内存不过是计算机分级存储系统中的靠近cpu的一个存储介质
1.spark运行起来内存里都存的啥?
2.如何管理里面所存的东西?
3.spark用java和scala这样的jvm语言写的,没有像c语言那样显式申请释放内存,如何进行内存的管理的?
4.我们应该如何设置spark关于内存的参数?
一、内存模型
远古大神曾告诉我们这个神秘公式:程序=算法+数据。
1.1 什么是内存模型
内存模型就是告诉我们怎么划分内存、怎么合理利用我们的内存。
首先我们要存什么,根据大神的公式,我们这样来分析:
数据: 就是我们代码操作的数据,比如人的数据(年龄、职位等)或者输入的某个值。这些可在运行时将要计算的部分数据加载到内存。
算法:就是操作数据的逻辑,表现形式就是代码或者编译后的指令。当然它要运行起来,会依赖一部分内存,来储存程序计数器(代码执行到那一句了)、函数调用栈等运行时需要的数据。总而言之就是执行数据操作逻辑所必要的内存。
这下我们就可以把我们需要储存的东西分为数据区和执行区。
二、spark内存模型
2.1 spark为啥快
我们都知道spark之所以比mapreduce计算的快,是因为他是基于内存的,不用每次计算完都写磁盘,再读取出来进行下一次计算,spark直接把内存作为数据的临时储存介质。所以mapreduce就没有强调内存管理,而spark需要管理内存。
2.2 spark管理的内存
系统区:spark运行自身的代码需要一定的空间。
用户区:我们自己写的一些udf之类的代码也需要一定的空间来运行。
存储区:spark的任务就是操作数据,spark为了快可能把数据存内存,而这些数据也需要占用空间。
执行区:spark操作数据的单元是partition,spark在执行一些shuffle、join、sort、aggregation之类的操作,需要把partition加载到内存进行运算,这也会运用到部分内存。
2.3 spark内存模型
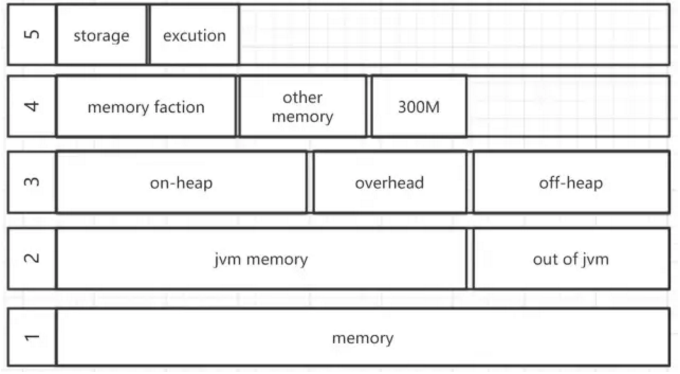
上图就是spark内存划分的图了
我们从下到上一层一层的解释:
第1层:整个excutor所用到的内存
第2层:分为jvm中的内存和jvm外的内存,这里的jvm内存在yarn的时候就是指申请的container的内存
第3层:对于spark来内存分为jvm堆内的和memoryoverhead、off-heap
jvm堆内的下一层再说
memoryOverhead: 对应的参数就是spark.yarn.executor.memoryOverhead 这块内存是用于虚拟机的开销、内部的字符串、还有一些本地开销(比如python需要用到的内存)等。其实就是额外的内存,spark并不会对这块内存进行管理。
off-heap : 这里特指的spark.memory.offHeap.size这个参数指定的内存(广义上是指所有堆外的)。这部分内存的申请和释放是直接进行的不通过jvm管控所以没有GC,被spark分为storage和excution两部分和第5层讲的一同被spark统一进行管理。
第4层:jvm堆内的内存分为三个部分
reservedMemory: 预留内存300M,用于保障spark正常运行
other memory: 用于spark内部的一些元数据、用户的数据结构、防止出现对内存估计不足导致oom时的内存缓冲、占用空间比较大的记录做缓冲
memory faction: spark主要控制的内存,由参数spark.memory.fraction控制。
第5层:分成storage和execution 由参数spark.memory.storageFraction控制它两的大小,但是
execution: 用于spark的计算:shuffle、sort、aggregation等这些计算时会用到的内存,如果计算是内存不足会向storage部分借,如果还是不够就会spill到磁盘。
storage: 主要用于rdd的缓存,如果execution来借内存,可能会牺牲自己丢弃缓存来借给execution,storage也可以向execution借内存,但execution不会牺牲自己。
