【51CTO.com原创稿件】众所周知,美团为用户提供了全方位的生活服务,包括外卖、出行、甚至是零售和生鲜等方面。
面对纷繁复杂的服务与选项,用户怎样才能快速地找到自己想要的结果呢?这就需要美团平台的搜索服务来帮忙。

2018 年 11 月 30 日-12 月 1 日,由 51CTO 主办的 WOT 全球人工智能技术峰会在北京粤财 JW 万豪酒店隆重举行。
本次峰会以人工智能为主题,来自美团的高级算法技术专家蒋前程在推荐搜索专场,从美团搜索的主要特点,以及他们是如何使用自己的算法模型去应对挑战等方面,向大家介绍《美团 O2O 服务搜索的深度学习实践》。
美团搜索业务现状

目前,美团搜索覆盖了平台 40% 的交易,具有所谓***的 POI(Point of Interest,兴趣点)和亿级别的 SPU(Standard Product Unit,标准化产品单元),而且用户每天的搜索频次(即:日 PV),也能达到亿级。

那么,美团搜索具体涉及到哪些方面呢?如上图所示,除了左图上方的首页搜索栏,其下方的各个业务频道里的搜索服务,也是由我们团队来负责的。
因此,我们搜索的服务目标可分为许多种,包括:主体 POI,每个 POI 下不同业务所提供的不同服务,如:买单服务、外卖服务、传统团购业务、预付业务、以及酒店预付业务等。

作为美团搜索的平台,我们的使命是把用户流量进行高效的分发,并且在分发内容的基础上尽量提升他们的搜索体验。
在保持用户黏性的同时,我们不但要提高用户的交易效率,而且要为他们的决策提供更多的信息帮助。
另一方面,对于商家而言,我们需要把更优质的用户流量导向他们,从而带来更高的转化效率。这便是我们作为美团入口的各项使命。
美团搜索的特点和挑战
下面我们来讨论一下 O2O 的搜索与其他网页及电商的搜索,有什么相同与相异之处,以及我们面临着哪些挑战。
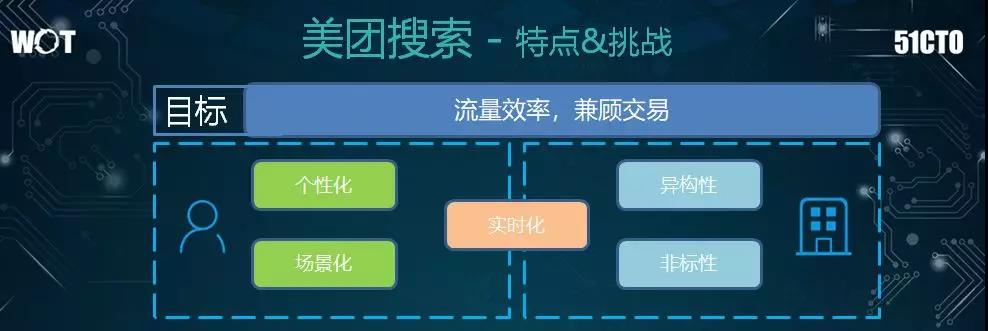
首先,就目标而言,我们的业务种类繁多,而且每种业务在不同的发展阶段有着不同的优化目标:有的需要优化点击率、有的需要优化转化率、有的需要优化 GMV(Gross Merchandise Volume,成交总额)。
因此对于我们平台而言,利用现有的大流量、服务好业务方、提高效率、加固平台的交易,便是我们的整体大目标。
其次,对于用户而言,他们需要根据不同的用户属性搜索到个性化的结果。另外,我们也需要根据搜索时的时间和空间等场景的不同,提供差别化的结果。
再次,对于商家而言:
- 异构性非常大。每个业务及其字段的关注点都有所不同。由于他们所提供的服务存在着差异性,因此其数据和检索层面,也与传统搜索存在着巨大的差异。
- 非标属性。从平台上的餐饮店铺可以看到,商家的菜品本身就是一些非标准化的产品。这与电视和空调之类的标准品,有着本质上的区别。
可见,用户与商家之间是通过实时性相关联的。也就是说用户的需求会随着所处位置,以及早中晚餐的时间会有所不同。
而商家的运能也会随着一天中的不同时段,以及是否下雨等天气因素有所变化。因此,这些都被视为美团搜索的特点和挑战。

