简介
本文介绍了一个简单的静态资源服务器的实例项目,希望能给Node.js初学者带来帮助。项目涉及到http、fs、url、path、zlib、process、child_process等模块,涵盖大量常用api;还包括了基于http协议的缓存策略选取、gzip压缩优化等;最终我们会发布到npm上,做成一个可以全局安装、使用的小工具。麻雀虽小,五脏俱全,一想是不是还有点小激动?话不多说,放码过来。
文中源码地址在附录中。
可先行体验项目效果:
安装:npm i -g here11
任意文件夹地址输入命令:here
step1 新建项目
因为我们要发布到npm上,所以我们先按照国际惯例,npm init,走你!在命令行可以一路回车,有些配置会在后面的发布步骤中细说。
目录结构如下:
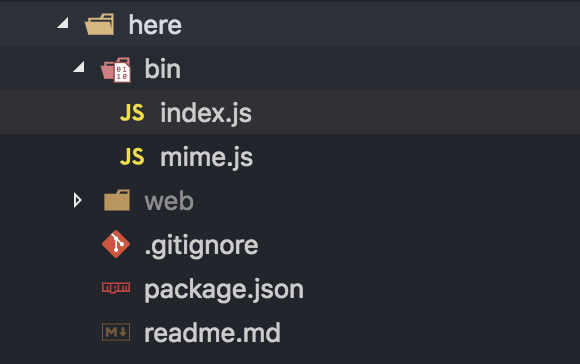
bin文件夹存放我们的执行代码,web作为一个测试文件夹,里面放了些网页。
step2 码码
step2.1 雏形
静态资源服务器,通俗讲就是我们在浏览器地址栏输入形如“http://域名/test/index.html”的一个地址,服务器从根目录下的对应文件夹找到index.html,读出文件内容并返回给浏览器,浏览器渲染给用户。
- const http = require("http");
- const url = require("url");
- const fs = require("fs");
- const path = require("path");
- const item = (name, parentPath) => {
- let path = parentPath = `${parentPath}/${name}`.slice(1);
- return `<div><a href="${path}">${name}</a></div>`;
- }
- const list = (arr, parentPath) => {
- return arr.map(name => item(name, parentPath)).join("");
- }
- const server = http.createServer((req, res) => {
- let _path = url.parse(req.url).pathname;//去掉search
- let parentPath = _path;
- _path = path.join(__dirname, _path);
- try {
- //拿到路径所对应的文件描述对象
- let stats = fs.statSync(_path);
- if (stats.isFile()) {
- //是文件,返回文件内容
- let file = fs.readFileSync(_path);
- res.end(file);
- } else if (stats.isDirectory()) {
- //是目录,返回目录列表,让用户可以继续点击
- let dirArray = fs.readdirSync(_path);
- res.end(list(dirArray, parentPath));
- } else {
- res.end();
- }
- } catch (err) {
- res.writeHead(404, "Not Found");
- res.end();
- }
- });
- const port = 2234;
- const hostname = "127.0.0.1";
- server.listen(port, hostname, () => {
- console.log(`server is running on http://${hostname}:${port}`);
- });
以上这段code就是我们的核心代码了,已经实现了核心功能,本地运行即可看到返回了文件目录,点击文件名便可浏览对应的网页、图片、文本啦。
step2.2 优化
功能实现了,但是我们可以在某些方面做做优化,提升实用性,顺便多学习几个api。
1. stream
我们目前读取文件返回给浏览器的操作是通过readFile一次性读出来,一次性返回,这样当然可以实现功能,但我们有更好的方式——用stream(流)进行IO操作。stream并不是node.js独有的概念,而是操作系统最基本的一种操作形式,所以理论上讲,任何一门server端语言都实现了stream的API。
为什么讲用stream是一种更好的方式?因为一次性读取、操作大文件,内存和网络是吃不消的,尤其在用户访问量比较大的情况下更为明显;而借助stream可以让数据流动起来,一点一点操作,从而提升性能。代码修改如下:
- if (stats.isFile()) {
- //是文件,返回文件内容
- //在createServer时传入的回调函数被添加到了"request"事件上,回调函数的两个形参req和res
- //分别为http.IncomingMessage对象和http.ServerResponse对象
- //并且它们都实现了流接口
- let readStream = fs.createReadStream(_path);
- readStream.pipe(res);
- }
编码实现非常简单,在需要返回文件内容时,我们创建了一个可读流,并把它直接导向了res对象。
2. gzip压缩
gzip压缩带来的性能(用户访问体验)提升是非常明显的,开启gzip压缩,可以大幅减小js、css等文件资源的体积,提升用户访问速度。作为一个静态资源服务器,我们当然要加上这个功能。
node中有一个zlib的模块,提供了很多压缩相关的api,我们就用它来实现:
- const zlib = require("zlib");
- if (stats.isFile()) {
- //是文件,返回文件内容
- res.setHeader("content-encoding", "gzip");
- const gzip = zlib.createGzip();
- let readStream = fs.createReadStream(_path);
- readStream.pipe(gzip).pipe(res);
- }
有了stream的使用经验,我们再看这段代码的时候就好理解多了。把文件流先导向gzip对象,再导向res对象。此外,使用gzip压缩的时候还需要注意一点:需要把响应头里的content-encoding设置为gzip。否则浏览器会把一堆乱码展示出来。
3. http缓存
缓存这个东西让人又爱又恨,用得好,可以提升用户体验,减轻服务器压力;用得不好,可能就会面临各种各样奇奇怪怪的问题。一般来讲浏览器http缓存分为强缓存(非验证性缓存)和协商缓存(验证性缓存)。
什么叫强缓存呢?强缓存是由cache-control和expires两个首部字段控制的,现在一般用cache-control。比如我们设置了cache-control: max-age=31536000的响应头,就是告诉浏览器这个资源有一年的缓存期,一年内不用向服务端发送请求,直接从缓存中读取资源。
