引言:
B+树索引:通过根节点到叶节点逐层寻找,一步一缩小寻找的范围对象,直至找到目标
Hash索引:采用一定的哈希算法,把键值更换成新的哈希值,检索时不需要像B+树那样依次从根节点到叶节点逐层寻找,一次性可以锁定相应的位置,找到目标值。
一、“独具特色”的B+树
B+树即Btree,它的树形结构如同一棵树木,但是倒立的树木。所以我们称之为B+树索引。它的寻找目标值方式依次由根节点到叶节点。
即就是:B+树左右支点都是相同数目的,所以称之为平衡的多叉树,如果分为两个分叉则被称为平衡的二叉树,即以下边树木为例,以中间躯干为中点,左右对称。由根到支点高度为1,任何节点的两个子树的高度为1,即由根到叶节点需要一层指向一层。各个节点之间用指针进行连接。根与叶子之间相连接的躯干被称之为指针。
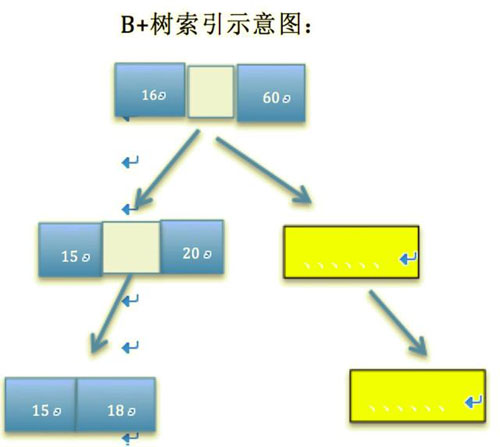
以上两幅对比可以看出,B+树索引就像一棵倒立的树木,树根我们称之为根节点在上方,叶子我们称之为叶节点在下方。根节点连接的左右叶节点是对称的,所以称之为平衡的多叉树。跟与叶子之间的箭头叫做指针,从左边节点分析,可在第一层寻找数值应该在[15,20]之间,在第二层又进行细分,数值在[15,18]之间,以此类推找到目标值。可以看出B+树索引是通过范围来寻找目标值的。
B+树索引的应用场景和不适用场景:
- 适用于数据库,文件系统等场景,因为这些对象都是层层包含的,文件里包含其他文件,需要逐层缩小范围来寻找。
- 支持左右查询,利用的是B+树叶节点的指针是双向的
- 不适用于等值查询
二、“情有独钟”的哈希索引
哈希索引:哈希索引使用的是哈希算法,这里的算法指的是使用一定的函数,即通过寻找键值,来找到所寻找的对象。
哈希算法即散列函数,它就是将明文翻译成一段固定长度的字符串密码,且是单向的。因此采用哈希算法无论你之前明文有多长,经过算法输出后都是固定长度的字符串密码。代表算法有MD5,MD4…..
举个例子:比如说我们在百度上想要搜 佩奇的图片,当没有任何外在的标识情况下,在巨量的图片库里你想要找到佩奇的图片,你觉得是不是很困难。在这种情况下,我们可以通过哈希索引,它会将图片库里的图片转化成一串0-1的编码。这样你就会发现,图片相近编码也会变得很相近。这样我们在百度里一输入“佩奇”这样的编码,就会出来许多张佩奇的图片。这就是所谓的哈希索引。
优点:效率高,可以一次就直接找到目标
哈希索引示意图:

上图说明:当我们在百度中输入“佩奇”作为键值,然后所谓的Hash索引就会在图片库中找到标识符也为“佩奇”的编码,然后就可以搜索出佩奇的图片了。所以它不属于范围搜索。
哈希索引的应用场景和不适合场景:
- 支持等值查询:前提条件没有过多重复的键值,如果存在的话,会降低哈希索引的效率,发生哈希碰撞问题。
- 范围查询则不合适哈希索引
- 哈希索引不能被用来避免数据排序操作
- 哈希索引不支持最左匹配规则,因为键值更换成哈希值是单向的
三、各显神通的B+与哈希
根据上面两种索引的示意图可以得出以下的不同结论:
- Hash索引的效率要高于B+树索引。B+ 树是一个平衡的多叉树,所以从根节点到叶子节点的搜索效率是差不多的,基本不会出现波动,也可以进行顺序扫描,即利用B+树的双向指针可以左右移动,双反方向的查找,效率很高。 Hash 索引,根据键值作为“字符串”,可以一次性的检索到位。不需要像B+树索引一样,由根节点到叶节点一层一层的寻找,所以,Hash 索引的检索效率要高于B+索引。
- 等值查找Hash占优势,一定范为内B+树索引占优势。由于Hash索引是通过键值来查找的,需要键值相等才能够找到所需要的值。不能用于基于某一个范围内的查找,而B+树索引可以实现范围内查找。因此在等键值查找出,Hash 索引优势明显; 在某一范围内查找,B+树索引优势明显。
- B+树效率较均等化,Hash索引发生碰触情况下效率大减。B+树索引由于是(左右)平衡的多叉树,所以在索引过程中效率毕竟均等化,不会出现幅度的大起大落。 而Hash索引,在有大量重复的键值情况下,效率都会很低,因为那么多相同的键值,都会索引,它也不能分清哪个键值背后的存储对象是它所要找的目标,索引就会发生哈希碰撞问题。
- B+树索引更适合数据库的模糊查询。对于像数据库中 select * from [user] where name like’%三%’,查找名字带三的模糊查询,Hash 是无法完成的, 模糊查询本质上也属于范围索引,故在此种情况下,应该使用B+ 树索引。