一、引子:Redis client library 连接 Redis server 超时
差不多一两年前,在阿里云上遇到一个奇怪的 Redis 连接问题,每隔十来分钟,服务里的 Redis client 库就报告连接 Redis server 超时,当时花了很大功夫,发现是阿里云会断开长时间闲置的 TCP 连接,不给两头发 FIN or RST 包。当时我们的 Redis server 没有打开 tcp_keepalive 选项, Redis server 侧那个连接还存在于 Linux conntrack table 里,而 Redis client 侧由于连接池重用连接进行 get、set 发现连接坏掉就关闭了,所以 client 侧的对应 local port 回收了。
当接下来 Redis 重用这个 local port 向 Redis server 发起连接时,由于 Redis server 侧的 conntrack table 里四元组对应状态是 ESTABLISHED,所以自然客户端发来的 TCP SYN packet 被丢弃,Redis client 看到的现象就是连接超时。
解决这个问题很简单,打开 Redis server 的 tcp_keepalive 选项就行。 然而当时没想到这个问题深层次的原因影响很重大,后果很严重!
二、孽债:”SELECT 1” 触发的 jdbc4.CommunicationsException
最近生产环境的 Java 服务几乎每分钟都报告类似下面这种错误:
- [main] ERROR jdbc.audit - 2. Statement.execute(select 1) select 1
- com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
- The last packet successfully received from the server was 576,539 milliseconds ago. The last packet sent successfully to the server was 5 milliseconds ago.
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
- at com.mysql.jdbc.Util.handleNewInstance(Util.java:425)
- at com.mysql.jdbc.SQLError.createCommunicationsException(SQLError.java:990)
- at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3559)
- at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3459)
- at com.mysql.jdbc.MysqlIO.checkErrorPacket(MysqlIO.java:3900)
- at com.mysql.jdbc.MysqlIO.sendCommand(MysqlIO.java:2527)
- at com.mysql.jdbc.MysqlIO.sqlQueryDirect(MysqlIO.java:2680)
- at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2480)
- at com.mysql.jdbc.ConnectionImpl.execSQL(ConnectionImpl.java:2438)
- at com.mysql.jdbc.StatementImpl.executeInternal(StatementImpl.java:845)
- at com.mysql.jdbc.StatementImpl.execute(StatementImpl.java:745)
- at net.sf.log4jdbc.StatementSpy.execute(StatementSpy.java:842)
- at com.zaxxer.hikari.pool.PoolBase.isConnectionAlive(PoolBase.java:158)
- at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:172)
- at com.zaxxer.hikari.pool.HikariPool.getConnection(HikariPool.java:148)
- at com.zaxxer.hikari.HikariDataSource.getConnection(HikariDataSource.java:100)
- at cn.yingmi.hikari.Main.main(Main.java:30)
- Caused by: java.io.EOFException: Can not read response from server. Expected to read 4 bytes, read 0 bytes before connection was unexpectedly lost.
- at com.mysql.jdbc.MysqlIO.readFully(MysqlIO.java:3011)
- at com.mysql.jdbc.MysqlIO.reuseAndReadPacket(MysqlIO.java:3469)
- ... 14 more
由于有之前调查 Redis 连接被阿里云异常中断的先例,所以怀疑是类似问题,花了大量时间比对客户端和服务端的 conntrack table,然而并没有引子中描述的问题。
后来又去比对多个 MySQL 服务器的 sysctl 设置,研究 iptables TRACE,研究 tcpdump 抓到的报文,试验 tw_reuse, tw_recyle 等参数,调整 Aliyun 负载均衡器后面挂载的 MySQL 服务器个数,都没效果。
反而意外发现一个新问题,在用如下命令不经过阿里云 SLB 直接连接数据库时,有的数据库可以在 600s 时返回,有的则客户端一直挂着,半个多小时了都退不出来,按 ctrl-c 中断都不行。
- mysql -h mysql-server-ip -u mysql-user -p -e 'SELECT sleep(1000)'
