随着我们的应用程序的不断增长并开始进行复杂的计算时,对速度的需求越来越高(🏎️),所以流程的优化变得必不可少。 当我们忽略这个问题时,我们最终的程序需要花费大量时间并在执行期间消耗大量的系统资源。
缓存是一种优化技术,通过存储开销大的函数执行的结果,并在相同的输入再次出现时返回已缓存的结果,从而加快应用程序的速度。
如果这对你没有多大意义,那没关系。 本文深入解释了为什么需要进行缓存,缓存是什么,如何实现以及何时应该使用缓存。
什么是缓存
缓存是一种优化技术,通过存储开销大的函数执行的结果,并在相同的输入再次出现时返回已缓存的结果,从而加快应用程序的速度。
在这一点上,我们很清楚,缓存的目的是减少执行“昂贵的函数调用”所花费的时间和资源。
什么是昂贵的函数调用?别搞混了,我们不是在这里花钱。在计算机程序的上下文中,我们拥有的两种主要资源是时间和内存。因此,一个昂贵的函数调用是指一个函数调用中,由于计算量大,在执行过程中大量占用了计算机的资源和时间。
然而,就像对待金钱一样,我们需要节约。为此,使用缓存来存储函数调用的结果,以便在将来的时间内快速方便地访问。
缓存只是一个临时的数据存储,它保存数据,以便将来对该数据的请求能够更快地得到处理。
因此,当一个昂贵的函数被调用一次时,结果被存储在缓存中,这样,每当在应用程序中再次调用该函数时,结果就会从缓存中非常快速地取出,而不需要重新进行任何计算。
为什么缓存很重要?
下面是一个实例,说明了缓存的重要性:
想象一下,你正在公园里读一本封面很吸引人的新小说。每次一个人经过,他们都会被封面吸引,所以他们会问书名和作者。***次被问到这个问题的时候,你翻开书,读出书名和作者的名字。现在越来越多的人来这里问同样的问题。你是一个很好的人🙂,所以你回答所有问题。
你会翻开封面,把书名和作者的名字一一告诉他,还是开始凭记忆回答?哪个能节省你更多的时间?
发现其中的相似之处了吗?使用记忆法,当函数提供输入时,它执行所需的计算并在返回值之前将结果存储到缓存中。如果将来接收到相同的输入,它就不必一遍又一遍地重复,它只需要从缓存(内存)中提供答案。
缓存是怎么工作的
JavaScript 中的缓存的概念主要建立在两个概念之上,它们分别是:
- 闭包
- 高阶函数(返回函数的函数)
闭包
闭包是函数和声明该函数的词法环境的组合。
不是很清楚? 我也这么认为。
为了更好的理解,让我们快速研究一下 JavaScript 中词法作用域的概念,词法作用域只是指程序员在编写代码时指定的变量和块的物理位置。如下代码:
- function foo(a) {
- var b = a + 2;
- function bar(c) {
- console.log(a, b, c);
- }
- bar(b * 2);
- }
- foo(3); // 3, 5, 10
从这段代码中,我们可以确定三个作用域:
- 全局作用域(包含 foo 作为唯一标识符)
- foo 作用域,它有标识符 a、b 和 bar
- bar 作用域,包含 c 标识符
仔细查看上面的代码,我们注意到函数 foo 可以访问变量 a 和 b,因为它嵌套在 foo 中。注意,我们成功地存储了函数 bar 及其运行环境。因此,我们说 bar 在 foo 的作用域上有一个闭包。
你可以在遗传的背景下理解这一点,即个体有机会获得并表现出遗传特征,即使是在他们当前的环境之外,这个逻辑突出了闭包的另一个因素,引出了我们的第二个主要概念。
从函数返回函数
通过接受其他函数作为参数或返回其他函数的函数称为高阶函数。
闭包允许我们在封闭函数的外部调用内部函数,同时保持对封闭函数的词法作用域的访问
让我们对前面的示例中的代码进行一些调整,以解释这一点。
- function foo(){
- var a = 2;
- function bar() {
- console.log(a);
- }
- return bar;
- }
- var baz = foo();
- baz();//2
注意函数 foo 如何返回另一个函数 bar。这里我们执行函数 foo 并将返回值赋给baz。但是在本例中,我们有一个返回函数,因此,baz 现在持有对 foo 中定义的bar 函数的引用。
最有趣的是,当我们在 foo 的词法作用域之外执行函数 baz 时,仍然会得到 a 的值,这怎么可能呢?😕
请记住,由于闭包的存在,bar 总是可以访问 foo 中的变量(继承的特性),即使它是在 foo 的作用域之外执行的。
案例研究:斐波那契数列
斐波那契数列是什么?
