【51CTO.com原创稿件】就像哲学有不同的流派一样,推荐系统的算法设计思路也可以分为不同的流派。排序学习恰恰就是其中的一种流派。熟悉 RecSys 等推荐系统国际会议的从业者可能会发现,自 2010 年以后的若干年内,陆续出现了许多基于排序学习的推荐系统算法。从 Bayesian Personalized Ranking (BPR) 到后续的 Collaborative Less is More Filtering (CLiMF) 以及 GapFM 和 XCLiMF 等算法,在推荐系统领域出现了百家争鸣,百花齐放的局面。
排序学习的设计思想与协同过滤和矩阵分解以及随后出现的深度学习的主要不同在于排序学习把推荐系统看成是一个排序的问题。也就是如何给用户推荐商品的问题变成了如何在用户有可能喜欢的物品集合中对物品排序的问题。这个过程中算法不纠结于对于用户喜欢的物品的评分进行准确预测,而是把物品之间的顺序关系作为优化的目标。
排序学习的英文名称是 Learning to Rank ,根据优化目标的不同,共分为三类:基于点的排序学习 ( Point-wise Learning to Rank ) ,基于关系对的排序学习 ( Pair-wise Learning to Rank ),以及基于列表的排序学习( List-wise Learning to Rank )。基于点的排序学习本质上就是传统的分类算法,例如 SVM ,逻辑回归等都属于基于点的排序学习,这类排序学习通常被认为是排序学习的退化形式;基于关系对的排序学习强调的是物品集合中物品两两之间的关系,本章将要展开讨论的 Bayesian Personalized Ranking 算法就属于这一类算法;基于列表的排序学习强调的是物品集合中物品列表的整体排序关系,后续章节中将要展开讨论的 Collaborative Less is More Filtering 算法属于这个范畴,这类算法将物品集合中物品评分的整体排序关系作为最终的优化目标。
Bayesian Personalized Ranking 的整体思路如下:假设我们现在有 N 个视频,每个视频有两种用户行为:被用户点击,没有被用户点击。现在设定用户给物品的评分如下:被用户点击过的视频得分 +1 ,从没有被用户点击过的视频中进行采样得到一部分视频,这部分视频被认为是用户不喜欢的视频,得分 -1 。
Bayesian Personalized Ranking 首先假设用户对物品的评分背后的模型是某个常见模型,比如矩阵分解模型,也就是用户对物品的评分 R = U’ * V ,其中 U 是用户向量,而 V 是物品向量。算法假定所有得分 +1 的物品和所有得分 -1 的物品,如果用评分矩阵 R 重新对物品进行打分,原本得分 +1 的物品的新得分将高于原本得分 -1 的物品的新得分。
算法的本质诉求是在***可能的满足原有的 +1 物品得分高于 -1 物品得分的排序对成立的情况下,倒推出 R 评分分解后的 U 和 V 向量。***通过计算 U和 V 的乘积,得到用户对物品的完整评分矩阵,完成整个算法过程。下面我们详细的展开算法进行讨论:
首先定义有序关系,如果用户喜欢物品 I1 而不喜欢物品 I2 ,则存在有序关系 I1 >u I2 。定义评分矩阵为参数 theta, 建立需要被优化的贝叶斯模型 。用 u 表示有序对 ( I1 , I2 ),建立***似然函数求解公式如下:
。用 u 表示有序对 ( I1 , I2 ),建立***似然函数求解公式如下: ,其中
,其中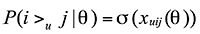 ,而
,而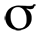 是 sigmoid 函数
是 sigmoid 函数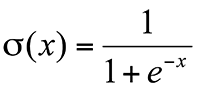 ,
,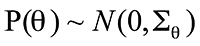 。这里定义的贝叶斯模型是一个一般性的框架,具体的算法模型实现由
。这里定义的贝叶斯模型是一个一般性的框架,具体的算法模型实现由 的计算方式而定。
的计算方式而定。
Bayesian Personalized Ranking 优化的指标是 AUC 函数。AUC 函数在 Bayesian Personalized Ranking 问题中被归约为以下形式:

其中
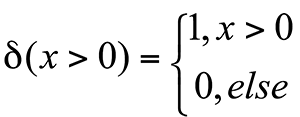
采用随机梯度下降求解参数 得到:
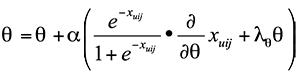 ,
,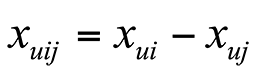
可以看到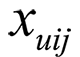 就是用户 u 对物品 i 和物品 j 的评分之差。我们已经得到了随机梯度下降过程中的参数计算方法,在实际应用中只需要将用具体的模型替代即可,比如协同过滤,或者矩阵分解。我们给他们分别用代号 BPR-CF 和 BPR-MF 等表示。
就是用户 u 对物品 i 和物品 j 的评分之差。我们已经得到了随机梯度下降过程中的参数计算方法,在实际应用中只需要将用具体的模型替代即可,比如协同过滤,或者矩阵分解。我们给他们分别用代号 BPR-CF 和 BPR-MF 等表示。
现在假定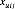 是由矩阵分解模型计算得到的。也就是
是由矩阵分解模型计算得到的。也就是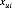 = U’V =
= U’V = ,带入随机梯度下降公式计算可得到:
,带入随机梯度下降公式计算可得到:
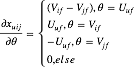
类似的,我们可以得到基于协同过滤的 BPR 的梯度下降公式。
BPR 因为是计算两两有序对之间的关系,所以在实际的计算过程中涉及到的数据量可能非常庞大。另外,在***进行评分预测时需要进行庞大的矩阵运算。通常在实际的计算过程中采取了抽样等方法来降低计算量,而不是采用全量数据进行计算。
BPR 是推荐系统中基于对的排序学习中的比较重要的一类方法,广泛应用在推荐系统的各种实践之中。
汪昊, 区块链公司科学家,美国犹他大学本科/硕士,对外经贸大学在职 MBA,在百度、新浪、网易、豆瓣等公司有超过8年的技术研发经验,曾担任恒昌利通大数据部总监。擅长机器学习、数据挖掘、计算机图形学和科学可视化等技术。在 TVCG 和 ASONAM 等国际会议和期刊发表论文 10 篇。本科毕业论文获国际会议 IEEE SMI 2008 ***论文奖。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】