当时检查了一个正常的数据库和一个不正常的数据库,发现两者的 wait_timeout 和 interactive_timeout 都是 600s,思索良苦,没明白怎么回事,然后偶然发现另外一个数据库的 wait_timeout=60s,却一下子明白了原始的 “select 1” 问题怎么回事。
我们的服务使用了 Hikari JDBC 连接池,它的 idleTimeout 默认是 600s, maxLifetime 默认是 1800s,前者表示 idle JDBC connection 数量超过 minimumIdle 数目并且闲置时间超过 idleTimeout 则关闭此 idle connection,后者表示连接池里的 connection 其生存时间不能超过 maxLifetime,到点了会被关掉。
在发现 “select 1” 问题后,我们以为是这俩参数比数据库的 wait_timeout=600s 大的缘故,所以把这两个参数缩小了,idleTimeout=570s, maxLifetime=585s,并且设置了 minimumIdle=5。
但这两个时间设置依然大于其中一个数据库失误设置的 wait_timeout=60s,所以闲置连接在 60s 后被 MySQL server 主动关闭,而 JDBC 并没有什么事件触发回调机制去关闭 JDBC connection,时间上也不够 Hikari 触发 idleTimeout 和 maxLifetime 清理逻辑,所以 Hikari 拿着这个“已经关闭”的连接,发了 “select 1” SQL 给服务器检查连接有效性,于是触发了上面的异常。
解决办法很简单,把那个错误配置的数据库里 wait_timeout 从 60s 修正成 600s 就行了。
下面继续讲述 “SELECT sleep(1000)” 会挂住退不出来的问题。
三、缘起:阿里云安全组与 TCP KeepAlive
最近看了一点佛教常识,对”诸法由因缘而起“的缘起论很是感慨,在调查 “SELECT sleep(1000)” 问题中,真实感受到了“由因缘而起” 的意思😄
首先解释下,为什么有的数据库服务器对 “SELECT sleep(1000)” 可以返回,有的却挂着退不出来。 其实 wait_timeout 和 interactive_timeout 两个参数只对 “闲置” 的数据库连接,也即没有 SQL 正在执行的连接生效,对于 “SELECT sleep(1000)”,这是有一个正在执行的 SQL,其***执行时间受 MySQL Server 的 max_execution_time 限制,这个参数在我司一般设置为 600s,这就是 “正常的数据库” 在 600s 时 “SELECT sleep(1000)” 中断执行而退出了。
但不走运的是(可以说又是个失误配置😓),我们有的数据库 max_execution_time 是 6000s,所以 “SELECT sleep(1000)” 在 MySQL server 服务端会在 1000s 时正常执行结束——但问题是,通过二分查找以及 tcpdump、iptables TRACE,发现阿里云会”静默“丢弃 >=910s idle TCP connection,不给客户端、服务端发送 FIN or RST 以强行断掉连接。
于是 MySQL server 在 1000s 结束时发给客户端的 ACK+PSH TCP packet 到达不了客户端,然后再过 wait_timeout=600s,MySQL server 就断开了这个闲置连接——可怜的是,mysql client 这个命令行程序还一无所知,它很执着的等待 MySQL server 返回,Linux 内核的 conntrack table 显示这个连接一直是 ESTABLISHED,哪怕 MySQL server 端已经关闭对应的连接了,只是这个关闭动作的 FIN TCP packet 到不了客户端!
下面是 iptables TRACE 日志对这个问题的实锤证明。
mysql 命令行所在机器的 iptables TRACE 日志表明,mysql client 在 23:58:25 连接上了 mysql server,开始执行 SELECT sleep(1000),然后一直收不到服务器消息,***在 00:41:20 的时候我手动 kill 了 mysql 客户端命令行进程,mysql 客户端给 mysql server 发 FIN 包但收不到响应(此时 mysql server 端早关闭连接了)。
- Dec 14 23:58:25 client-host kernel: [3156060.500323] TRACE: raw:OUTPUT:policy:3 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=43069 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961697 ACK=0 WINDOW=29200 RES=0x00 SYN URGP=0 OPT (020405B40402080A2F06075C0000000001030307) UID=0 GID=0
- Dec 14 23:58:25 client-host kernel: [3156060.500334] TRACE: nat:OUTPUT:rule:1 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=43069 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961697 ACK=0 WINDOW=29200 RES=0x00 SYN URGP=0 OPT (020405B40402080A2F06075C0000000001030307) UID=0 GID=0
- Dec 14 23:58:25 client-host kernel: [3156060.500419] TRACE: nat:KUBE-SERVICES:return:86 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=43069 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961697 ACK=0 WINDOW=29200 RES=0x00 SYN URGP=0 OPT (020405B40402080A2F06075C0000000001030307) UID=0 GID=0
- ....
