Pravega为什么很重要?
你看看人家阿强,
差点就把后半辈子规划想好了
▼
阿强:鉴于对未来一片迷茫,我已经想好了后半辈子的人生规划...
李小男:哇,受什么刺激了?
阿强:公司在规划5G战略,可我一想到Lambda应对流数据的能力就开始发愁。佛了,X烟、喝酒、植发,这大概就是我今后的人生三件大事......
李小男:听过那个“蓝鸟”没有?
阿强:姐,就别拿我开玩笑了...还蓝鸟?下辈子的房贷都在愁呢
李小男:Pravega去了解一下,你会回来感谢我的~
30分钟后...
阿强:姐,我复活了,未来,充满信心!
李小男:先别急着激动,还没谢谢我呐
然鹅
仅仅拯救这个阿强还不够
因为,还有无数个阿强在等待
看完这篇文章
救救你身边的阿强!
▼
上一期内容我们讲到:5G时代到来,无处不在的物联网、自动驾驶汽车等在边缘产生的数据源源不断,就像开着的水管,数据源一直流出,由此诞生了新的数据类型即“流数据”。然而,无论Hadoop还是Lambda,都无法胜任新数据环境下的要求,因为计算是原生的流计算,而存储却不是原生的流存储。(上一期文章)
针对流数据的应用场景,流数据存储需要满足低延时、仅处理一次、顺序保证、检查点这四点要求。
因此戴尔科技集团IoT部门的团队重新思考了流式数据处理和存储规则,为流数据场景设计了新的存储类型,即原生的流存储,并由此诞生了“Pravega”。
于是今天我们把目光聚焦Pravega,来一次Deep Dive,潜入深海,重点介绍Pravega的特点与优势,看它是如何解决新数据环境下的流数据问题。
▼▼▼
作者简介
滕昱
滕昱:就职于Dell EMC中国研发集团,非结构化数据存储部门团队并担任软件开发总监。2007年加入Dell EMC以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代Dell EMC对象存储产品的研发工作并取得商业上成功。从2017年开始,兼任Streaming存储和实时计算系统的设计开发与领导工作。
周煜敏
周煜敏:复旦大学计算机专业研究生,从本科起就参与Dell EMC分布式对象存储的实习工作。现参与Flink相关领域研发工作。
吴长平
吴长平:现就职于Dell EMC,10年+存储、分布式、云计算开发以及架构设计经验,现从事流存储和实时计算系统的设计与开发工作。
Pravega,取梵语中“Good Speed”之意,其设计宗旨是成为流的实时存储解决方案。它属于戴尔科技集团IoT战略下的一个子项目。该项目是从0开始构建,用于存储和分析来自各种物联网终端的大量数据,旨在实现实时决策。其结合了戴尔易安信PowerEdge服务器,并无缝集成到非结构化数据产品组合Isilon和Elastic Cloud Storage(ECS)中,同时拥抱Flink生态,以此为用户提供IoT所需的关键平台。
针对上面说到的四点要求,从访问模式角度来说,Pravega统一了传统批数据和流数据,因此不仅可以实时到达数据的低延时 (low latency) 读和写,还可以满足对于历史数据的高吞吐 (high throughput) 的读。

技术在某种程度上一定是来自此前已有技术的新的组合。
——《技术的本质》,布莱恩·阿瑟