斐波那契数列是一组数字,以1 或 0 开头,后面跟着1,然后根据每个数字等于前两个数字之和规则进行。如
- 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
或者
- 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
挑战:编写一个函数返回斐波那契数列中的 n 元素,其中的序列是:
- [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …]
知道每个值都是前两个值的和,这个问题的递归解是:
- function fibonacci(n) {
- if (n <= 1) {
- return 1
- }
- return fibonacci(n - 1) + fibonacci(n - 2)
- }
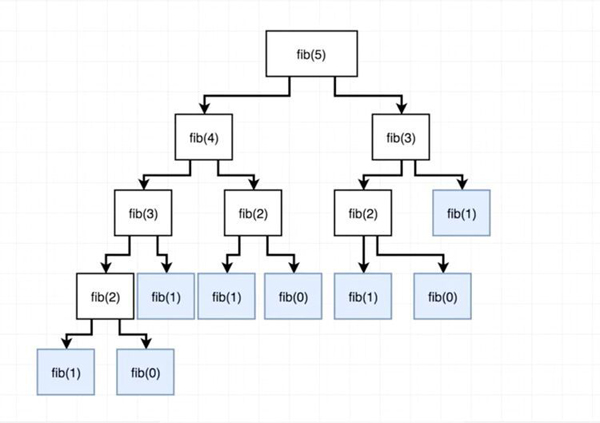
确实简洁准确!但是,有一个问题。请注意,当 n 的值到终止递归之前,需要做大量的工作和时间,因为序列中存在对某些值的重复求值。
看看下面的图表,当我们试图计算 fib(5)时,我们注意到我们反复地尝试在不同分支的下标 0,1,2,3 处找到 Fibonacci 数,这就是所谓的冗余计算,而这正是缓存所要消除的。
- function fibonacci(n, memo) {
- memomemo = memo || {}
- if (memo[n]) {
- return memo[n]
- }
- if (n <= 1) {
- return 1
- }
- return memo[n] = fibonacci(n-1, memo) + fibonacci(n-2, memo)
- }
在上面的代码片段中,我们调整函数以接受一个可选参数 memo。我们使用 memo 对象作为缓存来存储斐波那契数列,并将其各自的索引作为键,以便在执行过程中稍后需要时检索它们。
- memomemo = memo || {}
在这里,检查是否在调用函数时将 memo 作为参数接收。如果有,则初始化它以供使用;如果没有,则将其设置为空对象。
- if (memo[n]) {
- return memo[n]
- }
接下来,检查当前键 n 是否有缓存值,如果有,则返回其值。
和之前的解一样,我们指定了 n 小于等于 1 时的终止递归。
***,我们递归地调用n值较小的函数,同时将缓存值(memo)传递给每个函数,以便在计算期间使用。这确保了在以前计算并缓存值时,我们不会第二次执行如此昂贵的计算。我们只是从 memo 中取回值。
注意,我们在返回缓存之前将最终结果添加到缓存中。
使用 JSPerf 测试性能
可以使用些链接来性能测试。在那里,我们运行一个测试来评估使用这两种方法执行fibonacci(20) 所需的时间。结果如下:
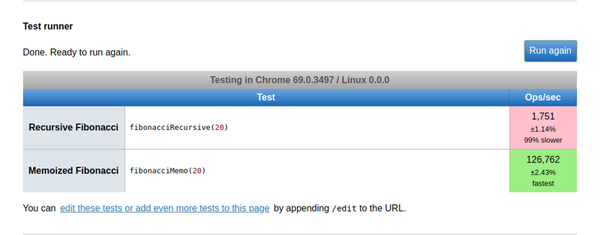
哇! ! !这让人很惊讶,使用缓存的 fibonacci 函数是最快的。然而,这一数字相当惊人。它执行 126,762 ops/sec,这远远大于执行 1,751 ops/sec 的纯递归解决方案,并且比较没有缓存的递归速度大约快 99%。
注:“ops/sec”表示每秒的操作次数,就是一秒钟内预计要执行的测试次数。
现在我们已经看到了缓存在函数级别上对应用程序的性能有多大的影响。这是否意味着对于应用程序中的每个昂贵函数,我们都必须创建一个修改后的变量来维护内部缓存?
