概述
在多核系统中,为了更好的利用多CPU并行能力,进程调度器可以将进程负载尽可能的平均到各个CPU上。再具体实现中,如何选择将进程迁移到的目标CPU,除了考虑各个CPU的负载平衡,还需要将Cache利用纳入权衡因素。同时,对于进程A唤醒进程B这个模型,还做了特殊的处理。本文分析以Centos kernel 3.10.0-975源码为蓝本。
SMP负载均衡模型
问题
如果只是将CPU负载平均的分布在各个CPU上,那么就无所谓需要调度域。但是由于Cache以及内存Numa的存在,使得进程最好能迁移到与之前运行所在CPU更'近'的CPU上。
以我们常用的Intel X86为例。Cache基本视图如下图:
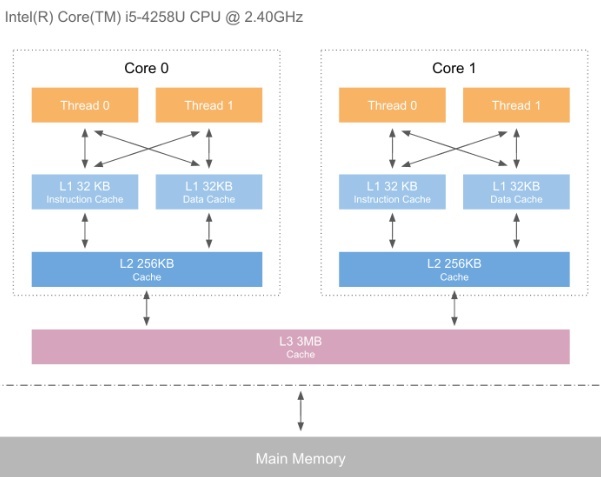
从Cache和内存访问的视角,如果进程负载均衡需要把进程A迁移到另一个CPU上,
- 如果目标CPU和进程A之前所在CPU正好是同一个物理CPU同一个核心上(超线程),那么Cache利用率最好,毕竟L1,L2和L3中还是'热'的。
- 如果目标CPU和进程A之前所在CPU正好是同一个物理CPU但不同核心上(多核),那么Cache利用率次之,L3中还有'热'数据。
- 如果目标CPU和进程A之前所在CPU正好是同一个NUMA但是不同物理CPU上(多NUMA结构),虽然Cache已经是'冷'了,但至少内存访问还是在本NUMA中。
- 如果目标CPU和进程A之前所在CPU在不同NUMA中,不但Cache是'冷'的,跨NUMA内存还有惩罚,此时内存访问速度最差。
SMP组织
为了更好地利用Cache,内核将CPU(如果开启了超线程,那么以逻辑CPU为单位,否则以物理CPU核心为单位)组织成了调度域。
逻辑视角
假设某机器为2路4核8核心CPU,它的CPU调度域逻辑上如下图:
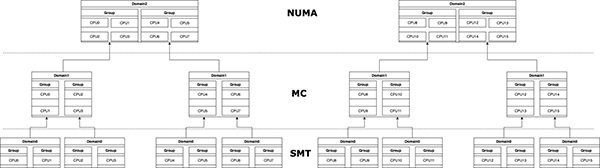
2路NUMA最为简单,如果是4路NUMA,那么这个视图在NUMA层级将会复杂很多,因为跨NUMA访问根据访问距离导致访问延时还不相同,这部分最后讨论。
分层视角
