本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
想自己构建机器学习模型,没想到首先就卡在了***步。
网上各种数据集鱼龙混杂,质量也参差不齐,简直让人挑花了眼。想要获取大型数据集,还要挨个跑到各数据集的网站,两个字:麻烦。
如何才能高效找到机器学习领域规模***、质量***的数据集?
为了响应广大网友的呼声,网友u/UpdraftDev将全网***的机器学习数据集整理汇集,并对这些数据集进行了分类和介绍。
想找心仪数据集,现在一目了然。网友纷纷表示:很满意!
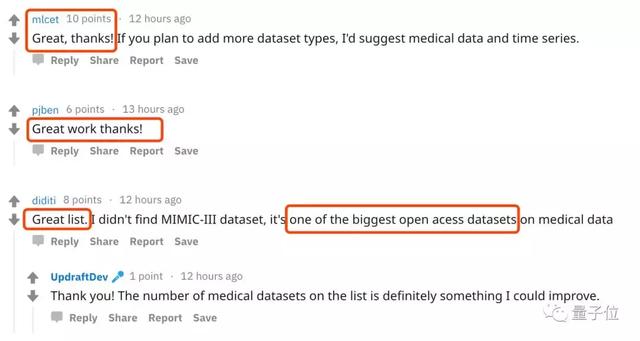
太方便了
这个网站上,共收集到了100多个业界***型的数据集。
根据任务类别,这些数据集中又分为三大类:计算机视觉(CV)、自然语言处理(NLP)和音频数据集。
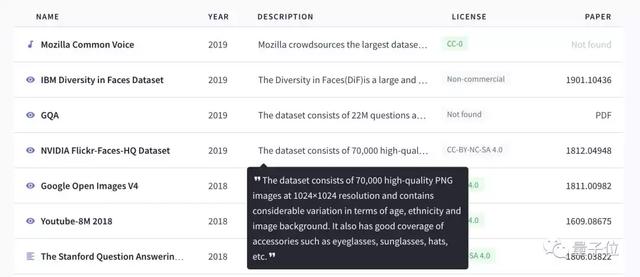
在网站主页,一眼扫过去可以看到数据集名称、发布时间、简要介绍、开源协议、相关论文等重要信息,查找起来非常方便。
点进去就直接跳转到网站主页了,轻轻一点,免去了你挨个搜索每个数据集地址的麻烦。
神仙数据集
清单中列举的数据集中,不乏一些有趣的业界知名数据集,在很多的机器学习任务中,这些数据集都是最实用、出现场次***的那一批。
都是哪些神仙数据集?
计算机视觉领域
先来看一下CV领域,汇总中收纳了70个大型数据集,很多经常遇到的经典数据集都在里面。
看看你能认出几个:

其中,包含了英伟达去年12月开源的人脸数据集FFHQ(Flickr-Faces-HQ),内含7万张1024×1024分辨率的高清人脸大图。
它提供了高度多样化、高质量的人脸数据,并且涵盖了比现有高分辨率数据集(如CelebA-HQ)更多的变化,比如更多佩戴眼镜、帽子的照片。
也有一些熟悉的中国企业身影。
比如百度开放的自动驾驶数据集ApolloScape,包括感知、仿真场景、路网数据等数十万帧逐像素语义分割标注的高分辨率图像数据。
数据集采用了逐像素语义分割标注的方式,是环境复杂、标注精准、数据量大的自动驾驶数据集。
腾讯开源的Tencent ML-Images项目,其多标签图像数据集ML-Images包含了1800万图像和1.1万多种常见物体类别,比谷歌开源的Open Images数据集还丰富不少。
当然,像ImageNet、KITTI、COCO、Cityscapes等这样的老牌经典数据集也都在里面。
自然语言处理(NLP)领域
NLP领域目前有26个数据集:
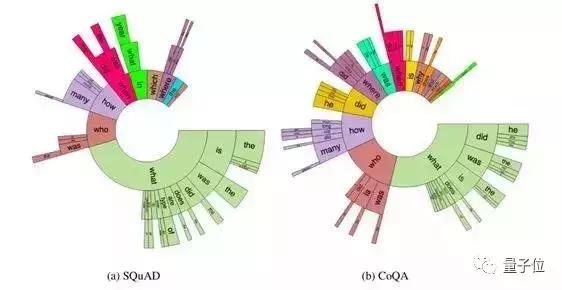
斯坦福大学NLP组的SQuAD 2.0你得了解一下,和一代相比,2.0版在增加对抗性问题的同时,也新增了一项“判断一个问题能否根据提供的阅读文本作答”的任务。
SQuAD 2.0中不仅包含十万个问题-答案对,还有超过五万个由人类众包者对抗性地设计的无法回答的问题。

CoQA数据集也是斯坦福开发的对话数据集,包含来自8k组对话的127k个带有答案的问题。这些对话涉及 7 个不同领域,每组对话的平均长度为15轮,每一轮对话都由问题和回答组成。
此外,DeepMind的Q&A问答数据集、微软的MS MARCO机器阅读理解数据集、三名中国学生推出的HotpotQA新型问答数据集等,都可以在这份清单中一键直达。
音频数据集
还有四个大型音频数据集:
谷歌的大规模音频数据集AudioSet,包含632类的音频类别以及2084320 条人工标记的每段10秒的声音剪辑片段,覆盖大范围人类与动物、乐器与音乐流派、日常环境声音。

谷歌NSynth数据集,收录了从1000种乐器中采集的大量注释的音符,包括不同的音高和速率,比同类的公共数据集大了一个数量级。
初创公司Mozilla公布的Common Voice数据集,内含2万名英语志愿者500小时、40万份录音,语料库也在不断扩充中。
还有LibriSpeech ASR corpus语音数据集,包括1000小时的英文发音和对应文字,数据来自LibriVox项目的有声读物,是一个大型的语料数据库。