













在一个阳光明媚的周二下午,我正在公司里面看着即将发布的 Java 12 的新特性,这时候女朋友打来电话。




晚上下班后,女朋友回到家里面和我说,发现淘宝无法访问的十几分钟后又可以了。




系统可用性
系统的可用性,英文名字为 System Usability,即系统服务不中断运行时间占实际运行时间的比例。所以,可用性其实是一个百分比,如 99.9%。
我们通常会听说一个词:高可用,其实指的就是高可用性。高可用指的就是系统服务不中断运行时间占实际运行时间的占比更大。
要了解可用性,躲不开的三个体现系统可用性的重要指标:
- MTTR
- MTTF
- MTBF
MTTR:即 Mean Time To Repair,中文为:平均修复时间,指系统从发生故障到维修结束之间的时间段的平均值。
MTTF:即 Mean Time To Failure,中文为:平均无故障时间。指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。
MTBF:即 Mean Time Between Failure,中文为:平均失效间隔,指系统两次故障发生时间之间的时间段的平均值。
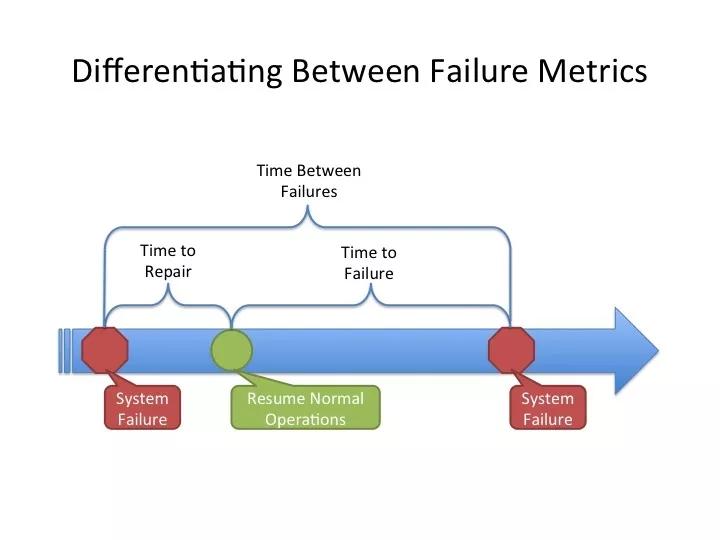
上图,就是一张可以提现三者之间关系的图,可以看出:
- MTBF = MTTF + MTTR
按照以上概念,那么系统的可用性指的其实就是: MTTF / MTBF * 100% ,即 MTTF / ( MTTF + MTTR ) * 100%。





在实际的情况中,很多系统都是由若干个子系统组成的,那么整个系统的可用性到底该如何计算呢?我们接着来了解下系统结构。
对于串联系统:

对于并联系统:
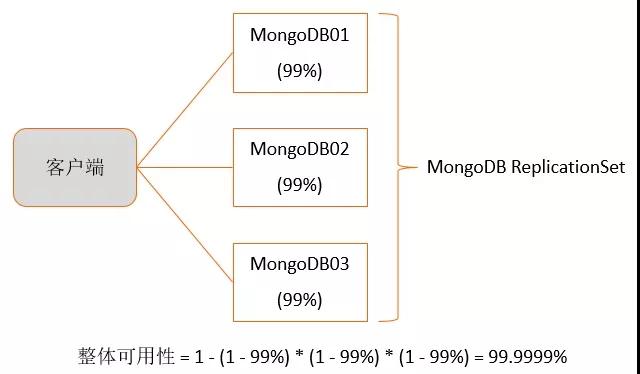
对于组合系统:
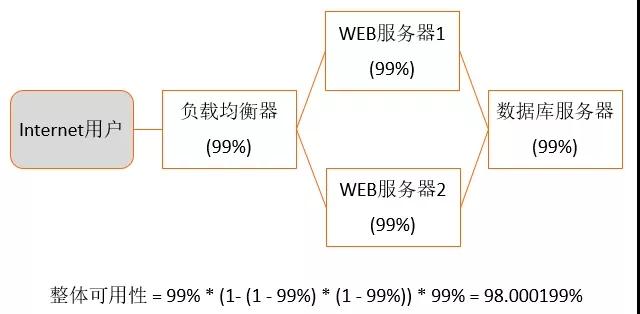



