













今天对一套环境的数据从SQL Server迁移到MySQL,中间涉及诸多的架构改进,我们主要说一下数据迁移的一些基本思路,以下是一个开始,会在后面不断的迭代改进一些方案。
整体来说,迁移的数据量听起来不是很多,大概是300G左右。
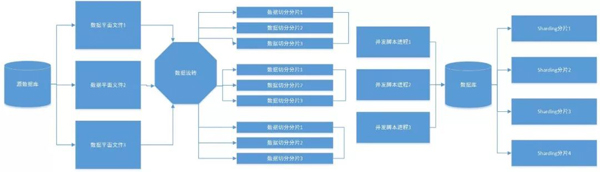
整体的步骤是:
1)数据从SQL Server导出为csv文件
2)数据流转到MySQL中间服务器上
因为文件较大,比如有的文件有几十G,单次导入会直接抛错,所以需要做下切分,比如按照1000万的数据维度切分。
3)数据切分
数据会被切分成相对规整的分片,比如按照1000万的基准,一个4亿数据量的文件会被切分为近40个500M的文件
4)因为切分后的文件太多,所以在导入前需要把这些任务划分为几个组
5)导入的时候,是按照并发进程的方式,因为数据库后端已经做了分片,所以就不需要调用是开启太多的线程了。
6)数据通过中间件导入,数据落盘在多个分片节点上,物理分片是4个,每个物理分片上有4个逻辑分片,即一共有16个逻辑分片。
数据流程图如下:
从目前的测试来看,如果是4个物理分片,通过中间件使用load data的方式,速度基本在80万每秒。和单机的20万相比,效率和性能是很明显的。
从目前的数据迁移来看,还是存在一些使用风险,一来转储数据为csv文件的时间较长,中间还涉及数据流转和数据切分,等到数据真正导入的时候,流量和性能的损耗已经很高了。
目前的测试,有些分片节点的负载高达30以上,算是充分利用了服务器资源。
按照目前的基本数据情况,导入近70亿数据需要2个小时左右,而这个过程还不包括中间环节的衔接和数据流转,实际的时间会在近5个小时,从数据迁移窗口来算,这个时间明显是不符合需求的,如果把时间控制在1个小时,有没有更好的方法?


