总结而言,我们搜索服务的愿景便是:让更多人更便捷地找到更多他们想要的生活服务。
其中“找到更多想要的”,可以通过智能匹配技术来实现;而“更便捷地找到”,则需要有个性化的排序。面对这两条关键路径,我们在深度学习方面进行了如下探索。
美团搜索深度学习探索实践
智能匹配

一般说来,用户的意图表达分为显式和隐式两种输入类型:
- 显式就是他直接通过筛选条件所传递的搜索要求。
- 隐式则包括用户的搜索时间、地理位置和个人偏好。
因此,智能匹配就要求我们通过搜索结果,展现出用户需要的集合。

那么如何才能做好智能匹配呢?我们总结起来会涉及到如下两个方面:
- 用户意图的匹配。
- 多维度的匹配。

就用户意图而言,虽然搜索的是同一条词汇,但是不同种类用户的期望结果会有所不同。
例如:“北京南站”一词:
- 对于北京本地常住的用户来说,他们搜索的目的居多是出自餐饮外卖需求。
- 对于北京本地但少去的用户来说,他们搜索的目的居多是出自公交换乘需求。
- 对于外地游客来说,他们搜索的目的居多是出自火车与住宿需求。
因此,这就要求我们针对不同“背景”的用户展现不一样的内容。
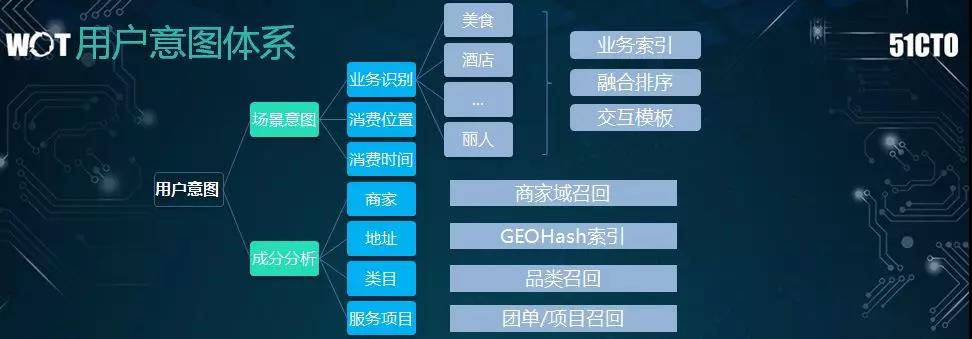
可见,用户的意图可以大致分为两个维度:
- 场景意图,即基于用户的隐式条件,我们要探究其需求是以美食为主、酒店为主、还是以旅游为主。这是业务级别上的需求。
- 成分分析,即针对用户的显式输入,我们要分析其中间的有效成分,并籍此制定出有针对性的标准。
业务识别

下面我来看看业务识别的基本流程。首先,我们要有一个行业知识库,或称为词表。
接着,我们挖掘出一些通用的词汇,以保证每个词都能对应某个需求,以及 Top 的相关问题。
在系统上线之后,我们通过迭代来匹配用户的反馈,包括他们的点击、下单、品类等业务分布。然后,我们得出此类需求分布的概率,并执行各种召回。
当然,这种简单统计行为的泛化能力是存在一些问题的。如果用户的行为特征反馈并不充分的话,他们的需求也就不太明确。
此时我们自然而然地想到了使用各种机器学习模型,对文本和用户行进行向量化,通过诸如 FastText 或 CNN 之类的分类模型,对用户的各种特征予以分类,从而得到用户的意图,并解决泛化的问题。
不过我们也曾经发现:通过机器学习所得到的分布,虽然对整体而言是合理的,但是对于某些用户却并不合理。
因此,我们最近采用了一些强化学习的方法:在细微之处,我们探索性地为用户提供业务需求的入口,从而收集到用户后续的反馈。
通过此类迭代,我们可以识别出用户在某方面的业务需求是否强烈。