可用性的衡量
衡量系统的高可用性,一般通过 SLA,全称 Service Level Agreement,也就是有几个 9 的高可用性。
我们经常可以看到很多公司会宣称自己的系统可以达到 99.99%、99.999%等。
工业界通常通过统计故障发生到恢复的时间的方法来测量 SLA。一般以年度为单位,统计一年内的系统不可用总时长。
具体对应关系如下表:
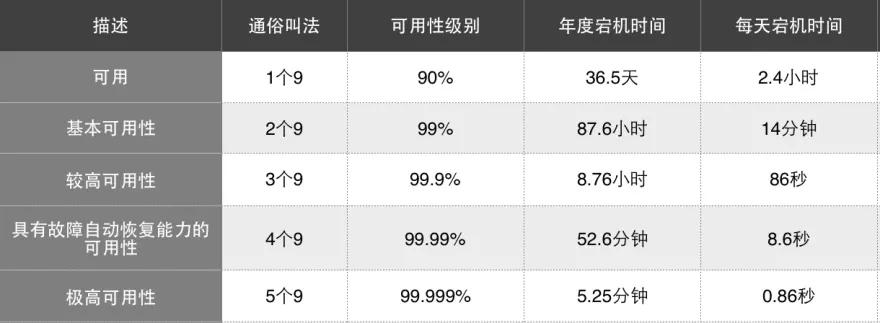
墨菲定律说 “会出错的事总会出错”,可用性做到 100 是可望而不可及的。
对于 SLA 指标来说,9 的数字越多可用性越高,宕机时间越少,系统就可以在给定的时刻内高比例地正常工作。然而对系统的挑战就越大,投入的成本也会越高。
比如 5 个 9 要求系统每年只宕机 5 分钟左右,而 4 个 9 要求每年宕机时间不超过一个小时。
这就使得系统需要在设计、基础设施、数据备份等不同层面采取多种方式,甚至增加基础设施投资来保证可用性。
“当你的设备处理人命关天的事情,或业务中断一分钟就会损失百万美刀,那么你可以考虑 99.99% 的可靠性。”
Robertson(Linux 高可用项目开发者)
不同系统的可用性要求也是不同的,比如:淘宝、京东等这些电商系统用户量很多,不同区不同时刻都有大量的用户在使用系统,这必然对系统的可用性要求很高。
据以往这些系统的故障统计和不准确地测试数据推测,它们目前的可用性是在 3 个 9 到 4 个 9 左右。
相对而言,企业类的工作软件因为通常只在工作时间被使用,或只在某些特定的地区使用,或只给某部分人某一特定时间使用,可用性的需求就会低一些。



可用性的保障
影响可用性的因素有很多,包括系统故障、基础设施故障、数据故障、安全攻击、系统压力等等。
可用性的保障涉及到很多层面,其中包括但不限于:
- 软件的设计、编码、测试、上线和软件配置管理的水平
- 工程师的人员技能水平
- 运维的管理和技术水平
- 数据中心的运营管理水平
- 依赖于第三方服务的管理水平
- 对待技术的态度
- 一个公司的工程文化
- 领导者对工程的尊重
下面的表格里,列出了高可用常见的问题和应对措施:
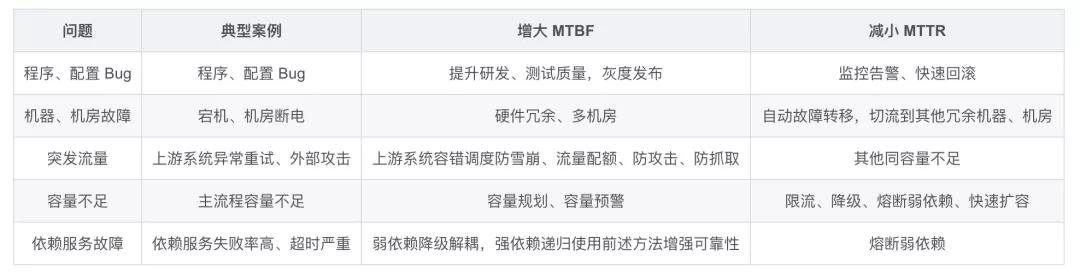
保障系统的高可用,并不是一个简单的事情,上表中列举的也只是其中一部分方法论,真正的保证高可用,还是需要大量实践的!





