所有CPU一共分为三个层次:SMT,MC,NUMA,每层都包含了所有CPU,但是划分粒度不同。根据Cache和内存的相关性划分调度域,调度域内的CPU又划分一次调度组。越往下层调度域越小,越往上层调度域越大。进程负载均衡会尽可能的在底层调度域内部解决,这样Cache利用率最优。
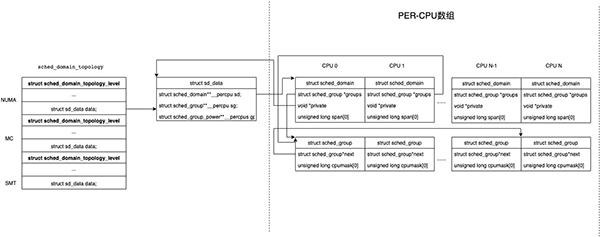
从分层的视角分析,下图是调度域实际组织方式,每层都有per-cpu数组保存每个CPU对应的调度域和调度组,它们是在初始化时已经提前分配的内存。值得注意的是
- 每个CPU对应的调度域数据结构都包含了有效的内容,比如说SMT层中,CPU0和CPU1对应的不同调度域数据结构,内容是一模一样的。
- 每个CPU对应的调度组数据结构不一定包含了有效内容,比如说MC层中,CPU0和CPU1指向不同的struct sched_domain,但是sched_domain->groups指向的调度组确是同样的数据结构,这些调度组组成了环。
单CPU视角
从单个CPU的视角分析,下图是调度域实际组织方式。
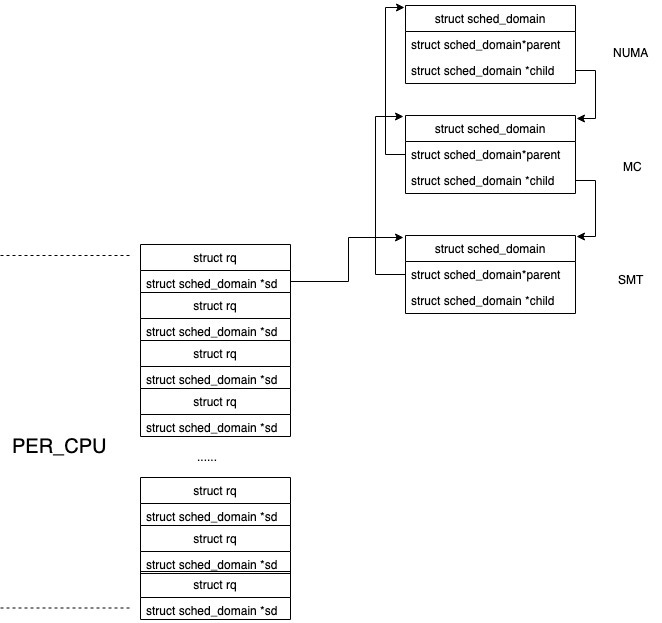
每个CPU的进程运行队列有一个成员指向其所在调度域。从最低层到最高层。
我们可以在/proc/sys/kernel/sched_domain/cpuX/ 中看到CPU实际使用的调度域个数以及每个调度域的名字和配置参数。
负载均衡时机
- 周期性调用进程调度程序scheduler_tick()->trigger_load_balance()中,通过软中断触发负载均衡。
- 某个CPU上无可运行进程,__schedule()准备调度idle进程前,会尝试从其它CPU上pull一批进程过来。
周期性负载均衡
CPU对应的运行队列数据结构中记录了下一次周期性负载均衡的时间,当超过这个时间点后,将触发SCHED_SOFTIRQ软中断来进行负载均衡。
- void trigger_load_balance(struct rq *rq, int cpu)
- {
