大数据文摘出品
来源:Github
编译:陆震、张秋玥、蒋宝尚
直到今天,在各类媒体口中,数据科学家依然是“21世纪最性感的职业”。但事实上,希望进入这个行业的初级数据科学家已经供过于求。
可以预见的是,各种高校相关专业的毕业生,在完成coursera或者fast.ai的课程后,都希望得到一份跟“数据”相关的岗位。据统计,部分职位的供求比已经达到了1:200。
那么,如何能在这条独木桥上杀出重围、脱引而出呢?
金三银四求职季,江湖传言在三月份和四月份找工作和跳槽成功的概率很大。不同于程序员这样的纯技术工种,求职成为一名数据科学家似乎需要“上知天文,下知地理”。
毕竟,数据科学领域集成了多种不同元素,包括信号处理,数学,概率模型技术和理论,机器学习,计算机编程,统计学,数据工程,模式识别和学习,可视化,不确定性建模,数据仓库,以及从数据中析取规律和产品的高性能计算。
今天文摘菌会给大家推荐一份数据科学面试资料,资料收集了来自技术公司的访调员和数据科学家。从浅入深的囊括了沟通、数据分析、模型预测、编程、概率、产品指标等7个部分的共120个面试问题。
根据官方网站,这份资源由Max、Carl、Henry以及William四位合作编写,他们都有数学科学以及数据分析的背景,也非常互补,也因此让这份资料变得弥足珍贵。
这份资料,在官方网站上需要付19美元可以获取完整版(包括问题和答案)。
先放上资料官网,非常需要的读者支持正版哦:
https://www.datasciencequestions.com/
当然,如果你只是想了解这份资料的大概内容,或者测试一下自己是否掌握了数据科学家需要的知识,文摘菌在github上也找到了这份资料的缩略问题版,少部分概念以及定义性的问题有答案,对于开放性的问题,欢迎大家在留言区给出你的答案哦。
文摘菌精选了这份资料中的部分问题和答案,完整版戳下边链接自取。
github地址:
https://github.com/kojino/120-Data-Science-Interview-Questions
沟通

(1) 向我解释一个与你正在面试的角色相关的技术概念。
(2) 向我介绍你所热爱的事情。
(3) 你会如何向没有统计背景的工程师解释A/B测试,线性回归呢?
A/B测试,也就是多变量测试,通过测试用户的不同体验,来确定哪种改变有助于企业更加有效地实现其目标(如增加转换等)。它可以是网站上的文本信息,按钮的颜色,不同的用户界面,不同的电子邮件主题行,号召性用语,优惠等。
(4) 你会如何向没有统计背景的工程师解释置信区间以及95%的置信度的意思?
参考链接:https://www.quora.com/What-is-a-confidence-interval-in-laymans-terms
(5) 你会如何向一组高级管理人员解释为什么数据很重要?
数据分析

(1) 给定一个数据集,分析这个数据集并告诉我你可以从中了解到什。
(2) 什么是R2?可能比R2更好的指标有哪些,为什么?
答:拟合良好,是由该回归/总方差解释的那部分方差;你添加的预测变量越多,R^2越大;因而使用因自由度调整的R ^ 2;或着训练误差指标。
(3) 什么是维度灾难?
- 高维度使得聚类变得困难,因为拥有大量维度意味着彼此相差很大。例如,为了覆盖一小部分数据,随着变量数量的增加,我们需要处理每个范围广泛的变量;
- 所有样本都靠近样本的边缘。这非常糟糕,因为在训练样本的边缘附近做出预测要更加困难;
- 随着维度 p的增加,采样密度呈指数下降,因此在没有更多的数据量的情况下,该数据会变得更加稀疏;我们应该进行PCA分析以降低维度。
(4) 更多的数据就总是更好么?
从统计来说,它取决于你的数据的质量,如果您的数据有偏差,获取再多数据也毫无用处;它取决于你的模型。如果你的模型能够承受高偏差,获取更多数据不会太过明显地提高你的测试结果。你需要添加更多特征,或者做别的处理。从实战来说,也需要在拥有更多数据和额外存储,计算能力以及所需内存之间进行权衡。因此,始终要考虑拥有更多数据的成本。
(5) 分析数据之前绘制图表有什么好处?
