日前,互联网巨头Facebook宣布了收购片上网络(network-on-chip,NoC)IP提供商Sonics,据悉Facebook会将Sonics的NoC技术应用在其AR/VR相关的应用中。除了Sonics之外,去年Intel也收购了另一家NoC IP提供商Netspeed,以至于目前在NoC领域,Arteris成为了唯一的独立IP供应商。为什么近年来巨头动作频频,争相收购NoC IP提供商呢?本文将为您做详细分析。
片上网络的历史沿革
片上网络(NoC)其实已经有悠久的历史,在2006年Arteris就推出了其***款商用NoC IP。为了理解NoC出现的原因,我们首先回顾一下NoC出现前的片上互联方式。
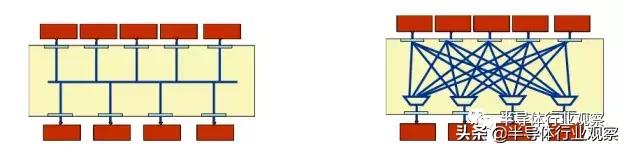
传统片上BUS总线(左)和Crossbar(右)互联方式
在NoC出现之前,传统的片上互联方法包括Bus总线和Crossbar两种。Bus总线的互联方式即所有数据主从模块都连接在同一个互联矩阵上,当有多个模块同时需要使用总线传输数据时,则采用仲裁的方法来确定谁能使用总线,在仲裁中获得总线使用权限的设备则在完成数据读写后释放总线。ARM著名的AXI、AHB、APB等互联协议就是典型的总线型片上互联。
除了总线互联之外,另一种方法是Crossbar互联。总线互联同时只能有一对主从设备使用总线传输数据,因此对于需要较大带宽的架构来说不一定够用。除此之外,在一些系统架构中,一个主设备的数据往往会需要同时广播给多个从设备。在这种情况下,Crossbar就是更好的选择。Crossbar的主要特性是可以同时实现多个主从设备的数据传输,同时能实现一个主设备对多个从设备进行数据广播。然而,Crossbar的主要问题是互联线很复杂,给数字后端设计带来了较大的挑战。
与总线和Crossbar相比,NoC则是一种可扩展性更好的设计。NoC从计算机网络中获取了灵感,在芯片上也实现了一个类似的网络。在NoC架构中,每一个模块都连接到片上路由器,而模块传输的数据则是形成了一个个数据包,通过路由器去送达数据包的目标模块。
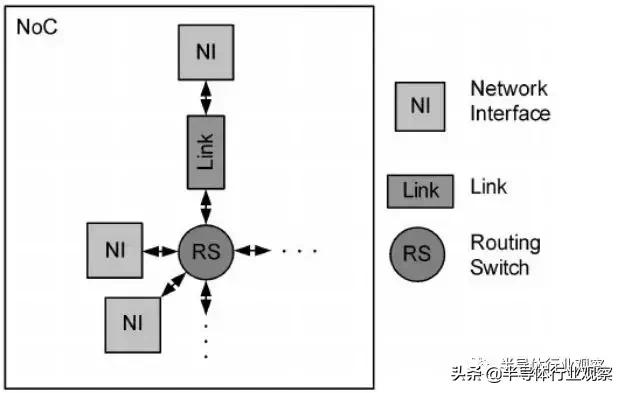
与片上总线和Crossbar相比,NoC的主要优势可以体现在横向和纵向两方面。横向的优势是指当片上使用互联的模块数量增加时,NoC的复杂度并不会上升很多。这也是符合直觉的,因为NoC使用了类似计算机网络的架构,因此可以更好地支持多个互联模块,同时可以轻松地加入更多互联模块——这和我们把一台新的电脑接入互联网而几乎不会对互联网造成影响一样。与NoC相比,片上总线和Crossbar在互联模块数量上升时就显得有些力不从心,尤其是Crossbar的互联复杂性与互联模块的数量呈指数关系,因此一旦加入更多模组其后端物理设计就会要完全重做。当然,NoC为了实现可扩展性,也需要付出路由器逻辑之类的额外开销。因此,在互联模块数量较少时,片上总线和Crossbar因为设计简单而更适合;而一旦片上互联模块数量上升时(如大于30个模块),NoC的优势就得到体现,这时候路由器逻辑和网络协议的开销就可以忽略不计,因此在互联模块数量较多时NoC可以实现更高的性能,同时面积却更小。
NoC纵向的优势则来自于其物理层、传输层和接口是分开的。拿传统的总线为例,ARM的AXI接口在不同的版本定义了不同的信号,因此在使用不同版本的AXI时候,一方面模块的接口逻辑要重写,另一方面AXI矩阵的逻辑、物理实现和接口也要重写,因此造成了IP复用和向后兼容上的麻烦。而NoC中,传输层、物理层和接口是分开的,因此用户可以在传输层方便地自定义传输规则,而无需修改模块接口,而另一方面传输层的更改对于物理层互联的影响也不大,因此不用担心修改了传输层之后对于NoC的时钟频率造成显著的影响。
异构计算时代,NoC渐成主流