- /* Don't need to rebalance while attached to NULL domain */
- if (time_after_eq(jiffies, rq->next_balance) &&
- likely(!on_null_domain(cpu)))
- raise_softirq(SCHED_SOFTIRQ);
- #ifdef CONFIG_NO_HZ_COMMON
- if (nohz_kick_needed(rq) && likely(!on_null_domain(cpu)))
- nohz_balancer_kick(cpu);
- #endif
- }
以下是rebalance_domains()函数核心流程,值得注意的是,每个层级的调度间隔不是固定的,而是临时计算出来,他在一个可通过proc接口配置的最小值和最大值之间。
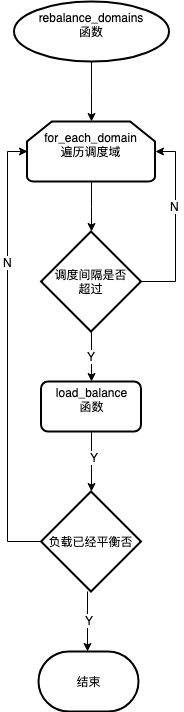
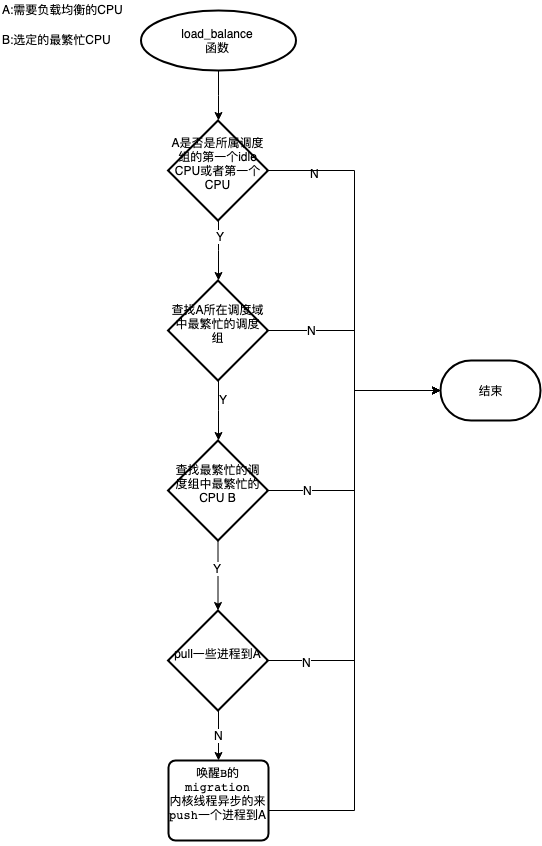
以下是对CPU的每个层级调度域调用load_balance()函数核心流程,目的是把一些进程迁移到指定的CPU(该场景就是当前CPU)。
以我的服务器为例,观察不同层级调度域的调度间隔范围,时间单位为jiffies。
|
Level |
min_interval |
max_interval |
|---|---|---|
|
SMT |
2 |
4 |
|
MC |
40 |
80 |
|
NUMA |
80 |
160 |
可见,SMT负载均衡频率最高,越往上层越低。这也符合体系结构特点,在越低层次迁移进程代价越小(Cache利用率高),所以可以更加频繁一点。
CPU进入idle前负载均衡
当进程调度函数__schedule()把即将切换到idle进程前,会发生一次负载均衡来避免当前CPU空闲。
- static void __sched __schedule(void)
- {
- ...
- if (unlikely(!rq->nr_running))
- idle_balance(cpu, rq);
- ...