不,回想一下,我们通过从函数返回函数来了解到,即使在外部执行它们,它们也会导致它们继承父函数的范围,这使得可以将某些特征和属性从封闭函数传递到返回的函数。
使用函数的方式
在下面的代码片段中,我们创建了一个高阶的函数 memoizer。有了这个函数,将能够轻松地将缓存应用到任何函数。
- function memoizer(fun) {
- let cache = {}
- return function (n) {
- if (cache[n] != undefined) {
- return cache[n]
- } else {
- let result = fun(n)
- cache[n] = result
- return result
- }
- }
- }
上面,我们简单地创建一个名为 memoizer 的新函数,它接受将函数 fun 作为参数进行缓存。在函数中,我们创建一个缓存对象来存储函数执行的结果,以便将来使用。
从 memoizer 函数中,我们返回一个新函数,根据上面讨论的闭包原则,这个函数无论在哪里执行都可以访问 cache。
在返回的函数中,我们使用 if..else 语句检查是否已经有指定键(参数) n 的缓存值。如果有,则取出并返回它。如果没有,我们使用函数来计算结果,以便缓存。然后,我们使用适当的键 n 将结果添加到缓存中,以便以后可以从那里访问它。***,我们返回了计算结果。
很顺利!
要将 memoizer 函数应用于最初递归的 fibonacci 函数,我们调用 memoizer 函数,将 fibonacci 函数作为参数传递进去。
- const fibonacciMemoFunction = memoizer(fibonacciRecursive)
测试 memoizer 函数
当我们将 memoizer 函数与上面的例子进行比较时,结果如下:
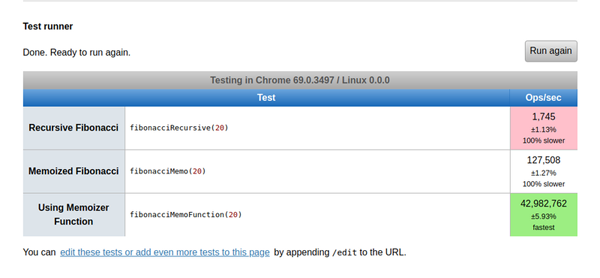
memoizer 函数以 42,982,762 ops/sec 的速度提供了最快的解决方案,比之前考虑的解决方案速度要快 100%。
关于缓存,我们已经说明什么是缓存 、为什么要有缓存和如何实现缓存。现在我们来看看什么时候使用缓存。
何时使用缓存
当然,使用缓存效率是级高的,你现在可能想要缓存所有的函数,这可能会变得非常无益。以下几种情况下,适合使用缓存:
- 对于昂贵的函数调用,执行复杂计算的函数。
- 对于具有有限且高度重复输入范围的函数。
- 用于具有重复输入值的递归函数。
- 对于纯函数,即每次使用特定输入调用时返回相同输出的函数。
缓存库
- Lodash
- Memoizer
- Fastmemoize
- Moize
- Reselect for Redux
总结
使用缓存方法 ,我们可以防止函数调用函数来反复计算相同的结果,现在是你把这些知识付诸实践的时候了。