一. 缓存原理
高并发情境下首先考虑到的第一层优化方案就是增加缓存,尤其是通过Redis将原本在数据库中的数据复制一份放到内存中,可以减少对数据库的读操作,数据库的压力降低,同时也会加快系统的响应速度,但是同样的也会带来其他的问题,比如需要考虑数据的一致性、还需要预防可能的缓存击穿、穿透和雪崩问题等等。
1. 实现步骤
先查询缓存中有没有要的数据,如果有,就直接返回缓存中的数据。如果缓存中没有要的数据,才去查询数据库,将得到数据更新到缓存再返回,如果数据库中也没有就可以返回空。
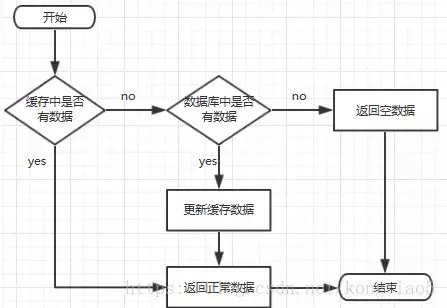
考虑数据一致性,缓存处的代码逻辑都较为标准化,首先取Redis,击中则返回,未击中则通过数据库来进行查询和同步。
- public Result query(String id) {
- Result result = null;
- //1.从Redis缓存中取数据
- result = (Result)redisTemplate.opsForValue().get(id);
- if (null != result){
- System.out.println("缓存中得到数据");
- return result;
- }
- //2.通过DB查询,有则同步更新redis,否则返回空
- System.out.println("数据库中得到数据");
- result = Dao.query(id);
- if (null != result){
- redisTemplate.opsForValue().set(id,result);
- redisTemplate.expire(id,20000, TimeUnit.MILLISECONDS);
- }
- return result;
- }
其他的新增、删除和更新操作,可以直接采用先清空该Key下的缓存值再进行DB操作,这样逻辑清晰简单,维护的复杂度会降低,而付出代价就是多查询一次。
- public void update(Entity entity) {
- redisTemplate.delete(entity.getId());
- Dao.update(entity);
- return entity;
- }
- public Entity add(Entity entity) {
- redisTemplate.delete(entity.getId());
- Dao.insert(entity);
- return entity;
- }
2. 缓存更新策略
适用于做缓存的场景一般都是:访问频繁、读场景较多而写场景少、对数据一致性要求不高。如果上面三个条件都不符合,那维护一套缓存数据的意义并不大了,实际应用中通常都需要针对业务场景来选择合适的缓存方案,下面给出了四种缓存策略,由上到下就是按照一致性由强到弱的顺序。
更新策略特点适用场景
实时更新同步更新保证强一致性,与业务强侵入强耦合金融转账业务等
弱实时异步更新(MQ/发布订阅/观察者模式),业务解耦,弱一致性存在延迟不适合写频繁场景
失效机制设置缓存失效,有一定延迟,可能存在雪崩适用读多写少,能接受一定的延时
任务调度通过定时任务进行全量更新统计类业务,访问频繁且定期更新
二. 缓存雪崩和击穿
1. 缓存雪崩概念
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
解决方案
将缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
用加锁或者队列的方式保证缓存的单线程(进程)写,从而避免失效时大量的并发请求落到底层存储系统上。
第一种方案比较容易实现,第二种的思路主要是从加阻塞式的排它锁来实现,在缓存查询不到的情况下,每此只允许一个线程去查询DB,这样可避免同一个ID的大量并发请求都落到数据库中。
- public Result query(String id) {
- // 1.从缓存中取数据
- Result result = null;
- result = (Result)redisTemplate.opsForValue().get(id);
- if (result ! = null) {
- logger.info("缓存中得到数据");
- return result;
- }
- //2.加锁排队,阻塞式锁
- doLock(id);//多少个id就可能有多少把锁
- try{
- //一次只有一个线程
- //双重校验,第一次获取到后面的都可以从缓存中直接击中
- result = (Result)redisTemplate.opsForValue().get(id);
- if (result != null) {
- logger.info("缓存中得到数据");
- return result;//第二个线程,这里返回
- }
- result = dao.query(id);
- // 3.从数据库查询的结果不为空,则把数据放入缓存中,方便下次查询
- if (null != result) {
- redisTemplate.opsForValue().set(id,result);
- redisTemplate.expire(id,20000, TimeUnit.MILLISECONDS);
- }
- return provinces;
- } catch(Exception e) {
- return null;
- } finally {
- //4.解锁
- releaseLock(provinceid);
- }
- }
- private void releaseLock(String userCode) {
- ReentrantLock oldLock = (ReentrantLock) locks.get(userCode);
- if(oldLock !=null && oldLock.isHeldByCurrentThread()){
- oldLock.unlock();
- }
- }
- private void doLock(String lockcode) {
- //id有不同的值
- //id相同的,加一个锁,不是同一个key,不能用同一个锁
- ReentrantLock newLock = new ReentrantLock();//创建一个锁
- //若已存在,则newLock直接丢弃
- Lock oldLock = locks.putIfAbsent(lockcode, newLock);
- if(oldLock == null){
- newLock.lock();
- }else{
- oldLock.lock();
- }
- }
- ??
注意:加锁排队的解决方式在处理分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
2. 缓存击穿概念
一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。
解决方案
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。
三. 缓存穿透
1. 缓存穿透概念
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,如发起为id为“-1”的数据或id为特别大不存在的数据。这时的用户很可能遭遇安全威胁,导致数据库压力过大。
解决方案:布隆过滤器
布隆过滤器的使用方法,类似java的SET集合,用来判断某个元素(key)是否在某个集合中。和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
使用步骤:
将List数据装载入布隆过滤器中
- private BloomFilter<String> bf =null;
- //PostConstruct注解对象创建后,自动调用本方法
- @PostConstruct
- public void init(){
- //在bean初始化完成后,实例化bloomFilter,并加载数据
- List<Entity> entities= initList();
- //初始化布隆过滤器
- bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), entities.size());
- for (Entity entity : entities) {
- bf.put(entity.getId());
- }
- }
- ??
访问经过布隆过滤器,存在才可以往db中查询
- public Provinces query(String id) {
- //先判断布隆过滤器中是否存在该值,值存在才允许访问缓存和数据库
- if(!bf.mightContain(id)) {
- Log.info("非法访问"+System.currentTimeMillis());
- return null;
- }
- Log.info("数据库中得到数据"+System.currentTimeMillis());
- Entity entity= super.query(id);
- return entity;
- }
这样当外界有恶意威胁时,不存在的数据请求就可以直接拦截在过滤器层,而不会影响到底层数据库系统。