三、源码层面
3.1 整体架构
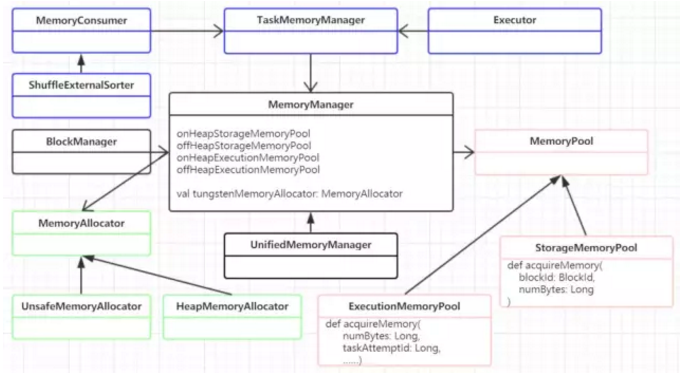
- 内存申请和释放(绿色):
看上图绿色那块,就是内存的申请和释放模块。MemoryAllocator接口负责内存申请,有两个子类实现分别负责堆内内存和off-heap内存。
- 内存池(粉色):
MemoryPool内存池有两个子类分别管理着执行内存和储存内存。可以看到两种内存池的申请方法的参数有很明显的区别,执行内存主要是面向task的,而储存内存主要是面向block的也就是用于rdd缓存呀啥的。
- 统一内存管理:
MemoryManager负责记录内存的消耗,管理这4个内存池,子类UnifiedMemoryManager负责把这执行内存和储存内存统一起来管理,实现相互借用之类的功能。
- MemoryManager的使用场景
一个是BlockManager用于管理储存,还有一部分是运行Task是的内存使用,主要有executor的使用,shuffle时spill呀外部排序呀,这样的场景。
3.2 如何实现内存申请释放。
spark是用scala和java实现的,印象中没有管理内存申请释放的api,spark是如何利用这些jvm语言管理内存的呢。
我们来看看源码片段
- //HeapMemoryAllocator.scalaprivate final Map<Long, LinkedList<WeakReference<long[]>>> bufferPoolsBySize = new HashMap<>();
- …… public MemoryBlock allocate(long size) throws OutOfMemoryError {
- …… 上面是些内存的判断 …… long[] array = new long[numWords];//上面这就很关键了
- MemoryBlock memory = new MemoryBlock(array, Platform.LONG_ARRAY_OFFSET, size); if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
- memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
- } return memory;
- }
HeapMemoryAllocator可以看到上面的源码片段,实际的内存申请是这个代码:new long[numWords]; 就是new了个数组来占着内存,用MemoryBlock 包装了一下。bufferPoolsBySize这个是为了防止内存频繁申请和释放做的buffer。
接下来看看off-heap是怎么申请内存的。
- //UnsafeMemoryAllocator
- public MemoryBlock allocate(long size) throws OutOfMemoryError { long address = Platform.allocateMemory(size);
- MemoryBlock memory = new MemoryBlock(null, address, size); if (MemoryAllocator.MEMORY_DEBUG_FILL_ENABLED) {
- memory.fill(MemoryAllocator.MEMORY_DEBUG_FILL_CLEAN_VALUE);
- } return memory;
- }
offheap的就和C语言一样的了可以直接使用api来申请。这部分内存就需要自己进行管理了,没有jvm的控制,没有内存回收机制。
当然这也不意味了你能***制的使用内存,在yarn的情况下,yarn是监测子进程的内存占用来看你是否超了内存,如果超了直接kill掉。
四、总结
我们能回答开头提出的几个问题了吗?还是又有了更多的问题呢。