












引言:隐形T恤
在威廉•吉布森的科幻小说《零历史》中有这么一个情节:有人发明了一件奇丑无比的T恤,其神奇之处在于,这是一件能在监控摄像下“隐身”的衣服——只要穿上这件T恤,就能神乎其技地躲开监控,去做一些见不得光的事情……
在现实世界中,这已经不完全是科幻概念了。在目前的AI攻防研究中,这种监控摄像下的“隐形T恤”已经有了具体的表现。其出现的主要原因是AI算法设计的时候未充分考虑相关的安全威胁,使得AI算法的预测结果容易受恶意攻击者的影响,导致AI系统判断失误。
可见,AI在改变人类命运的同时,也同样存在安全风险。这样的安全风险可以体现在医疗、交通、工业、监控、政治等众多领域。犯罪分子通过恶意攻击来“蒙蔽”AI,甚至可能进行扰乱政治选举、传播黄暴恐、蓄意谋杀等重大犯罪活动。
因此,AI安全不容忽视,特别是来自于外部攻击导致的AI模型风险,比如对抗样本攻击可以诱导AI模型进行错误的判断,输出错误的结果。本文主要针对这一问题进行分析。
1.什么是对抗样本?
对抗样本(adversarial examples),最早由Szegedy等人[1]在2013年提出。它是指通过给输入图片加入人眼难以察觉的微小扰动,使得正常的机器学习模型输出错误的预测结果。如图1所示,输入一张熊猫图片,正常的深度神经网络可以正确地将其识别为“panda (熊猫)”。但是有针对性地给它加上一层对抗干扰后,同一个深度神经网络将其识别为“cocktail shaker (鸡尾酒调酒器)”, 如图2所示。
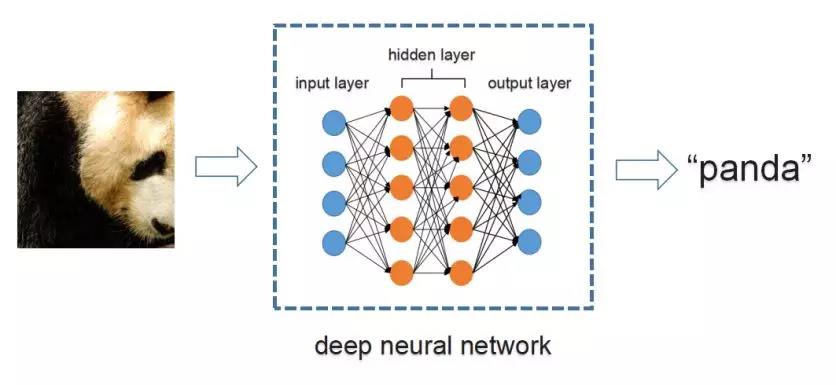
图1. 正常图片识别
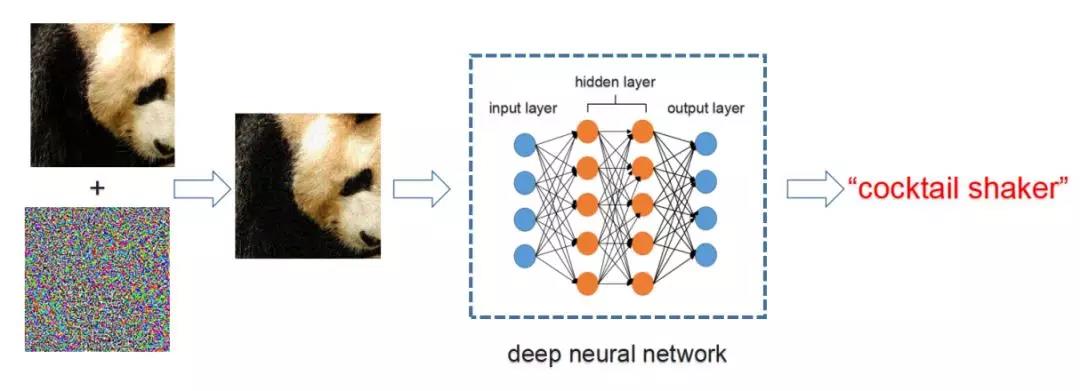
图2. 对抗样本攻击
那么对抗样本出现的原因是什么呢?主要有两个原因导致对抗样本的出现:
(1)首先,基于深度学习的神经网络模型可学习的参数有限,导致神经网络的表达能力有限,无法覆盖所有图像的可变空间。而且目前用于训练神经网络的数据集相对于整个自然场景图像的空间来说,依然只占很小一部分空间,因此可能存在这样一类与自然图像中的样本很相似的样本,人眼无法察觉到它们的差异,但是神经网络将其识别错误。
(2)其次,神经网络中的高维线性变换导致对抗样本[2]。例如,假设存在样本x和网络权重W,对样本x加入微小的干扰η来构建对抗样本,即
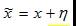
,对于线性变换
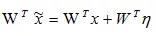
,WTη为噪声的线性积累,当线性变换的权重W与噪声η 的方向一致或完全相反时,导致这两者的点积最大或最小,导致输出超出正常范围,最终导致神经网络预测错误。
因此,对抗样本并不是将随机产生的噪声叠加到正常的样本上就可以使模型识别错误,而是与模型的参数W有关。对抗样本是一种被恶意设计来攻击机器学习算法模型的样本。