- Dec 14 23:58:25 client-host kernel: [3156060.539844] TRACE: filter:KUBE-FIREWALL:return:2 IN=eth0 OUT= MAC=00:16:3e:12:09:f0:44:6a:2e:94:ef:00:08:00 SRC=10.31.76.36 DST=10.66.94.67 LEN=52 TOS=0x00 PREC=0x00 TTL=61 ID=9283 DF PROTO=TCP SPT=3306 DPT=38870 SEQ=2025462702 ACK=2419961951 WINDOW=235 RES=0x00 ACK URGP=0 OPT (0101080AFF6B3EAF2F06075D) UID=0 GID=0
- Dec 14 23:58:25 client-host kernel: [3156060.539849] TRACE: filter:INPUT:policy:3 IN=eth0 OUT= MAC=00:16:3e:12:09:f0:44:6a:2e:94:ef:00:08:00 SRC=10.31.76.36 DST=10.66.94.67 LEN=52 TOS=0x00 PREC=0x00 TTL=61 ID=9283 DF PROTO=TCP SPT=3306 DPT=38870 SEQ=2025462702 ACK=2419961951 WINDOW=235 RES=0x00 ACK URGP=0 OPT (0101080AFF6B3EAF2F06075D) UID=0 GID=0
- Dec 15 00:41:20 client-host kernel: [3158634.985792] TRACE: raw:OUTPUT:policy:3 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=52 TOS=0x00 PREC=0x00 TTL=64 ID=43075 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961951 ACK=2025462702 WINDOW=237 RES=0x00 ACK FIN URGP=0 OPT (0101080A2F0FD975FF6B3EAF) UID=0 GID=0
- Dec 15 00:41:20 client-host kernel: [3158634.985805] TRACE: filter:OUTPUT:rule:1 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=52 TOS=0x00 PREC=0x00 TTL=64 ID=43075 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961951 ACK=2025462702 WINDOW=237 RES=0x00 ACK FIN URGP=0 OPT (0101080A2F0FD975FF6B3EAF) UID=0 GID=0
- Dec 15 00:41:20 client-host kernel: [3158634.985812] TRACE: filter:KUBE-SERVICES:return:5 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=52 TOS=0x00 PREC=0x00 TTL=64 ID=43075 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961951 ACK=2025462702 WINDOW=237 RES=0x00 ACK FIN URGP=0 OPT (0101080A2F0FD975FF6B3EAF) UID=0 GID=0
- ....
- Dec 15 00:42:13 client-host kernel: [3158688.341777] TRACE: filter:KUBE-FIREWALL:return:2 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=52 TOS=0x00 PREC=0x00 TTL=64 ID=43084 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961951 ACK=2025462702 WINDOW=237 RES=0x00 ACK FIN URGP=0 OPT (0101080A2F100D90FF6B3EAF)
- Dec 15 00:42:13 client-host kernel: [3158688.341782] TRACE: filter:OUTPUT:policy:3 IN= OUT=eth0 SRC=10.66.94.67 DST=10.31.76.36 LEN=52 TOS=0x00 PREC=0x00 TTL=64 ID=43084 DF PROTO=TCP SPT=38870 DPT=3306 SEQ=2419961951 ACK=2025462702 WINDOW=237 RES=0x00 ACK FIN URGP=0 OPT (0101080A2F100D90FF6B3EAF)
Ok,现在知道是阿里云对 >= 910s 没有发生 TCP packet 传输的虚拟机之间直连闲置 TCP 连接会“静默”丢包,那么是任意虚拟机之间吗?是任意端口吗?要求服务器挂到负载均衡器后面吗?要求对应端口的并发连接到一定数目吗?