数据集会有错误。你不会找到全部的错误,但你或许能够找到其中的一些。比如那个212岁的男人以及那个9英尺高的女;变量会有偏度,异常值等。算术平均值可能用不了,这也意味着标准差用不了;变量可以是多峰的!如果变量是多峰的,那么任何基于其的均值或着中位数的都是可疑的。
模型预测(19个问题)
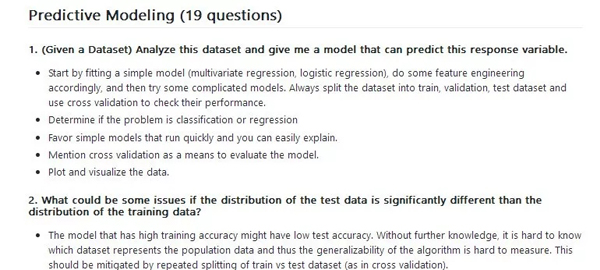
(1) 给定一个数据集,分析这个数据集并给出一个可以预测这个响应变量的模型。
由拟合简单的模型(多元回归,逻辑回归)开始,相应地选取一些特征,然后尝试一些复杂的模型。要始终将数据集拆分为训练集,验证集和测试集并使用交叉验证来观察模型的表现;确定问题是分类问题还是回归问题;倾向于选用运行快速可以轻松解释的简单模型;提及交叉验证作为评估模型的一种方法;绘制图表且将数据可视化。
(2) 如果测试数据的分布与训练数据的分布明显不同,可能会出现什么问题?
- 训练时具有高精度的模型在测试时可能具有较低的精度。在没有进一步了解的情况下,很难知道哪个数据集代表了总体的数据,因而很难测量算法的泛化程度;
- 这应该可以通过重复划分训练集和测试集来缓解(如交叉验证);
- 当数据分布发生变化时,称为数据集漂移。 如果训练数据和测试数据的分布不同,分类器可能会过度拟合训练数据。
(3) 有什么方法可以让我的模型对异常值的鲁棒性更高?
我们可以使用L1或L2等正则化方法来减少方差(增加偏倚)。
- 算法的改变:1.使用基于树的方法来代替回归方法,因为它们更能忍受异常值。2.对于统计检验,使用非参数检验来代替参数检验。3.使用稳健的误差指标,如MAE或Huber Loss,来代替MSE。
- 数据的改变:1.对数据进行winsorize处理2.转换数据(如进行对数处理)3.只有在你确定它们是不值得预测的异常值时才删除它们
(4) 与最小化误差绝对值的模型相比,在最小化误差平方的模型中,你认为有哪些差异?每个误差指标分别在哪种情况下合适?
MSE对异常值更加严格。在这个意义上MAE鲁棒性更好,但也更难以拟合模型,因为它无法在数值上进行优化。因此,当模型的可变性较小且在计算上容易拟合时,我们应该使用MAE,否则应该使用MSE。
- MSE:更容易计算梯度
- MAE:计算梯度需要线性编程MAE对异常值更加稳健。
如果较大错误造成的后果很严重,使用MSEMSE相当于最大化高斯随机变量的可能性。
(5) 你会什么误差指标来评估二分类器的好坏?如果类别不平衡怎么办?如果超过2组怎么办?
- 准确性:你正确预测的情况的比例。优点:直观,易于解释,缺点:当类标签不平衡且数据信号较弱时效果不。
- AUROC:在x轴上绘制fpr,在y轴上绘制tpr以获得不同的阈值。给定随机正例和随机负例,AUC是你能可以识别类别的概率。优点:在测试分类能力时效果很好,缺点:不能将预测解释为概率(因为AUC由排名决定),因此无法解释模型的不确定性。
- logloss/deviance:优点:基于概率的误差度量,缺点:对假阳性,假阴性非常敏感。当有超过2组时,我们可以使用k个二分类并将它们添加到logloss中。 像AUC这样的一些指标仅适用于二分类情况。
概率

(1) 阿米巴虫波波生0个、1个或2个小阿米巴虫的概率分别是25%、25%以及50%。这些小阿米巴虫们的繁殖能力也都一样。请问波波的后代灭绝的概率是多少?
- p=1/4+1/4p+1/2p^2 => p=1/2
(2) 任何15分钟时间段内,你看到至少一颗流星的概率是20%。请问在一小时内你看到至少一颗流星的概率是多少?
- l 1-(0.8)^4。 或者我们用泊松过程也可以解。
(3) 仅使用一枚色子,你如何生成一个1-7内随机数?
- 丢三次色子:每一次丢的都是结果的第n位
- 每次丢色子时,如果值为1-3,则记录0,否则记录1。结果会位于0(000)与7(111)之间,均匀分布(因为这三次抛掷互相独立)。如果得到0则重复抛掷:该过程会终止于均匀分布的值。
(4) 有一个数据集包含来自两个正态分布的数值。两个分布的标准差相同。来自两个分布的数据点个数相同。请问如果想要该数据集呈双峰分布,两个分布的均值应当至少差多少?