一般来说,对抗样本攻击可以分为有目标攻击(targeted attacks)和无目标攻击(non-targeted attacks)。所谓有目标攻击,即给定目标类别,修改输入图片,使神经网络将其识别为目标类别。而无目标攻击,只需要修改图片使其类别发生改变即可。
对抗样本攻击还可以分为白盒攻击(white-box attacks)与黑盒攻击(black-box attacks)。其中白盒攻击是指攻击者能够能够获知机器学习所使用的算法以及算法所使用的参数,攻击者在生成对抗样本的过程中可以与机器学习系统有所交互。而黑盒攻击是指攻击者并不知道机器学习所使用的算法模型或参数。
2.对抗样本是怎样生成的?
2.1 优化目标
近年来,对抗样本的生成算法得到了快速发展,其中利用模型参数最大化模型分类损失的方法最为常用。该方法的总体分类目标可以定义为:给定模型y = f ( x, W )(其中W为模型参数,x为模型输入,f ( x, W )为输入到输出的映射),对抗样本
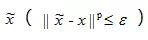
可以定义为:
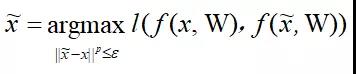
其中l (·, ·)为损失函数,刻画原始样本输出和对抗样本输出的差异。可以使用梯度上升(gradient ascent)的方法来解决该最大化优化问题。
2.2 FGSM
Goodfellow等人[2]提出了一种名为Fast Gradient Sign Method(FGSM)的快速优化方法,定义如下:
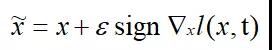
其中t为x的类别。该方法首先计算损失函数针对输入的梯度,再取符号函数,最后加入扰动因子 ε 即可以得到对抗样本。简单有效,仅需一步迭代。但是这种对抗样本生成方法的白盒攻击成功率较低,因为在大多数情况下无法通过一步迭代有效提升损失函数。
2.3 BIM
为了解决白盒攻击成功率较低的问题,Kurakin等人[3]提出了一种名为Basic Iterative Method(BIM)的方法, 其定义如下:
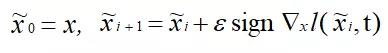
该方法通过多次迭代的方法最大限度地增大损失函数,能够增加白盒模型的识别错误率。但是BIM的黑盒攻击成功率比FGSM低,迁移性较差,因为BIM容易在白盒模型上过拟合。
2.4 我们的方法:TAP
为了解决多步迭代方法容易过拟合的问题,我们提出了一种新的对抗样本生成方法:Transferable Adversarial Perturbations (TAP),定义如下:
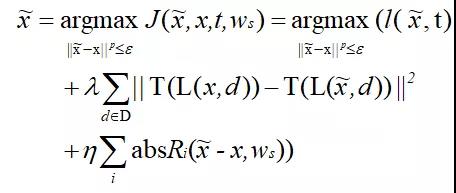
该方法主要进行了两项优化:(1)加入特征距离来最大化原始样本与对抗样本高层特征之间的距离;(2)加入正则项来移除高频噪声,保留迁移性强的扰动。算法1阐述了使用TAP方法生成对抗样本的详细流程:

图3展示了分别使用FGSM、BIM和TAP方法针对Inception V3网络生成的对抗样本。为了直观地验证对抗样本的影响,我们对黑盒模型所提取的特征进行了可视化。细节来说,我们使用Inception V3来生成对抗样本,然后使用Inception V4对生成的对抗样本进行特征提取,从倒数第二层提取了1536维特征。接着,我们使用t-SNE对1536维特征进行降维,得到一个三维的特征表示,可视化效果如图4所示。由图4可知,我们的方法生成的对抗样本与原始图片之间的距离大于使用FGSM和BIM方法生成的对抗样本与原始图片之间的距离,证明用我们的方法在Inception V3上生成的对抗干扰将以更高的概率迁移到Inception V4的特征空间上。

(a)FGSM (b) BIM (d) TAP
图3.对抗样本生成示例
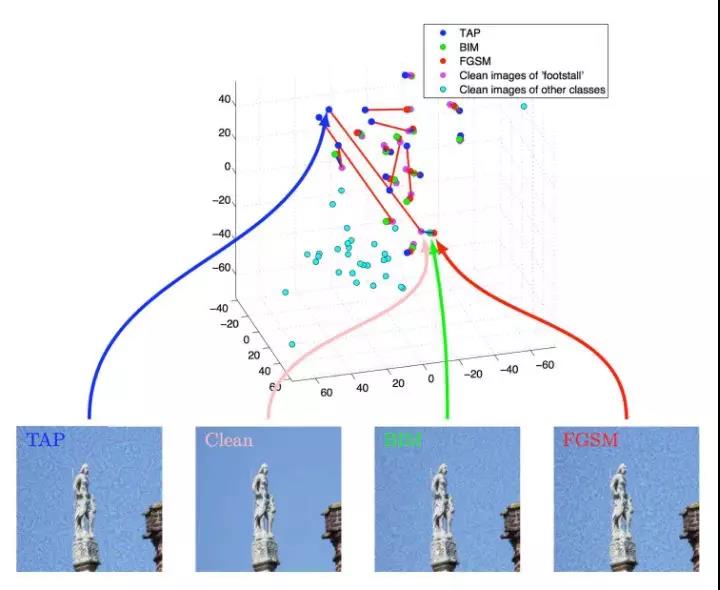
图4. t-SNE可视化特征距离
我们关于对抗样本生成的相关成果已经发表于ECCV 2018 [4],在此次CanSecWest会议中,我们也对这项工作进行了简单的介绍。
3.如何使用对抗样本来欺骗AI?
当AI被“蒙蔽”,坏人能够做哪些事?我们使用对抗样本对人脸识别、目标检测、交通指示标识别、色情识别等多个应用进行了实验。
3.1人脸识别
在人脸识别攻击的实验中,我们尝试将Trump的图片修改为Merkel,从男性更改为女性。图5展示了我们对人脸识别网络的攻击过程,具体流程如下:
Step 1. 收集N张目标人物(Merkel)的人脸图片,使用人脸检测网络对N张图片进行人脸检测和裁剪,然后送入人脸识别网络进行特征提取,将得到N个特征表示{ f 1,f2,。。。,f N}
Step 2. 将攻击图片也进行人脸提取、裁剪和特征提取,将得到人脸特征f x;
Step 3. 计算loss来度量特征相似度;
Step 4. 通过梯度上升多次迭代最大化loss,生成对抗样本;
Step 5. 将生成的人脸对抗样本叠加到原始图片中的人脸区域。
3.2 目标检测
我们也对目标检测网络Faster R-CNN [7] 进行了攻击实验。目标检测网络以待检测的图片为输入,输出前景目标的坐标和类别,如人、马、狗、汽车等。一般目标检测网络的损失函数包含定位和分类两部分。在这个实验中,我们仅考虑了分类损失,因为我们发现分类失败能更大概率影响目标检测的结果。图8展示了目标检测攻击的结果,原本能够精准定位和分类的前景目标的坐标和类别都发生了改变,说明针对目标分类的噪声也可以迁移到目标定位。

(a)原始图片

(b)对抗样本图
8. 目标检测攻击
3.3 交通指示牌识别
图9展示了我们对交通指示牌识别网络的攻击样例。目标检测与交通指示牌识别是自动驾驶或辅助驾驶系统常用的两种AI技术,一旦目标检测与交通指示牌识别系统受到攻击,后果将不堪设想(如图10)。