- }
核心函数idle_balance()。基本上也是尽可能在低层调度域中负载均衡。
- /* * idle_balance is called by schedule() if this_cpu is about to become * idle. Attempts to pull tasks from other CPUs. */
- void idle_balance(int this_cpu, struct rq *this_rq)
- {
- unsigned long next_balance = jiffies + HZ;
- struct sched_domain *sd;
- int pulled_task = 0;
- u64 curr_cost = 0;
- this_rq->idle_stamp = rq_clock(this_rq);
- /* 如果该CPU平均空闲时间小于/proc中的配置值或者该cpu调度域中所有cpu都是idle状态,那么不需要负载均衡了*/
- if (this_rq->avg_idle < sysctl_sched_migration_cost ||
- !this_rq->rd->overload) {
- rcu_read_lock();
- sd = rcu_dereference_check_sched_domain(this_rq->sd);
- if (sd)
- update_next_balance(sd, 0, &next_balance);
- rcu_read_unlock();
- goto out;
- }
- /* * Drop the rq->lock, but keep IRQ/preempt disabled. */
- raw_spin_unlock(&this_rq->lock);
- update_blocked_averages(this_cpu);
- rcu_read_lock();
- /* 从底向上遍历调度域,只要迁移成功一个进程就跳出循环*/
- for_each_domain(this_cpu, sd) {
- int should_balance;
- u64 t0, domain_cost;
- if (!(sd->flags & SD_LOAD_BALANCE))
- continue;
- /* * 如果(当前累积的负载均衡开销时间 + 历史上该层级负载均衡开销最大值)已经大于CPU平均空闲时间了, * 那么就没有必要负载均衡了。注意,sd->max_newidle_lb_cost会在load_balance()函数中缓慢减少。 */
- if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) {
- update_next_balance(sd, 0, &next_balance);
- break;
- }
- /* 我的机器上该标记总是设置了SD_BALANCE_NEWIDLE */
- if (sd->flags & SD_BALANCE_NEWIDLE) {
- t0 = sched_clock_cpu(this_cpu);
- pulled_task = load_balance(this_cpu, this_rq,
- sd, CPU_NEWLY_IDLE,
- &should_balance);
- domain_cost = sched_clock_cpu(this_cpu) - t0;
- if (domain_cost > sd->max_newidle_lb_cost)
- sd->max_newidle_lb_cost = domain_cost;
- /* 记录了当前负载均衡开销累计值 */
- curr_cost += domain_cost;
- }
- update_next_balance(sd, 0, &next_balance);
- /* * Stop searching for tasks to pull if there are * now runnable tasks on this rq. */
- if (pulled_task || this_rq->nr_running > 0) {
- this_rq->idle_stamp = 0;
- break;
- }
- }
- rcu_read_unlock();
- raw_spin_lock(&this_rq->lock);
- out:
- /* Move the next balance forward */
- if (time_after(this_rq->next_balance, next_balance))
- this_rq->next_balance = next_balance;
- if (curr_cost > this_rq->max_idle_balance_cost)
- this_rq->max_idle_balance_cost = curr_cost;
- }
其它需要用到SMP负载均衡模型的时机
内核运行中,还有部分情况中需要用掉SMP负载均衡模型来确定最佳运行CPU:
- 进程A唤醒进程B时,try_to_wake_up()中会考虑进程B将在哪个CPU上运行。
- 进程调用execve()系统调用时。
- fork出子进程,子进程第一次被调度运
唤醒进程时
当A进程唤醒B进程时,假设都是普通进程,那么将会调用try_to_wake_up()->select_task_rq()->select_task_rq_fair()
- /* * sched_balance_self: balance the current task (running on cpu) in domains * that have the 'flag' flag set. In practice, this is SD_BALANCE_FORK and * SD_BALANCE_EXEC. * * Balance, ie. select the least loaded group. * * Returns the target CPU number, or the same CPU if no balancing is needed. * * preempt must be disabled. */
- /* A进程给自己或者B进程选择一个CPU运行, * 1: A唤醒B * 2: A fork()出B后让B运行 * 3: A execute()后重新选择自己将要运行的CPU */
