













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
机器学习里的优化算法很多,比如SGD、Adam、AdaGrad、AdaDelta等等,光是它们的迭代公式就已经够让人头疼。
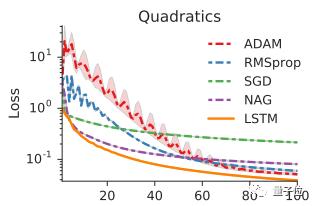
好在TensorFlow、Keras、PyTorch中都集成了这些优化工具,但它们是如何在一步步迭代中“滑落”到最小值的,你真的清楚吗?
现在有一个机器学习优化算法的Demo,能帮你从图像中直观感受到调参对算法结果的影响,以及各自的优缺点。
它就是ensmallen!它的开发者不仅提供了Demo,还给程序员们打包了一份C++数据库,那我们先来试玩一下吧。
试玩Demo
试玩方法很简单,甚至不需要安装任何软件,进入ensmallen网站,选择Demo标签,就能看到一组优化算法的3D示意图。
页面默认是常见的Adam算法,我们会看到参数沿着红色的路线,最终落入损失函数的***点:
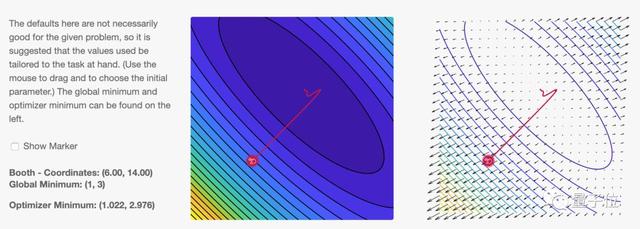
左侧是参数初始值所在位置,也就是图片中的红点,可以用鼠标随意拖动。
中间和右侧的图都是损失函数的“等高线”。中间以不同颜色标记不同高度,右侧直接给出了损失函数的梯度场,以箭头指向表示梯度方向、长度表示梯度大小。可以看出等高线越密集的地方,梯度也越大。
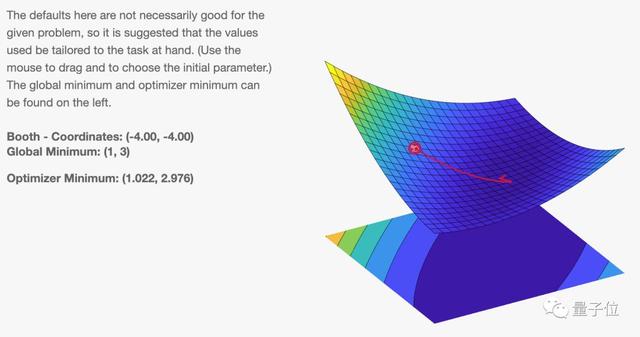
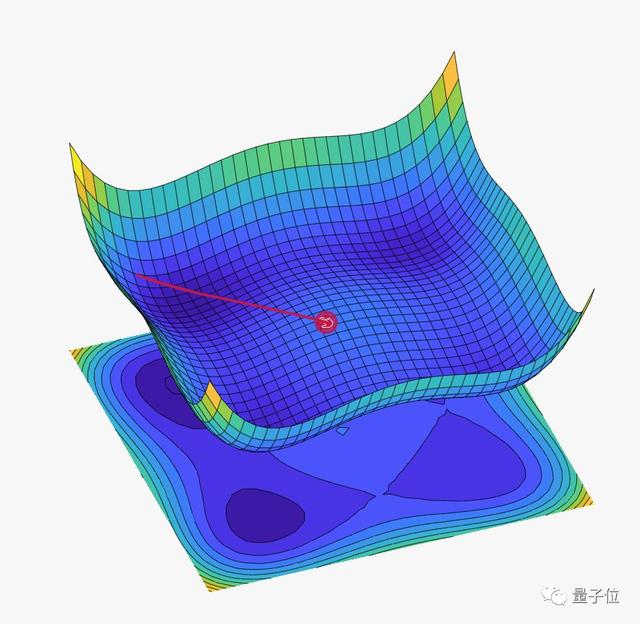
如果觉得上面的损失函数图不够清晰直观,还有高清3D大图:
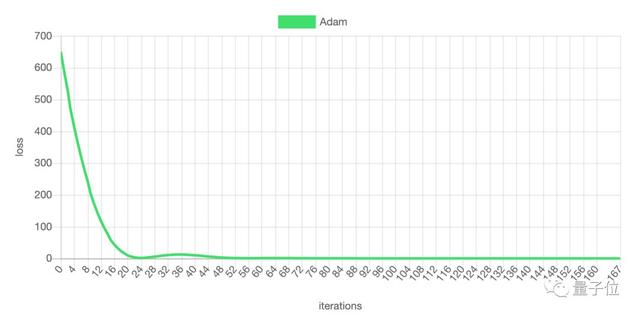
随着迭代步数的增加,损失函数的数值不断减小:
Adam算法可以调节的超参数有:步长、迭代次数、允许误差、β1、β2、模糊因子ϵ、Batch Size。
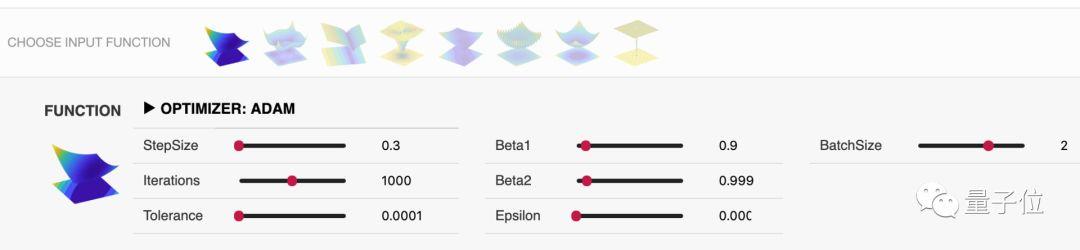
拖动滑动条调节超参数,“红线”的形状和终点也会随之变化。我们不妨调节一下步长,看看这个参数会对结果造成什么样的影响。
增加步长会让学习曲线震荡幅度变大,步长太小会让损失函数收敛过慢:
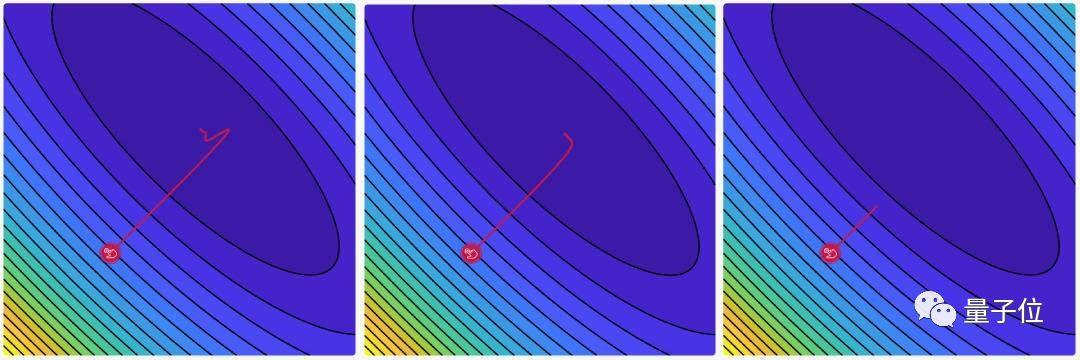
△ 步长分别是0.3、0.03和0.003的三种情况
以上只是最简单的情况,Demo界面还提供其他奇形怪状的损失函数:
以及近乎所有常见的优化算法:
在不同形状的损失函数里,这些优化算法各有优缺点。
如果损失函数的“等高线”是椭圆,Adam收敛速度很快,仅迭代100步左右就已经收敛,而AdaGrad迭代了近300步才收敛。
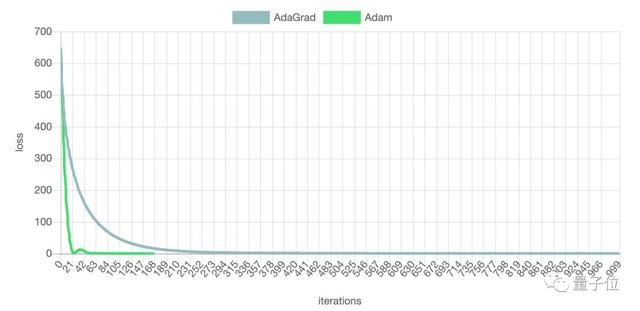
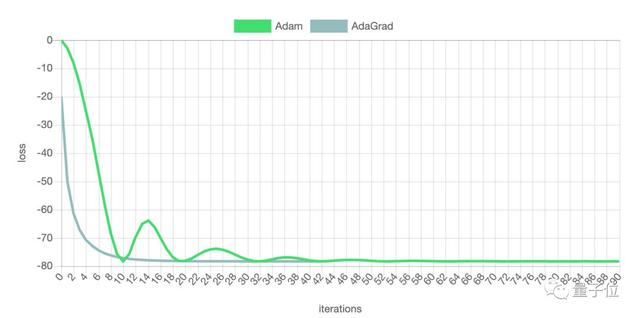
但Adam并非就有绝对优势。在有多个鞍点和局部最小值的图形中,Adam虽然在开始阶段下降速度很快,但是在***阶段震荡较严重,收敛速度反而不及AdaGrad。
上面的“玩法”只是Demo很小的一部分,想尝试更多请参见文末的链接地址。
C++程序员福音
千万不要以为ensmallen只是一个好玩的Demo,实际上它还是一个高效的C++优化库。对于用C++来给AI编程的程序员来说,它能对任意函数进行数学优化,解决了C++机器学习工具匮乏的痛点。
ensmallen除了打包基本优化算法之外,用户还可以使用简单的API轻松添加新的优化器。实现新的优化器只需要有一种方法和一个新的目标函数,通常用一到两个C++函数就能搞定。
安装ensmallen需要满足以下要求:
- 支持C++ 11的编译器
- C++线性代数与科学计算库Armadillo
- 数学函数库OpenBLAS或Intel MKL或LAPACK
ensmallen中的所有内容都在ens命名空间中,因此在代码中放置一个using指令通常很有用 :
- using namespace ens;
以使用Adam为例,其代码如下:
- RosenbrockFunction f;
- arma::mat coordinates = f.GetInitialPoint();
- Adam optimizer(0.001, 32, 0.9, 0.999, 1e-8, 100000, 1e-5, true);
- optimizer.Optimize(f, coordinates);
其中,Adam优化器中参数的顺序依次是:步长、Batch Size、β1、β2、ϵ、***迭代次数、允许误差、是否以随机方式访问每个函数。
至于其他优化算法,可以去网站查看详细的说明文档。
***附上所有资源:
ensmallen压缩包下载地址:
https://ensmallen.org/files/ensmallen-1.14.2.tar.gz
Demo地址:
https://vis.ensmallen.org/