当然,Pravega 也不是凭空发明出来的,它也是以前的成熟技术与新技术的组合。Pravega团队拥有基于日志存储的设计经验,也拥有Apache ZooKeeper/BookKeeper的项目历史,加之大量实时系统同样也采用日志存储的方式来完成实时应用的消息队列,想要满足尾读、尾读和追赶读这三种据访问模式,自然想到了使用仅附加 (Append Only) 的日志作为存储原语。
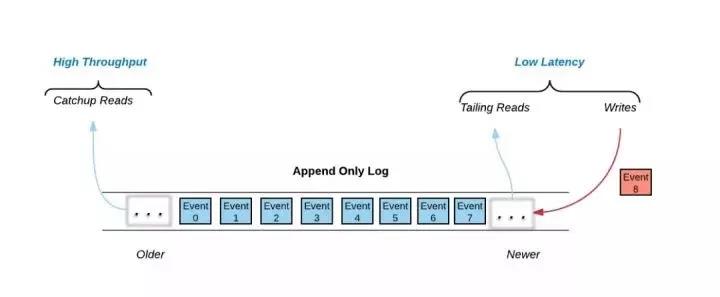
图 1. 日志结构的三种数据访问机制
如图1所示:在Pravega里,日志是作为共享存储原语而存在的,数据以事件 (event) 的形式以仅附加的方式写入日志当中。
所有写入操作以及大部分读取操作都发生在日志的尾部 (tail read/write)。写操作将事件附加到日志中,而大量读客户端希望以到达日志的速度读取数据。这两种数据访问机制主要是需要低延迟。
对于历史数据的处理,读客户端不从日志的尾部读取,而是从日志中的任意位置开始读。这些读取称为追赶读 (catch-up read)。我们可以采用和尾部数据一样的高性能存储(例如SSD)来存储历史数据,但这会非常昂贵并迫使用户通过删除历史数据来节省成本。这就需要 Pravega 架构提供一种机制,允许客户在日志的历史部分使用经济高效,高度可扩展的高吞吐量存储,这样他们就能够保留所有的历史数据,来完成对一个完整数据集的读取。
Pravega 支持仅一次处理 (exactly-once),可在Kappa架构上实现链接应用需求,以便将计算拆分为多个独立的应用程序,这就是流式系统的微服务架构。我们所设想的架构是由事件驱动、连续和有状态的数据处理的流式存储 - 计算的模式(如图 2)。

图 2.流处理的简单生命周期
通过将Pravega流存储与Apache Flink有状态流处理器相结合,上图中的所有写、处理、读和存储都是独立的、弹性的,并可以根据到达数据量进行实时动态扩展。这使我们所有人都能构建以前无法构建的流式应用,并将其从测试原型无缝扩展到生产环境。拥有了Pravega,Kappa架构得以凑齐了***的拼图,形成了统一存储、统一计算的闭环。
Pravega 逻辑架构
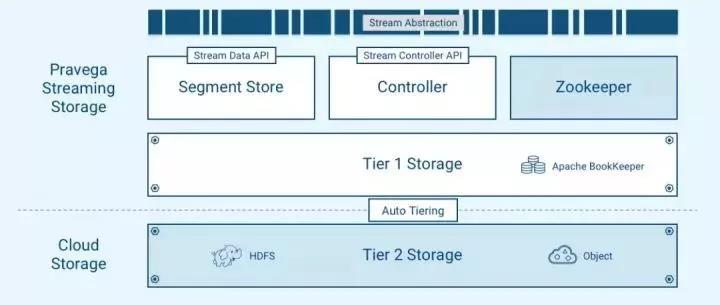
图 3. Pravega 架构
为了实现上述的三种访问模式的性能需求,Pravega采用了如图3所示的分层存储架构。事件可以存储在低延迟/高 IOPS的存储(***层存储)和更高吞吐量的存储(第二层存储)中。通过这种方式,冷热数据分离有效降低了数据存储成本。上层使用Apache ZooKeeper作为分布式协调器,并提供统一的Stream抽象。
***层存储
***层存储用于快速持久地将数据写入Stream,并确保从Stream的尾读尽可能快。***层存储基于开源Apache BookKeeper项目。BookKeeper是一种底层的日志服务,具有高扩展、强容错、低延迟等特性。许多Apache开源项目,例如Apache Pulsar,Apache DistributedLog都是基于这一项目实现。BookKeeper对于复制、持久性、一致性、可用性、低延时的承诺也正是Pravega所需要的***层存储的需求。为达到高性能的读写延迟需求,我们建议***层存储通常在更快的 SSD 或甚至非易失性存储 (non-volatile RAM) 上实现。
第二层存储