- static int
- select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
- {
- struct sched_domain *tmp, *affine_sd = NULL, *sd = NULL;
- int cpu = smp_processor_id();
- int new_cpu = cpu;
- int want_affine = 0;
- int sync = wake_flags & WF_SYNC;
- /* 当A进程唤醒B进程时,从try_to_wake_up()进入本函数,这里会置位SD_BALANCE_WAKE。 */
- if (sd_flag & SD_BALANCE_WAKE) {
- /* B进程被唤醒时希望运行的CPU尽可能离A进程所在CPU近一点 */
- if (cpumask_test_cpu(cpu, tsk_cpus_allowed(p)))
- want_affine = 1;
- new_cpu = prev_cpu;
- record_wakee(p);
- }
- rcu_read_lock();
- /* * 如果是A唤醒B模式,则查找同时包含A所在cpu和B睡眠前所在prev_cpu的最低级别的调度域。因为A进程 * 和B进程大概率会有某种数据交换关系,唤醒B时让它们所在的CPU离的近一点会性能最优。 * 否则,查找包含了sd_flag的最高调度域。 */
- for_each_domain(cpu, tmp) {
- if (!(tmp->flags & SD_LOAD_BALANCE))
- continue;
- /* * If both cpu and prev_cpu are part of this domain, * cpu is a valid SD_WAKE_AFFINE target. */
- if (want_affine && (tmp->flags & SD_WAKE_AFFINE) &&
- cpumask_test_cpu(prev_cpu, sched_domain_span(tmp))) {
- affine_sd = tmp;
- break;
- }
- if (tmp->flags & sd_flag)
- sd = tmp;
- }
- /* 如果是A唤醒B模式,则在同时包含A所在cpu和B睡眠前所在prev_cpu的最低级别的调度域中寻找合适的CPU */
- if (affine_sd) {
- /* * wake_affine()计算A所在CPU和B睡眠前所在CPU的负载值,判断出B进程唤醒时是否 * 需要离A近一点。 */
- if (cpu != prev_cpu && wake_affine(affine_sd, p, sync))
- prev_cpu = cpu;
- /* 在与prev_cpu共享LLC的CPU中寻找空闲CPU,如果没有找到,则返回prev_cpu。这里将确定 * B进程唤醒后在哪个CPU运行。 */
- new_cpu = select_idle_sibling(p, prev_cpu);
- goto unlock;
- }
- /* 到这里,A进程和B进程基本是没有啥亲缘关系的。不用考虑两个进程的Cache亲缘性 */
- while (sd) {
- int load_idx = sd->forkexec_idx;
- struct sched_group *group;
- int weight;
- if (!(sd->flags & sd_flag)) {
- sd = sd->child;
- continue;
- }
- if (sd_flag & SD_BALANCE_WAKE)
- load_idx = sd->wake_idx;
- group = find_idlest_group(sd, p, cpu, load_idx);
- if (!group) {
- sd = sd->child;
- continue;
- }
- new_cpu = find_idlest_cpu(group, p, cpu);
- if (new_cpu == -1 || new_cpu == cpu) {
- /* Now try balancing at a lower domain level of cpu */
- sd = sd->child;
- continue;
- }
- /* Now try balancing at a lower domain level of new_cpu */
- cpu = new_cpu;
- weight = sd->span_weight;
- sd = NULL;
- for_each_domain(cpu, tmp) {
- if (weight <= tmp->span_weight)
- break;
- if (tmp->flags & sd_flag)
- sd = tmp;
- }
- /* while loop will break here if sd == NULL */
- }
- unlock:
- rcu_read_unlock();
- return new_cpu;
- }
- /* * Try and locate an idle CPU in the sched_domain. */
- /* 寻找离target CPU最近的空闲CPU(Cache或者内存距离最近)*/
- static int select_idle_sibling(struct task_struct *p, int target)
- {
- struct sched_domain *sd;
- struct sched_group *sg;
- int i = task_cpu(p);
- /* target CPU正好空闲,自己跟自己当然最近*/
- if (idle_cpu(target))
- return target;
- /* * If the prevous cpu is cache affine and idle, don't be stupid. */
- /* * p进程所在的CPU跟target CPU有Cache共享关系(SMT,或者MC层才有这个关系),并且是空闲的,那就用它了。 * Cache共享说明距离很近了 */
- if (i != target && cpus_share_cache(i, target) && idle_cpu(i))
- return i;
