作为Linux系统运维人员,需要实时掌握Linux系统的运行负载,网络状态,磁盘,内存使用情况。所以作为开源监控警报系统prometheus, 官方自然给大家提供了这样一套工具,可以监控多个服务器的实时运行状况,以及实时警告。
Prometheus提供了node_exporter给广大运维人员使用,这是一个相当强大,且统计全面的工具。https://github.com/prometheus/node_exporter, 这个是node_exporter的github地址。
启动node_exporter非常简单,官方提供了docker镜像给我们使用,我们只需要简单的命令就可以把node_exporter启动起来。
- $ docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" quay.io/prometheus/node-exporter --path.rootfs /host
net指定host,表示我们启动的container共享主机的网络信息,可以直接访问主机上的网络信息。
pid指定host,container里面可以获取主机上的所有进程运行信息。
同时,为了了解文件系统的信息,需要把物理机的根目录/挂载到docker的/host目录,并告诉node_exporter容器,在container里面哪个是物理机的根目录,在这里就是/host。
启动之后,node_exporter默认监听的端口是9100,这个时候我们就可以直接测试metrics是否可以拿到。
- $ curl http://127.0.0.1:9100/metrics
这时候我们就会拿到node_exporter所有的metrics。
接下来,需要配置prometheus去哪里采集node_exporter的metrics信息,添加target到prometheus里面。
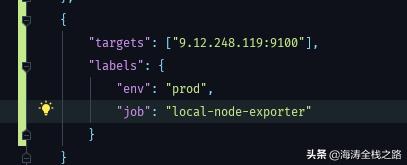
添加node exporter目标
这里我们添加了一个新的targets用于采集node_exporter的metrics。
然后,我们需要添加官方提供node_exporter的grafana dashboard。
https://grafana.com/dashboards/1860
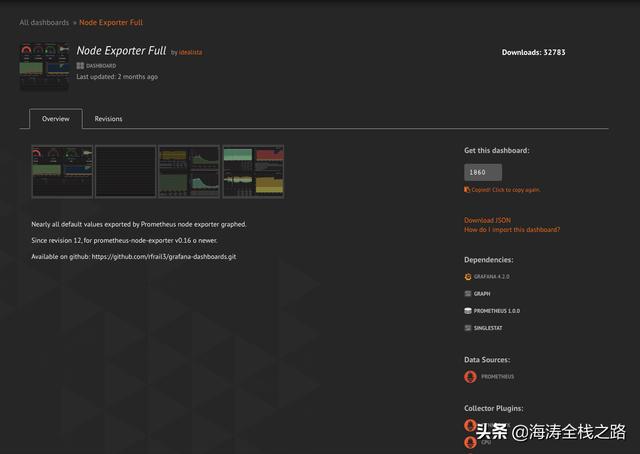
node_exporter dashboard
点击右边的Copy ID to clipboard.或者是download json文件。
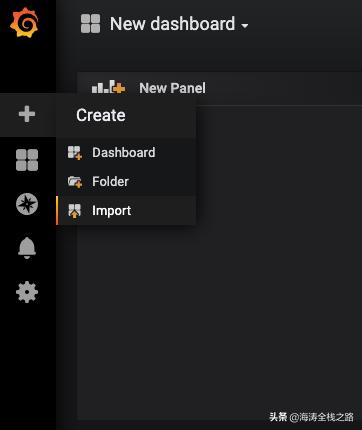
导入新的dashboard
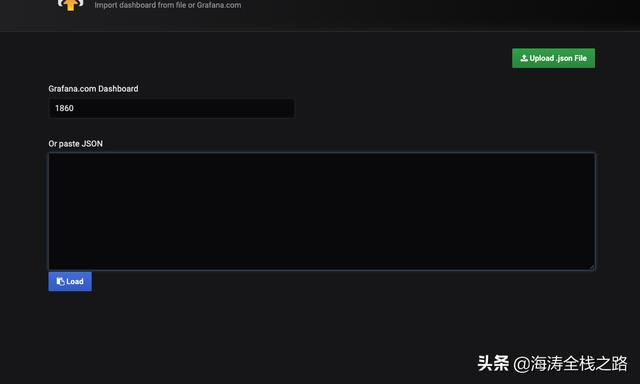
拷贝ID到表单里
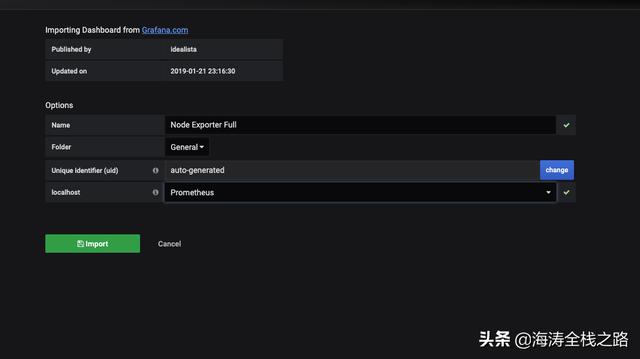
grafana自动从官网的仓库中,下载json文件,选择数据源。
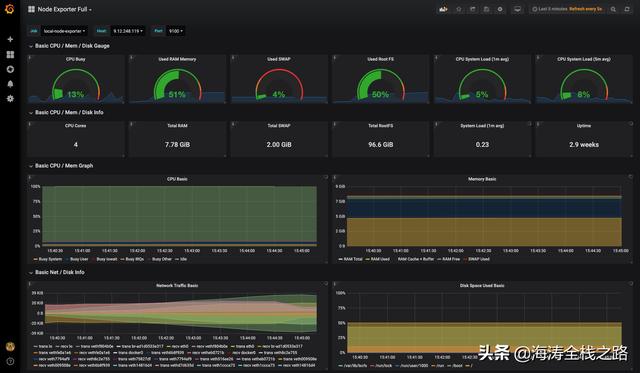
服务运行状况图表
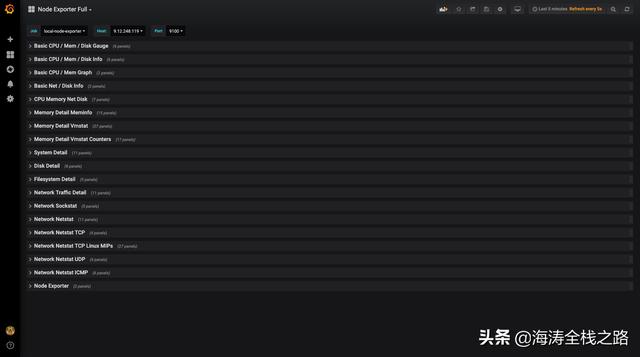
监控的层面
然后我们可以看到在grafana新建的dashboard中,会出现从各个层面拿到的实时的运行状态的数据。后面我们就可以通过grafana的alert或是prometheus的alertmanager组件来根据设定好的阈值来发警告给运维人员。