哇,互联网大数据分析师,听起来好高大上哦,其实不然,做的事情都是***层的事情,打杂的,是业务的仆人,为全公司的人服务。
在你的眼里他们待遇好,白领,挣的钱多!
钱是人力堆出来的
在你的眼里他们制作报表,看起来好高大上,很炫酷,很漂亮!
在你的眼里他们是大数据领域的工作者,处于时代的前列,很潮!
数据种类多,量大,变化快
其实他们就是一群搬砖的。
般的是砖,卖的是苦力
- 脏:是数据很脏,什么空值啊,乱码啊,数据重复啊,什么情况都有。
- 乱:也是数据乱,数据源很多比如来源于app的,web端的,日志,外部api等等,要理清逻辑,清洗数据,清晰的分层,需要下很多功夫。
- 差:首先是公司条件'差',然后是状态差,因为经常加班,***是业务多('差')。
- 累:清洗数据,制作报表和分析报告,很累,过程很漫长,而且需要加班。
他们天天要用hue跑数据,对数据,有时候还会碰到数据倾斜问题,如果没找到原因,会跑一天时间,还没验证数据;
有时候为了验证数据和仓库工程师吵架,有时候是为了取数口径,有时候为了调度,数据为什么还没出来,各种扯皮的事情;
有时候对数据和业务还有运营吵架,有可能是为了需求,有可能是为了口径;
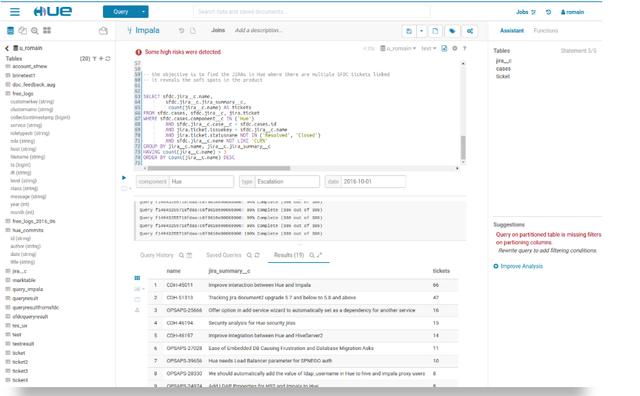
Hadoop组建hue
记得一次为了赶公司的kpi报表,公司从大数据平台组,大数据仓库组,大数据分析组和大数据挖掘组都在加班,确保万无一失,他们是这样分工的:
- 大数据平台组:负责大数据集群稳定运行,负责大数据产品的后端开发。
- 大数据仓库组:负责数据仓库的开发,把各个指标从底层ods开始计算到dm应用层。
- 大数据分析组:负责取数口径的确认,仓库工程师开发的报表验证,有时候自己开发。
- 大数据挖掘组:对有些指标需要机器学习分析出来的,所以他们也要加班。
经过一个星期的加班加点,成果终于出来的,然额并没有什么卵用吗,老板不一定认可。
重来,重来,重来,老板说了三遍,我们很尴尬,分析师更尴尬,因为口径都是这里来的。
不仅做的事情有时候得不到认可,而且没有成就感。
在我们团队中,分析组加班是最多的,有时候还要做仓库的事情,有时候还要管调度,验证数据。
有时候写代码的时候还是***兴的,我们用的工具主要是pycharm,hive,sparksql,shell ,网易有数,这个时候犯错了还能改,bug可以修复。
python功能还是很强大的,我们既可以用来做报表,又可以用来发邮件,又可以用来运维,又可以用来挖掘,简直是全能王。
功能强大的python,什么都可以做
shell是我们部署脚本线上运行的利器。
sparksql基于内存运算的大数据组建,有事给我们验证数据带来方便,我们很是喜欢。
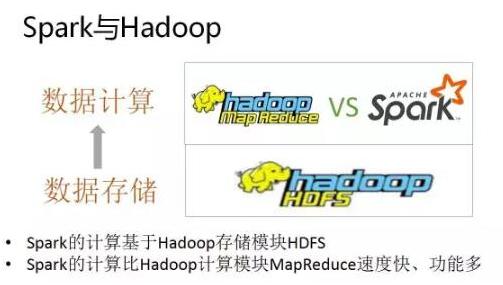
spark和hadoop比较
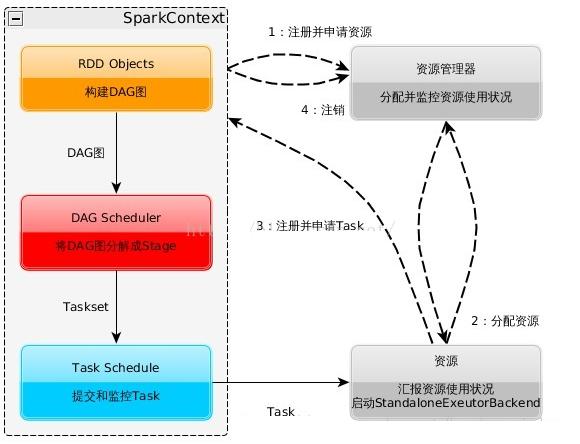
spark 原理
分析工作看起来简单,做起来很难,需要掌握的很多,路漫漫其修远兮,吾将上下而求索。
想进入这个行业的同学做好心里准备,加班多,待遇不一定好,等有了经验可能会好一些。