- 多于两个标准差
(5) 提供已知正态分布的样本值,请问你能如何模拟一个均匀分布的样本值?
- 将值代入同一随机变量的累计分布函数
(6) 一对夫妻告诉你他们有两个小孩,其中至少有一个是女孩。请问他们拥有两个女儿的概率是多少?
- 1/3
产品指标
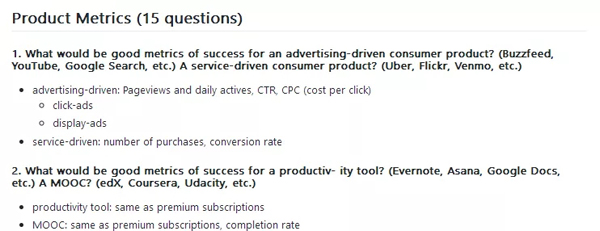
(1) 对于一个广告驱动的消费者产品(比如Buzzfeed,YouTube,Google搜索等),什么可以称为好的成功衡量指标?服务驱动的消费者产品(比如优步,Flickr,Venmo等)呢?
- 广告驱动:页面浏览量与每日活跃量,点击率,每次点击成本
- 服务驱动:购买量,转化率
(2) 对于一个效率工具(比如印象笔记,Asana,Google文档等),什么可以称为好的成功衡量指标?线上课程平台(比如edX,Coursera,Udacity等)呢?
- 效率工具:付费订阅用户数
- 线上课程平台:付费订阅用户数,课程完成率
(3) 对于一个电商产品(比如Etsy,Groupon,Birchbox等),什么可以称为好的成功衡量指标?订阅产品(比如Netflix,Birchbox,Hulu等)呢?高级付费订阅(比如OKCupid,领英,Spotify等)呢?
- 电商产品:购买量,转化率,时/日/周/月/季/年销售额,售出产品成本,存货量,网站流量,净回头客量,客服电话量,平均解决问题时长
- 订阅产品:流失量,(不知道接下来这几个都是啥)
- 高级付费订阅:(无解答)
(4) 对于高度依赖于用户投入与交互的消费者产品(比如Snapchat,Pinterest,Facebook等),什么可以称为好的成功衡量指标?通讯产品(比如GroupMe,Hangouts,Snapchat等)呢?
- 高度依赖于用户投入与交互的消费者产品:user AU ratios,分类型邮件汇总,分类型推送通知汇总,复活率。
- 通讯产品:(无解答)
(5) 对于拥有app内购服务的产品(比如Zynga,愤怒的小鸟以及许多其他游戏),什么可以称为好的成功衡量指标?
- 用户/付费用户平均营收
编程(14题)

(1) 编写一个函数,计算2n个用户所有可能分配向量,其中n个用户为控制组,n个用户为治疗组。
- 递归编程
(2) 提供一个包含Twitter消息的列表,求十个最常用的的标签。
- 在字典中存储所有标签然后求前十值
(3) 在给定时间内写出算法求解背包问题的理想近似解。
- 贪婪算法
(4) 在给定时间内写出算法求解旅行商问题的理想近似解。
- 贪婪算法
(5) 你将得到一个大小为n的数据集,但你无法提前知道n具体有多大。写出一个占据O(k)的算法来随机抽取k个元素。
- 水塘抽样
统计推论(15题)
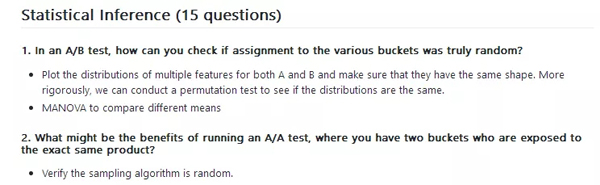
(1) AB测试中你如何确认客户流分组完全随机?
- 画出多个A组与B组变量的分布,确保他们都拥有一致的形状。再保险一点,我们可以做一个排列检验来看分布是否相同。
- MANOVA来比较不同的均值。
(2) AA测试(两组完全一致)的好处有什么?
- 检查抽样算法随机性
(3) 在AB测试中,允许一组用户知道另一组是什么样子有什么危害?
- 用户可能无法与未知其他选项时行为一致。实际上你是在添加一个关于是否允许用户窥探其它选项的变量——该变量并不随机。
(4) 如果某个博客报道了你的实验组会有什么影响呢?
- 与前问相同。这一问题可能会在更大范围内发生。
(5) 你如何设计一个允许用户自行选择是否加入的AB测试。
github地址:https://github.com/kojino/120-Data-Science-Interview-Questions
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】