- /* * Otherwise, iterate the domains and find an elegible idle cpu. */
- /* * 在与target CPU有LLC Cache共享关系的调度域中寻找空闲CPU。注意,在X86体系中只有SMT和MC层的调度域才有Cache共享。 */
- sd = rcu_dereference(per_cpu(sd_llc, target));
- /* 在我的机器上是按MC,SMT调度域顺序遍历 */
- for_each_lower_domain(sd) {
- sg = sd->groups;
- do {
- if (!cpumask_intersects(sched_group_cpus(sg),
- tsk_cpus_allowed(p)))
- goto next;
- /* 调度组内所有CPU都是空闲状态,才能选定 */
- for_each_cpu(i, sched_group_cpus(sg)) {
- if (i == target || !idle_cpu(i))
- goto next;
- }
- /* 选择全部CPU都空闲的调度组中第一个CPU*/
- target = cpumask_first_and(sched_group_cpus(sg),
- tsk_cpus_allowed(p));
- goto done;
- next:
- sg = sg->next;
- } while (sg != sd->groups);
- }
- done:
- return target;
- }
调用execve()系统调用时
- /* * sched_exec - execve() is a valuable balancing opportunity, because at * this point the task has the smallest effective memory and cache footprint. */
- void sched_exec(void)
- {
- struct task_struct *p = current;
- unsigned long flags;
- int dest_cpu;
- raw_spin_lock_irqsave(&p->pi_lock, flags);
- /* 选择最合适的CPU,这里由于进程execve()后,之前的Cache就无意义了,因此选择目标CPU不用考虑Cache距离 */
- dest_cpu = p->sched_class->select_task_rq(p, task_cpu(p), SD_BALANCE_EXEC, 0);
- if (dest_cpu == smp_processor_id())
- goto unlock;
- if (likely(cpu_active(dest_cpu))) {
- struct migration_arg arg = { p, dest_cpu };
- raw_spin_unlock_irqrestore(&p->pi_lock, flags);
- stop_one_cpu(task_cpu(p), migration_cpu_stop, &arg);
- return;
- }
- unlock:
- raw_spin_unlock_irqrestore(&p->pi_lock, flags);
- }
fork的子进程第一次被调度运行时
- do_fork()->wake_up_new_task()
- /* * wake_up_new_task - wake up a newly created task for the first time. * * This function will do some initial scheduler statistics housekeeping * that must be done for every newly created context, then puts the task * on the runqueue and wakes it. */
- void wake_up_new_task(struct task_struct *p)
- {
- unsigned long flags;
- struct rq *rq;
- raw_spin_lock_irqsave(&p->pi_lock, flags);
- #ifdef CONFIG_SMP
- /* * Fork balancing, do it here and not earlier because: * - cpus_allowed can change in the fork path * - any previously selected cpu might disappear through hotplug */
- /* 选择最合适的CPU,这里由于进程execve()后,之前的Cache就无意义了,因此选择目标CPU不用考虑Cache距离 */
- set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
- #endif
- /* Initialize new task's runnable average */
- init_task_runnable_average(p);
- rq = __task_rq_lock(p);
- activate_task(rq, p, 0);
- p->on_rq = TASK_ON_RQ_QUEUED;
- trace_sched_wakeup_new(p, true);
- check_preempt_curr(rq, p, WF_FORK);
- #ifdef CONFIG_SMP
- if (p->sched_class->task_woken)
- p->sched_class->task_woken(rq, p);
- #endif
- task_rq_unlock(rq, p, &flags);
- }
SMP负载均衡模型的配置
可以在/proc/sys/kernel/sched_domain/cpuX/中可以对指定CPU所在不同层的调度域进行设置
主要分两类:
- 调度层名字:name
- 调度域支持的特性:设置flags文件值,比如SD_LOAD_BALANCE,SD_BALANCE_NEWIDLE,SD_BALANCE_EXEC等,它将决定上文函数遍历调度域时是否忽略本域。
- 调度域计算参数:其它所有文件。