第二层存储考虑到经济效益,选用高度可扩展,高吞吐量的云存储,目前Pravega支持HDFS,NFS和S3协议的二级存储,用户可以选用支持这些协议的大规模存储进行扩展。Pravega提供了两种数据降层 (retention) 的模式,一种基于数据在Stream中保留的时间,另一种基于数据在Stream中存储的容量大小。Pravega会异步将事件从***层迁移到第二层,而读写客户端将不会感知到数据存储层级的变化,依然使用同样的Stream抽象操作数据的读写。
正是基于这样的分层模型,大数据处理的降低开发成本、减少存储成本与减少运维成本这三大问题被Pravega一次性解决了。
❶ 对开发者而言,只需要关心Stream抽象的读写客户端的操作。实时处理和批处理不再区分对数据访问方式,由此提升了效率,带来开发成本的降低。
❷ 数据仅在***层存储有三份拷贝,在第二层存储则可以通过商业分布式 / 云存储自身拥有的高可用、分布式数据恢复机制(如 Erasure Coding)进一步降低存储系数,达到比公有云存储更便宜的总体拥有成本 (TCO)。
❸ 所有的存储组件归结为统一的Pravega,组件仅包括Apache ZooKeeper,Apache BookKeeper以及可托管的第二层存储,运维复杂程度大大降低。Pravega还提供了额外的“零运维”自动弹性伸缩特性,进一步减轻了数据高峰期的运维压力。
Pravega 产Pravega 产品定位和与 kafka 的对比比
让我们以当今业界应用最广的分布式消息系统Apache Kafka作为对比,看看Pravega如何实现了今天存储无法实现的方式。
Pravega是从 存储的视角 来看待流数据,而Kafka本身的定位是消息系统而不是存储系统,它是从 消息的视角 来看待流数据。消息系统与存储系统的定位是不同的,简单来说,消息系统是消息的传输系统,关注的是数据传输与生产消费的过程。Pravega的定位是企业级的分布式流存储产品,除了满足流的属性之外,还需要满足数据存储的持久化、安全、可靠性、一致性、隔离等属性,关注数据的生产、传输、存放、访问等整个数据的生命周期。作为企业级的产品,一些额外的特性也有支持,例如:数据安全、多租户、自动扩缩容、状态同步器、事务支持等,部分特性将在后续文章详述。
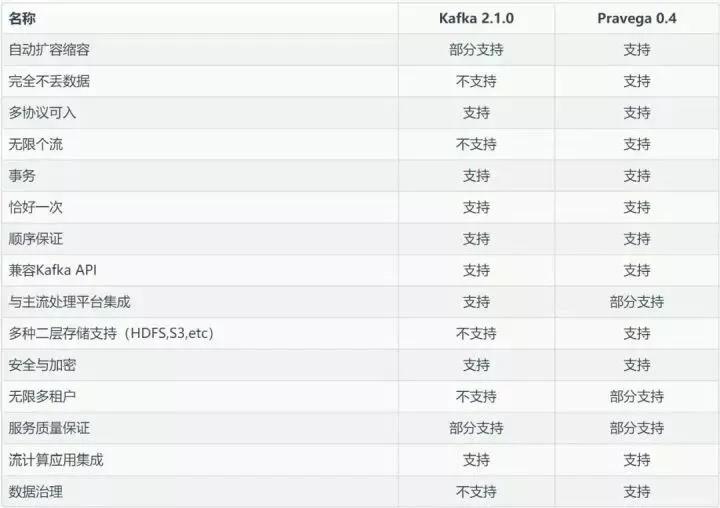
这里我们把Pravega与Kafka做了对比,大体在功能上的差异如下表所示。功能上的差异也只是说明各个产品针对的业务场景不同,看待数据的视角不同,并不是说明这个产品不好,另外每个产品自身也在演进,因此本对比仅供参考。
总结:
本期内容我们主要介绍了重点介绍了Pravega的关键架构以及关键特性,以及它能给开发人员和公司带来的优势,并与Kafka做了简要对比。下一期的“IoT前沿”中,我们将重点介绍Pravega的伸缩性,并通过相关案例来辅助说明,欢迎大家持续关注,如何你有疑问,可以在下方进行留言或在知乎号上找到我们(见下方二维码)我们将为你答疑解惑。下一期见~

扫码关注知乎号
你和戴尔易安信专家只有一条网线的距离~
往期回顾
5G时代下,大数据存储面临的三大挑战
轻装前行,戴尔易安信亮相GTC大会
PowerEdge MX搭个SAN网络?So easy