如前所述,一旦SoC上的模块数量上升时,NoC的优势就得到了体现。而在异构计算逐渐成为主流的今天,NoC也就顺应潮流成为了系统中越来越重要的一部分。
众所周知,随着半导体工艺特征尺寸缩小越来越接近物理极限,半导体工艺的每一步前进都要付出巨大的代价,而摩尔定律对于每隔18个月集成度翻倍的预言也渐渐成为了历史。在过去,根据摩尔定律缩小特征尺寸能带来晶体管集成度上升,从而降低成本;另外晶体管面积缩小还带来了性能上升。而在今天,由于先进工艺制程越来越复杂,28nm之后晶体管缩小带来的成本优势正在被巨大的一次NRE成本所抵消,更关键的是晶体管的性能在先进工艺下的提升已经逐渐趋近饱和。
在这样的情况下,处理器芯片的性能提升已经不能依赖半导体工艺带来的晶体管性能提升,而是要更多地依靠芯片架构上的提升。在芯片架构方面,异构计算在摩尔定律接近失效的今天得到了广泛的认可。
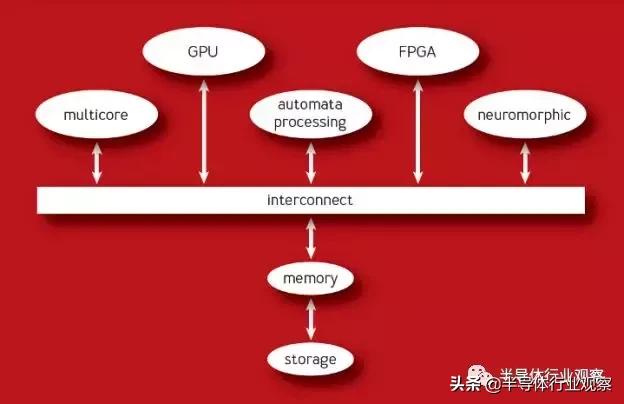
异构计算芯片架构示意图
在摩尔定律的黄金时代,通用计算是时代的主流,因为随着摩尔定律的发展通用处理器的性能每过一段时间都会翻番,所以去设计专用化的处理模块的意义并不大。相反,在摩尔定律接近实效的今天,为了能实现处理器性能的提升,最可行的方法就是针对每一种计算去设计专用的计算模块,从而实现性能的提升,这也就是异构计算的思路。异构计算的芯片架构中,多个专用计算模块会通过片上互联去访问存储器,同时也会通过片上互联去互相通信,因此片上互联在异构计算时代正在扮演越来越重要的角色。而在使用异构计算思想设计的SoC中,这样的专用模块数量正在上升到数十个,因此NoC成了实现片上互联的***实现方式。而随着未来异构计算范式得到更多认可和应用,我们可以预见片上互联会需要连接越来越多数量的模块,因此NoC设计的重要性也将会提升。
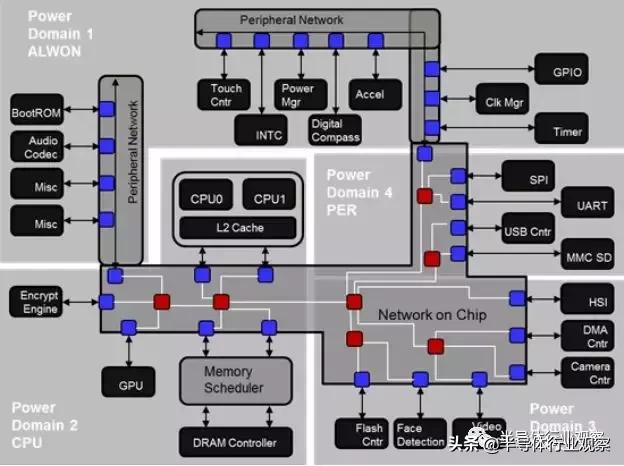
使用Sonics提供的NoC IP的芯片架构示意图
巨头收购NoC IP供应商的背后
Facebook、Intel等巨头收购NoC IP供应商,首先说明了NoC在今天SoC架构中的重要性。如前所述,目前SoC架构中,异构计算正在成为主流架构。“异构计算”至少包含“异构”和“计算”两个方面,“异构”意味着 SoC中不同IP的数量越来越多,而“计算”则意味着每个IP都会需要大量的数据以及相应的带宽以完成相应任务。当把多个IP以计算为目的组成异构计算的芯片时,片上互联往往会成为性能的瓶颈,因此NoC这样的先进片上互联架构正好能帮助异构计算架构的芯片解决互联瓶颈。去年Intel收购NoC IP供应商Netspeed时,时任Intel相关负责人的Jim Keller就在声明中表示“Intel正在为芯片设计加入更多的专用(计算)特性,而Intel面临的挑战则来自于如何能在合理的时间和预算内为每个专用计算设计***化的IP模块”。Keller的声明几乎完全印证了异构计算的思路,而Netspeed的NoC IP则能解决异构计算芯片上的互联瓶颈问题。
除了技术上的考虑之外,在商业上来说,巨头收购NoC IP供应商可以从“进攻”和“防守”两个角度来理解。“进攻”的角度上来说,由于NoC正在变得越来越重要,因此巨头们希望能有自己独特的NoC IP,在实现优秀的性能之外,甚至有可能基于该IP做自己的独特芯片架构,从而实现芯片性能的跨代式领先。如果要做这样的定制化高性能NoC,与NoC IP厂商的通常性商务合作往往无法达到目的,而如果自己组建团队从头做起则速度太慢,因此在NoC IP公司价格合理的情况下收购是最合适的选择。从“防守”的角度上来说,一旦为自己提供NoC IP的公司经营不善无法继续提供IP,或者甚至被竞争对手买走,那么自己要切换到另一家公司的NoC IP会需要许多时间,出于这种考虑,还不如把自己用得最顺手的NoC IP公司直接买下,也就避免了这些麻烦。相信Facebook和Intel收购NoC IP公司,都有出自于这两方面的考虑。