至此,我们是否可以认为整体的业务已经识别清楚了呢?其实,我们不难发现:在用户仅输入单个词语进行搜索的情况下,平台基于大量用户数据所统计出来的需求分布,并不一定能够准确地反映出用户的意图。
另外,用户的历史意图是否会影响他的实时意图呢?面对此类时序化的问题,我们需要基于此前他在我们系统中发生过的搜索行为,采用大数据统计来提取相关特征,利用 RNN 模型去预测他的下一个行为。
当然,我们也会参照上述一些非业务方面的因素。
成分分析
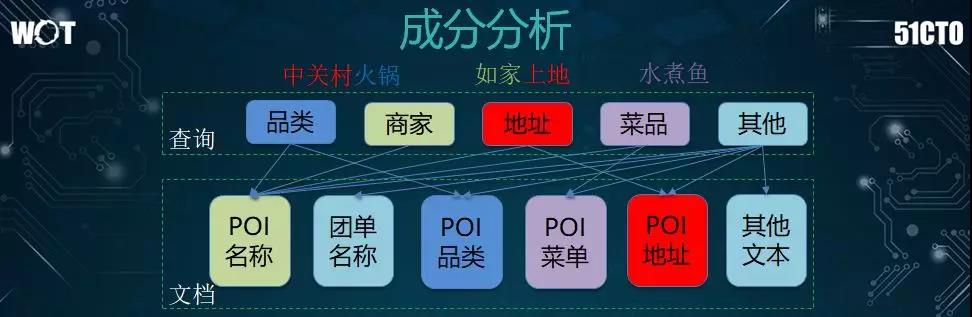
第二个方面是成分分析。考虑到用户可能会搜索各种短语,如:“中关村火锅”,其中,“中关村”是地址,“火锅”是品类,那么我们需要做好针对性的检索。
例如:我们将地址信息转化成地图上的坐标画圈,将品类信息转呈到已有成品类的检索中,进而实现成分分析和智能匹配的***结合。

由于成分识别实际上是一个序列标注的问题,因此我们起初采用的是传统的 CRF 模型。
虽然该模型的精度与召回尚可,但是它对于语义的理解,以及相关性的考虑是不够的,而且它需要人工进行特征提取与数据标注。因此,我们想到了使用基于 LS 的深度学习与 CRF 结合的方法。
初期,由于数据量太小,算法不能很好地学习到各种标签的正确性,因此效果不如 CRF。
于是,我们采用了如下的方法来扩充数据量:
- 我们将已训练的 CRF 模型扩展出更多的语料,使之将预测出来的结果作为标志数据。
- 对于已总结的数据库,我们根据用户反馈的规则,挖掘出更多的数据。
通过各种扩充,待样本增长了***的规模时,我们再运用深度学习模型进行实体识别。
在实体识别的过程中,我们所用到的输入特征包括:值向量特征,以及以前 CRF 所用到的人工特征,通过 BiLSTM 再进行 CIF,***达到了实体识别。而由此所产生的效果相对于 CRF,已经有了大幅的提升。
当然根据业务属性,由于商家的名称以及微信地址都是五花八门的,因此我们无法做到及时的全面覆盖,召回也就不那么的理想。
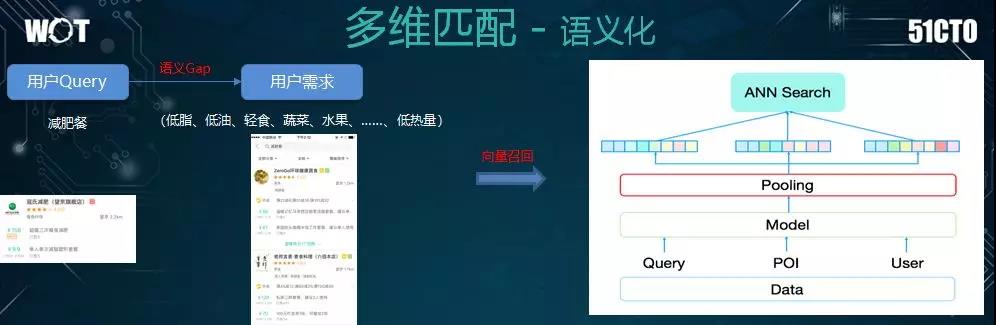
前面提到的是用户意图在智能匹配上的作用。下面我们来看为何要进行多维匹配。
例如:某个用户输入了“减肥餐”,那么我们仅仅使用文本匹配予以返回显然是不够的。
他的潜在需求,可能还包括:低油、低脂、轻食、蔬菜、水果等一系列方面。因此,这就产生了需求之间的语义 Gap。
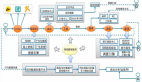
为了弥补该 Gap,我们需要建立向量化的召回框架结构,由上方的示意图可见,我们将文本数据和用户行为序列数据,导入语义模型,处理完毕后得到了 Query、POI、User 三者的向量,再根据这些向量执行召回。
如今,该框架已经能够被在线使用到了。
语义模型
下面我们来介绍一下美团在语义模型方面的具体尝试。

