:
如何提升产品的良率?
可能这是制造业最为普遍的一个问题,如果我们要分析解决这个问题,常常就会问到:什么产品?有多少条产线在生成?经过了哪些机台?影响产品良率的因素有哪些?我们可能会提出很多很多这样的问题,解决这些问题需要对相关业务知识非常了解,尽可能多的找出与问题有关的数据。
如何进行人脸识别?
这问题更加复杂一些,虽然我们每个人的大脑每天都在做人脸识别,但是大脑如何工作的却异常难懂。我们可能需要做很多科研工作,去挖掘到底哪些数据会影响到人脸识别的正确率。如果这些数据本身没有,很可能还需要进行测量采集,比如两眼之间的距离,嘴的宽度和长度等等。当然,我们还会评估采集的成本,并对这些数据有效性进行评估,验证我们的成本是否值得去花费精力测量。
数据预处理简介
数据采集以后,数据往往存放在数据库或文件系统中,我们需要把他们导入到算法模型中进行训练,得到我们想要的模型。但是我们的数据往往杂乱无章,总的来说,数据一般存在如下几类问题:
数据类型多种多样
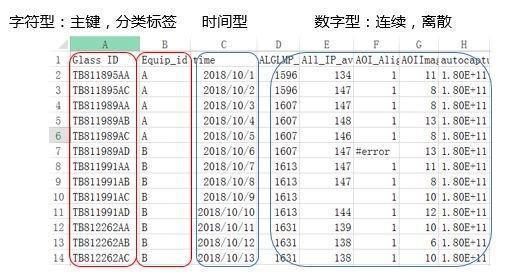
图1
我们的数据中常常出现字符型,时间型,数字型等多种数据类型。其中:字符型是无法代入模型计算的,所以我们根据需要,可以对字符型数据进行编码转换。常用的编码方法有:
数字编码:对于有大小比较的字符型数据,可以直接转换成数字编码。比如:

图2
Onehot编码:对于没有大小比较的字符型数据,可以使用Onehot独热编码。比如:
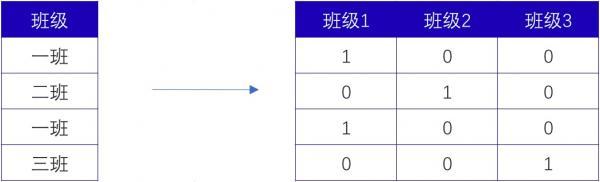
图3
时间类型往往是一类特殊的数据,把时间简单看成一个实数的话,往往不符合逻辑。对于带时间的数据,我们通常使用时间序列的分析方法进行分析。有时候我们更加关注的是两列时间的差值,这时我们可以构建时间差值列作为新的变量加入模型之中。
数字型往往是导入模型进行训练的主要部分,数字型又可以细分为离散型和连续型,因为离散与连续的数据分布显著不同,我们可以对其进行分开处理。数字型之间各个列常存在量纲差异,有的数据可能很大,有的数据可能很小,我们需要去除数据量纲,防止模型对数据较大的列进行偏倚(数据值较大时通常方差也较大)。常用的数据去量纲的方法有***最小值归一化法,均值标准差标准化法等等。
数据格式不对
我们期望数据格式是表结构,矩阵格式,或者是张量格式。然而我们拿到的数据往往不是格式化的数据,比如机台的日志数据,图像数据,音频视频数据。我们需要对上述数据转换,把数据格式转换成我们想要的格式。
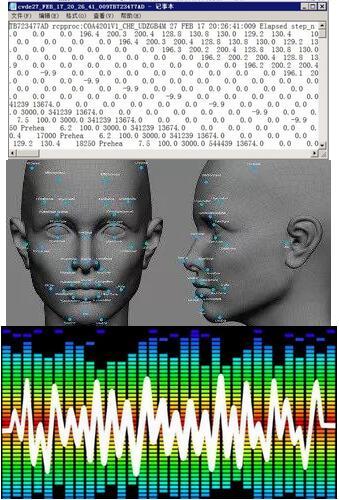
图4
数据中存在异常
数据中还会出现缺失值,异常值等异常,这些情况也会强烈影响到模型的训练,我们需要对空值进行补值。如何补值需要我们对数据非常了解,才能推断出该用什么值来补值,才不会改变原有的数据分布。一般的补值方法有:0值补值,均值补值,中位数补值,按上一个数补值,移动平均补值,线性插值,相关列补值法等等,对于缺失值比例较大的列,可以采取直接删除的方法。异常值则需要创建规则,对异常值进行识别,再用正常的值进行替换,故异常值也有类似于缺失值的替换方法。
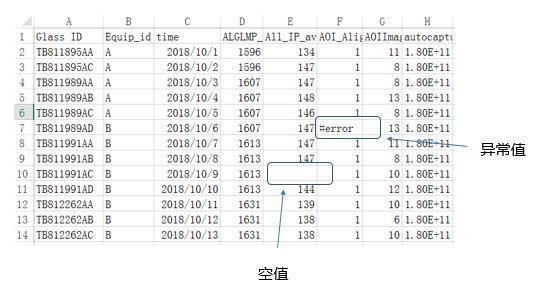
图5