在阿里云提交工单询问后,没得到什么有价值信息,在经过艰苦卓绝的试验后——每一次试验要等近二十分钟啊——终于功夫不负有心人,我发现一个稳定复现问题的规律了:
- 两台虚拟机分别处于不同安全组,没有共同安全组;
- 服务端的安全组开放端口 P 允许客户端的安全组连接,客户端不开放端口给服务端(按照一般有状态防火墙的配置规则,都是只开服务端端口,不用开客户端端口);
- 客户端和服务端连接上后,闲置 >= 910s,不传输任何数据,也不传输有 keep alive 用途的 ack 包;
- 然后服务端在此长连接上发给客户端的 TCP 包会在网络上丢弃,到不了客户端;
- 但如果客户端此时给服务端发点数据,那么会重新“激活”这条长链接,但此时还是单工状态,客户端能给服务端发包,服务端的包还到不了客户端(大概是在服务端 OS 内核里重试中);
- 激活后,服务端再给客户端发数据时,之前发送不出去的数据(如果还在内核里的 TCP/IP 协议栈重试中),加上新发的数据,会一起到达客户端,此后这条长连接进入正常的双工工作状态;
下图是用 nc 试验的结果。
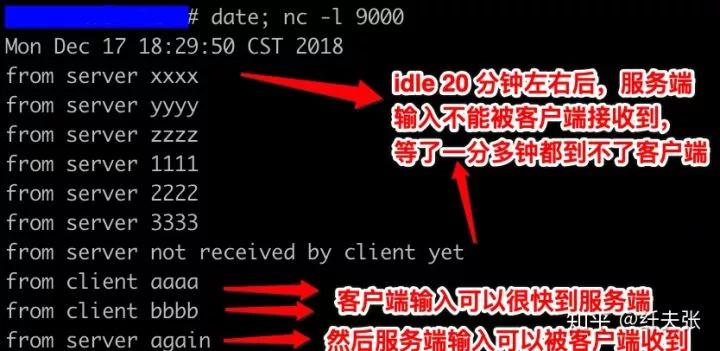
服务端

客户端
在跟网友讨论后,认识到这应该是阿里云安全组基于“集中式防火墙”实现导致的,因为集中式防火墙处于网络中心枢纽,它要应付海量连接,因此其内存里的 conntrack table 需要比较短的 idle timeout(目前是 910s),以把长时间没活跃的 conntrack record 清理掉节约内存,所以上面问题的根源就清晰了:
client 连接 server,安全组(其实是防火墙)发现规则允许,于是加入一个记录到 conntrack table;
client 和 server 到了 910s 还没数据往来,所以安全组把 conntrack 里那条记录去掉了;
server 在 910s 之后给 client 发数据,数据包到了安全组那里,它一看 conntrack table 里没记录,而 client 侧安全组又不允许这个端口的包通过,所以丢包了,于是 server -> client 不通;
client 在同一个长连接上给 server 发点数据,安全组一看规则允许,于是加入 conntrack table 里;
server 重试的数据包,或者新数据包,通过安全组时,由于已经有 conntrack record 了,所以放行,于是能到达客户端了。
原因知道了,怎么绕过这个问题呢?阿里云给了我两个无法接受的 workaround:
把 server、client 放进同一个安全组;
修改 client 所在安全组,开放所有端口给 server 所在安全组;
再琢磨下,通过 netstat -o 发现我们的 Java 服务使用的 Jedis 库和 mysql JDBC 库都对 socket 文件句柄打开了 SO_KEEPALIVE 选项:

而 MySQL server 也对其打开的 socket 文件句柄打开了 SO_KEEPALIVE 选项,所以我只用修改下服务端和客户端至少其中一侧的对应 sysctl 选项即可,下面是我司服务端的默认配置,表示 TCP 连接闲置 1800s 后,每隔 30s 给对方发一个 ACK 包,最多发 3 次,如果在此期间对方回复了,则计时器重置,再等 1800s 闲置条件,如果发了 3 次后对方没反应,那么会给对端发 RST 包同时关闭本地的 socket 文件句柄,也即关闭这条长连接。
- net.ipv4.tcp_keepalive_intvl = 30
- net.ipv4.tcp_keepalive_probes = 3
- net.ipv4.tcp_keepalive_time = 1800
由于阿里云跨安全组的 910s idle timeout 限制,所以需要把 net.ipv4.tcp_keepalive_time 设置成小于 910s,比如 300s。
默认的 tcp_keepalive_time 特别大,这也解释了为什么当初 Redis client 设置了 SO_KEEPALIVE 选项后还是被阿里云静默断开。
如果某些网络库封装之后没有提供 setsockopt() 调用的机会,那么需要用 LD_PRELOAD 之类的黑科技强行设置了,只有打开了 socket 文件句柄的 SO_KEEPALIVE 选项,上面三个 sysctl 才对这个 socket 文件句柄生效,当然,代码里可以用 setsockopt() 函数进一步设置 keep_alive_intvl 和 keepalive_probes,不用 Linux 内核的全局默认设置。
***,除了 Java 家对 SO_KEEPALIVE 处理的很好,利用 netstat -o 检查得知,对门的 NodeJS 家,其著名 Redis client library 开了 SO_KEEPALIVE 但其著名 mysql client library 并没有开,而 Go lang 家则严谨多了,两个库都开了 SO_KEEPALIVE。
为什么引子里说这个问题很严重呢?因为但凡服务端处理的慢点,比如 OLAP 场景,不经过阿里云 SLB 直连服务端在 910s 之内没返回数据的话,就有可能没机会返回数据给客户端了啊,这个问题查死人有没有! 你可能问我为啥不通过阿里云 SLB 中转,SLB 不会静默丢包啊——但它的 idle timeout 上限是 900s 啊!!!