首先是 DSSM 模型。我们在其原生模型的基础上进行了一些修改。在输入方面,我们采用的是文档(Doc)和查询(Query)的双塔结构。此处,我们已经做好了文本的过滤(包括低频次的过滤)。
通常情况下,系统会经过两个隐藏层。而在此处,我们改进为:让第二层将***层向量选出来的隐性层转到第三层,以便数据能够更好地向下传递。
而在输出层,我们会更细腻地考虑两者之间的权重。我们会做一个相似度的矩阵,同时将这两个向量传递到***的输出层,以线性加权的方式得到最终的分数,这便是我们在 DSSM 语义模型上的探索。

前面我们讨论了监督的模型,其实我们也尝试了一些非监督的模型。非监督模型主要是基于用户的行为序列。
例如:用户会在某个查询会话中会点击多处(POI1、POI2),那么我们就将此序列当成一个文档。
相比前面提及的主要体现在文本上的模型,此处则更偏向于推荐的思想。如果用户既点了 A,又点了 B,那么两者之间就存在相似性,因此我们采用了单独的模型来训练此类序列。
而且,我们在输入层不只是把 POI 进行了向量化,还将与 POI 相关的品类信息、GU 哈希信息等都拼接成额外的向量。这便是我们所做的简单的改动。
上图右侧是一个向量的展现,可见系统能够把一些相关的信息学习出来,以便我们进行各种相关性的召回。
针对上述智能匹配技术,我们总结起来有两个方面:
怎么做好用户的意图识别。
怎么实现多维度匹配,即:在传统文本匹配的基础上,加入了向量化召回的思路。
个性化排序
在完成了用户匹配之后,我们帮用户搜到大量的匹配结果。那么,我们势必需要通过个性化排序,来优先显示用户最需要的结果信息。

如上图所示,排序的整体流程为:
- 我们使用召回层进行简单的粗排,它适用于一些简单的特征,即通过线性模型对结果进行初步过滤。
- 把少量的结果送到模型层,执行点击率和转化率的预估。
- 在业务层会有一些可解释性、业务规则的排序。

其中,模型层的演进过程是:线性模型→决策树模型(如 GBDT)→PairWise 模型→实时模型→深度学习,以满足个性化的特征。
下面,我们来重点讨论实时模型和深度学习的实现方式。
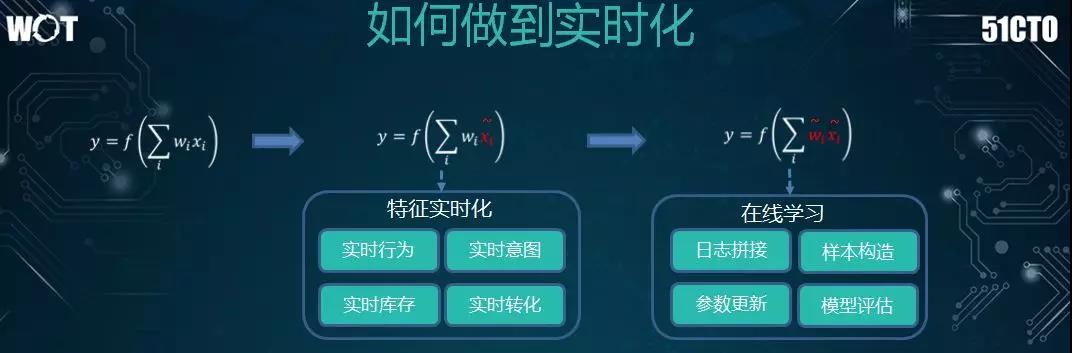
为了更好地满足用户的需求。我们有两种实时化的方向:
- 许多公司会将包括实时行为、实时库存、实时转化等在内的特征放入模型,以进行实时更新。
- 通过在线学习,拼接各种实时流,实时更新参数,根据模型的评估,判断是否要替换成新训练的模型。
实时特征