图9. 交通指示牌识别攻击

图10. 辅助驾驶系统
3.4 色情识别
对抗样本同样可以蒙骗色情识别系统。图11显示了使用Google Cloud [8]色情识别系统将修改后的色情图片识别为正常图片。
4.如何防范对抗样本攻击?
针对AI安全对抗样本攻击的防御主要分为三个阶段:数据收集阶段、模型训练阶段、模型使用阶段。图12列出了在各个阶段的各种防御技术。
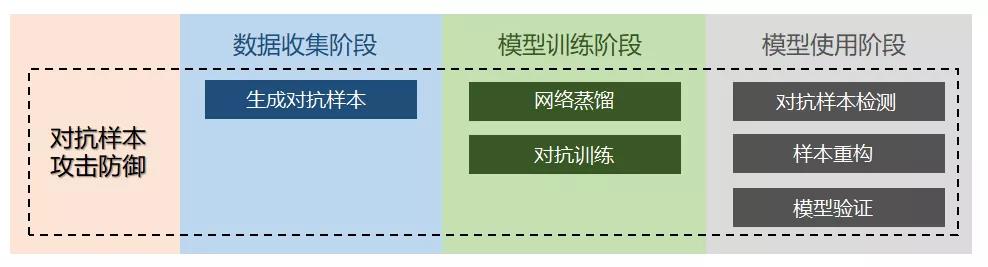
图12. AI安全对抗样本防御技术
生成对抗样本(Adversarial Example Generation):该方法是指在模型训练之前进行数据收集阶段,使用各种已知的攻击方法和网络模型生成对抗样本,作为数据的一部分。一般而言,生成的对抗样本的方法和模型类型越多,样本的变化越大,越有利于训练生成鲁棒的模型。
网络蒸馏(Network Distillation):该方法的基本原理是指在模型训练阶段,对多个神经网络进行串联,其中前一个大网络的训练结果被作为“软标签”去训练后一个小网络。相关研究[9]发现迁移知识可以在一定程度上降低模型对微小扰动的敏感度,提高AI模型的鲁棒性。
对抗训练(Adversarial Training):该方法是指在模型训练过程中将在数据收集阶段生成的各种各样的对抗样本加入训练集中,对模型进行单次或多次训练,可以生成可以抵抗对抗干扰的对抗模型。该方法不仅可以增强新生成模型的鲁棒性,还可以增强模型的准确率。
对抗样本检测(Adversarial Example Detection):该方法的基本原理是指在模型使用阶段加入对抗样本检测模块来判断输入的样本是否为对抗样本。可以是在输入样本到达原模型之前进行对抗样本检测,也可以是从原模型内部提取信息来进行判断。例如,输入样本和正常数据之间的差异性可以作为判断标准,也可以简单地训练一个基于神经网络的二分类模型来进行对抗样本检测。
样本重构(Example Reconstruction):样本重构是指将对抗样本恢复为正常样本。通过这样的转换后,对抗样本将不对网络预测的结果产生影响。样本重构最常用的方法是对输入的对抗样本进行降噪,即使用降噪网络将对抗样本转换为正常样本,或是直接在原模型网络架构中加入降噪模块。
模型验证(Model Verification):模型验证是指检查神经网络的属性,验证输入是否违反或满足属性要求。该方法是防御对抗样本攻击很有希望的一种防御技术,因为它可以检测未曾见过的对抗样本攻击。
然而,以上的防御措施都有特定的应用场景,并不能防御所有的对抗样本攻击,特别是一些攻击性较强的、未曾出现过的对抗样本攻击。此外,也可以并行或串行整合多种防御方法,增强AI模型的防御能力。目前,大多数防御方法都是针对计算机视觉中的对抗样本,随着其他领域的对抗样本的发展,比如语音,迫切需要针对这些领域的对抗样本攻击的防御方法。
总结
AI扩宽了人类解决问题的边界,但是也暴露了各种各样的安全性问题。本文剖析了AI系统极易受到对抗样本的攻击,并且现有的防御技术并不能完全防御这样的攻击。一旦AI系统被恶意攻击,轻则造成财产损失,重则威胁人身安全。AI应用的大规模普及和发展需要很强的安全性保证,因此,我们还需要持续提升AI安全、提升AI算法的鲁棒性。安平AI安全研究团队也会在这个领域不断深耕,助力AI事业发展。
参考文献
Szegedy, Christian, et al. "Intriguing properties of neural networks." Computer Science (2013).
Goodfellow, Ian J., J. Shlens, and C. Szegedy. "Explaining and Harnessing Adversarial Examples." Computer Science (2015).
Kurakin, Alexey, I. Goodfellow, and S. Bengio. "Adversarial examples in the physical world." (2016).
Zhou, W., Hou, X., Chen, Y., Tang, M., Huang, X., Gan, X., & Yang, Y. (2018). Transferable Adversarial Perturbations. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 452-467).
https://console.aws.amazon.com/rekognition/home?region=us-east-1#/celebrity-detection
https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/
Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (pp. 91-99).
https://cloud.google.com/vision/
Papernot, N., McDaniel, P., Wu, X., Jha, S., & Swami, A. (2016, May). Distillation as a defense to adversarial perturbations against deep neural networks. In 2016 IEEE Symposium on Security and Privacy (SP) (pp. 582-597). IEEE.
【本文为51CTO专栏作者“腾讯技术工程”原创稿件,转载请联系原作者(微信号:Tencent_TEG)】
戳这里,看该作者更多好文

