而协商性缓存是使用if-modified-since/last-modified、if-none-match/etag等首部字段,配合强缓存,在强缓存没有命中(或告知浏览器no-cache)的时候,向服务器发送请求,确认资源的有效性,决定从缓存中读取或是返回新的资源。
有了以上概念,我们便可以制定我们的缓存策略:
- if (stats.isFile()) {
- //是文件,返回文件内容
- //增加判断文件是否有改动,没有改动返回304的逻辑
- //从请求头获取modified时间
- let IfModifiedSince = req.headers["if-modified-since"];
- //获取文件的修改日期——时间戳格式
- let mtime = stats.mtime;
- //如果服务器上的文件修改时间小于等于请求头携带的修改时间,则认定文件没有变化
- if (IfModifiedSince && mtime <= new Date(IfModifiedSince).getTime()) {
- //返回304
- res.writeHead(304, "not modify");
- return res.end();
- }
- //第一次请求或文件被修改后,返回给客户端新的修改时间
- res.setHeader("last-modified", new Date(mtime).toString());
- res.setHeader("content-encoding", "gzip");
- let reg = /\.html$/;
- //不同的文件类型设置不同的cache-control
- if (reg.test(_path)) {
- //我们对html文件执行每次必须向服务器验证资源有效性的策略
- res.setHeader("cache-control", "no-cache");
- } else {
- //我们对其余的静态资源文件采取强缓存策略,一个月内无需向服务器索取
- res.setHeader("cache-control", `max-age=${1 * 60 * 60 * 24 * 30}`);
- }
- //执行gzip压缩
- const gzip = zlib.createGzip();
- let readStream = fs.createReadStream(_path);
- readStream.pipe(gzip).pipe(res);
- }
这样一套缓存策略在现代前端项目体系下还是比较合适的,尤其是对于spa应用来讲。我们希望index.html能够保证每次向服务器验证是否有更新,而其余的文件统一本地缓存一个月(自己定);通过webpack打包或其他工程化方式构建之后,js、css内容如果发生变化,文件名相应更新,index.html插入的manifest(或script链接、link链接等)清单会更新,保证用户能够实时得到新的资源。
当然,缓存之路千万条,适合业务才重要,大家可以灵活制定。
4. 命令行参数
作为一个在命令行执行的工具,怎么能不象征性的支持几个参数呢?
- const config = {
- //从命令行中获取端口号,如果未设置采用默认
- port: process.argv[2] || 2234,
- hostname: "127.0.0.1"
- }
- server.listen(config.port, config.hostname, () => {
- console.log(`server is running on http://${config.hostname}:${config.port}`);
- });
这里就简单的举个栗子啦,大家可以自由发挥!
5. 自动打开浏览器
虽然没太大卵用,但还是要加。我就是要让你们知道,我加完之后什么样,你们就是什么样 :-( duang~
- const exec = require("child_process").exec;
- server.listen(config.port, config.hostname, () => {
- console.log(`server is running on http://${config.hostname}:${config.port}`);
- exec(`open http://${config.hostname}:${config.port}`);
- });
6. process.cwd()
用process.cwd()代替__dirname。
我们最终要做成一个全局并且可以在任意目录下调用的命令,所以拼接path的代码修改如下:
- //__dirname是当前文件的目录地址,process.cwd()返回的是脚本执行的路径
- _path = path.join(process.cwd(), _path);
step3 发布
基本上我们的代码都写完了,可以考虑发布了!
step3.1 package.json
得到一个配置类似下面所示的json文件:
- {
- "name": "here11",
- "version": "0.0.13",
- "private": false,
- "description": "a node static assets server",
- "bin": {
- "here": "./bin/index.js"
- },
- "repository": {
- "type": "git",
- "url": "https://github.com/gww666/here.git"
- },
- "scripts": {
- "test": "node bin/index.js"
- },
- "keywords": [
- "node"
- ],
- "author": "gw666",
- "license": "ISC"
- }
其中bin和private较为重要,其余的按照自己的项目情况填写。
bin这个配置代表的是npm i -g xxx之后,我们运行here命令所执行的文件,“here”这个名字可以随意起。
step3.2 声明脚本执行类型
在index.js文件的开头加上:#!/usr/bin/env node
否则linux上运行会报错。
step3.3 注册npm账号
勉强贴一手命令,还不清楚自行百度:
没有账号的先添加一个,执行:
npm adduser
然后依次填入
Username: your name
Password: your password
Email: yourmail
npm会给你发一封验证邮件,记得点一下,不然会发布失败。
执行登录命令:
npm login
执行发布命令:
npm publish
发布的时候记得把项目名字、版本号、作者、仓库啥的改一下,别填成我的。
还有readme文件写一下,好歹告诉别人咋用,基本上和文首所说的用法是一样的。
好了,齐活。
step3.4
还等啥啊,赶快把npm i -g xxx 这行命令发给你的小伙伴啊。什么?你没有小伙伴?告辞!
附
本文项目源码地址:https://github.com/gww666/here