同时,在提取实时特征的过程中,我们需要将用户实时的数据,如:点击流、下单流等请求数据缓存到 Storm 里。
接着,基于这些数据,我们需要提取到用户的实时行为特征,包括:品类偏好、价格偏好、距离偏好等。
另外,我们会对序列区分不同的时段,并逐一“兑换”特征,当然,我们也会考虑该用户会话(Session)内部的 01 特征。结合业务特点的挖掘,我们最终把实时特征提取了出来。
深度模型

对于美团而言,深度模型的需求源自如下三个方面:
- 场景非常复杂,每个业务的需求都存在着巨大差异。
- 前面提到的树模型虽然有较好的泛化能力,但是缺少针对用户行为的记忆能力。
- 需要对一些稀疏特征,以及特征组合进行处理。
因此,基于业务和工程师的实际需求,我们有必要采用深度学习模型。

上图是我们的深度学习框架。其特点在于如下三个方面:
- 能够更好地在线支持超大规模的数据和模型,如:几十个 G 的模型。
- 能够方便地支持多种模型的定义。
- 能够很好地支持流式模式的训练与上线。
简单来看,该模型也分为三个部分:
- 离线训练,即Base模型,是从日志数据表里提取特征,通过训练,将参数存到离线集群之中。
- 流式训练,将实时收集到的数据作为日志予以拼接,通过特征的提取,***执行训练。
- 在线预测,通过实时优先级对模型进行评估。如果通过,则更新到 PS 在线集群里进行预测。

有了上述框架的感念,我们再来看看在该深度模型上的探索路径。起初,我们直接将 Dense 特征拿过来,扔到简单的 MLP 里执行快速迭代。
凭借着更强的特征拟合能力,我们能够实时地迭代出参数的模型,进而实现了在线式的实时更新。因此,相比之前的树模型,深度学习模型的效果有了明显的提升。

而针对稀疏特征,我们采用了如下两种方法:
- 直接用模型去学习和训练 Embedding 特征,进而输入到模型之中。
- 通过 Wide 记录模型来实现深度学习。
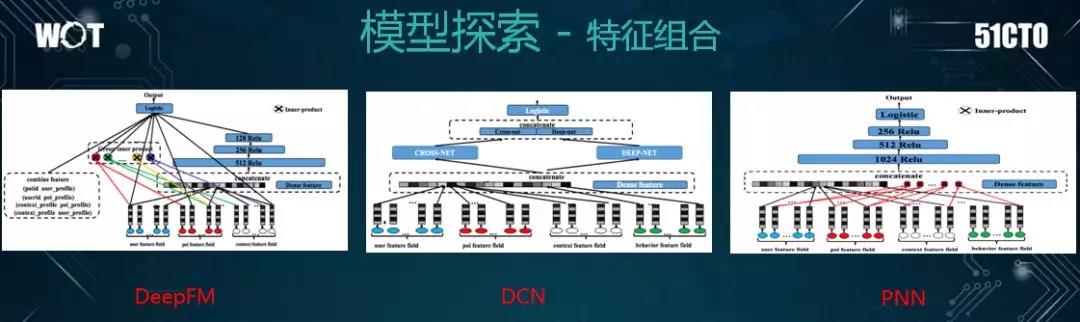
如上图所示,在特征组合方面,我们尝试了一些知名的模型。其实它们之间并无明显的优劣势,就看哪个更适合业务项目罢了。
例如:PNN 是将特征作为一个组合放在了输入层;DeepFM 则多了一个 FM 值;而 DCN 是做到了特征高阶的模型。
因此,我们在不同的业务场景中,都尝试了上述这些模型。一旦发现效果较好,我们就会将其替换成当前业务的主模型。

总的说来,我们现在的主体模型是:流式的深度学习模型。从上图的各项指标可以看出,其整体效果都有了正向的提升。
未来展望

展望未来,我们会在如下两大方面继续个性化排序的探索:
- 智能匹配。在深度上,我们会深耕成分分析、用户意图、以及业务预测等方面。
在广度上,我们会针对文本匹配效果不佳的场景,补充一些向量召回,进而实现根据用户的不同属性,达到多维度个性化召回的效果。
- 排序模型。类似于阿里的 DIEN 模型,我们会对用户的兴趣进行单独建模,进而与我们的排序模型相组合。
考虑到各种品类的相关性、文本的相关性、以及实际业务场景的不确定性,我们将在深度学习中尝试多目标的联合优化。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】