算法是大数据的最核心价值部分。大数据的挖掘是从海量、不完整、噪声、模糊、随机、碎片数据中发现其中隐藏的价值,以及潜在的有用信息和知识的过程。什么情况用什么算法呢?今天给大家做个大数据算法入门。
一、统计分布
统计分布(frequency distribution)亦称“次数(频数)分布(分配)”。在统计分组的基础上,将总体中的所有单位按组归类整理,形成总体单位在各组间的分布。分布在各组中的单位数叫做次数或频数。各组次数与总次数(全部总体单位数)之比,称为比率或频率。将各组别与次数依次编排而成的数列就叫做统计分布数列,简称分布数列或分配数列。它可以反映总体中所有单位在各组间的分布状态和分布特征,研究这种分布特征是统计分析的一项重要内容。如上的BLABLA的一堆,具体来看看到底能干什么吧。
1)平均值
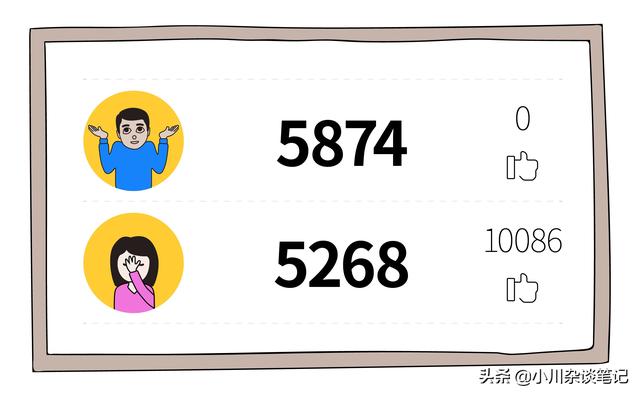
举个栗子!中国男人背上“油腻”一词好几年了,根据《2017中国人运动报告》数据显示,至少在步行量上,男生要高于女生:男生平均每天走5874步,女生日均步数达到5268步。注重运动加上更新一下观念,中国男人或许能保持一下少年感。
2)同比和环比
同比一般情况下是今年第n月与去年第n月比。
环比,表示连续2个单位周期(比如连续两月)内的量的变化比。

3)高斯分布
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
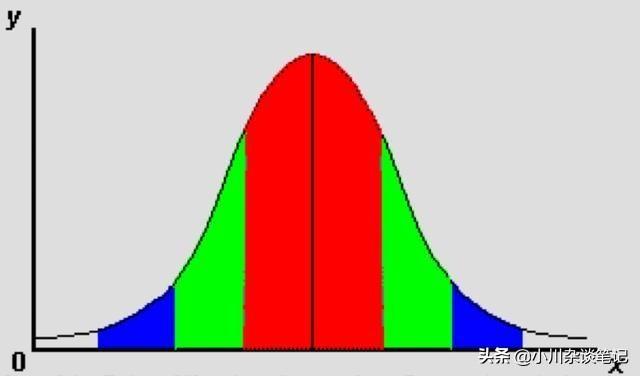
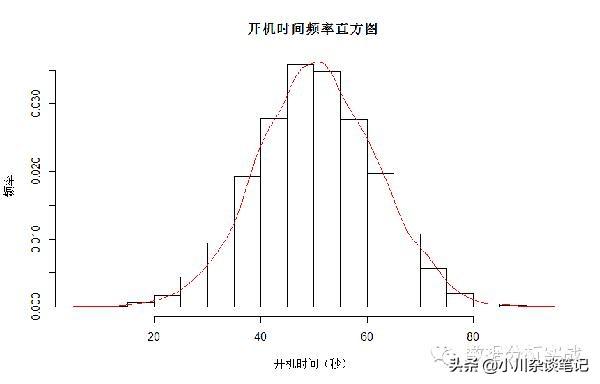
高斯分布怎么用?举个栗子:这张图大家都见过吧。收集尽量多的用户的开机时间,然后,查看时间的分布如何。
4)柏松分布
Poisson分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
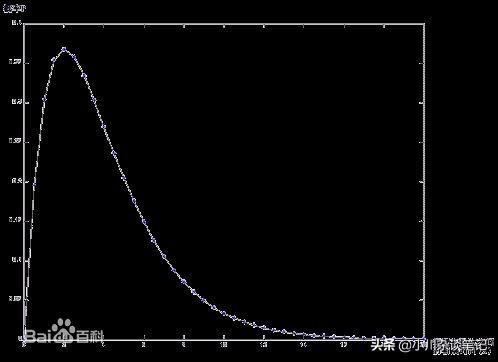
小小柏松分布在大数据领域可以解决大大的问题!干货来了!
栗子1:玩电商和仓储的,进来看看。已知某家小杂货店,平均每周售出2个水果罐头。请问该店水果罐头的***库存量是多少?
假定不存在季节因素,可以近似认为,这个问题满足以下三个条件:
- a.顾客购买水果罐头是小概率事件。
- b.购买水果罐头的顾客是独立的,不会互相影响。
- c.顾客购买水果罐头的概率是稳定的。
在统计学上,只要某类事件满足上面三个条件,它就服从"泊松分布"。
根据公式,计算得到每周销量的分布:从上表可见,如果存货4个罐头,95%的概率不会缺货(平均每19周发生一次);如果存货5个罐头,98%的概率不会缺货(平均59周发生一次)。
5)伯努利分布
伯努利分布(英语:Bernoulli distribution,又名两点分布或者0-1分布,是一个离散型概率分布,为纪念瑞士科学家雅各布·伯努利而命名。)。通俗讲,一件事情,只有两种可能的结果。伯努利分布描述了其中一种结果的概率为a,另一种结果的概率为100%-a。再通俗的讲,生一次孩子,生男孩子概率为p,生女孩纸概率1-p,这个就是伯努利分布。