大数据文摘出品
来源:veekaybee
编译:刘佳玮、Stats熊、蔡婕、张弛、Aileen
数据科学刚刚度过了它的黄金五年。
自2012年以来,这个行业发展迅速。它几乎完整经历了Gartner技术成熟度曲线的每个阶段。

度过了初期使用阶段、有关AI和偏见的负面新闻、Facebook等公司的第二三轮风投。现在的数据科学正处于高增长使用阶段:即使是银行、医疗保健公司和落后市场五年的其他100强企业,也在招聘机器学习中的数据科学岗位。
但现实正在发生巨大的变化。
来自captech基金的资深数据科学家Vicki Boykis发布了一篇《数据科学不一样了》的文章,引起了广泛讨论。五年前被誉为“最性感“职业的数据科学家,正在进入一个新的阶段。
我们该如何应对?一起看看。
大数据(还记得Hadoop和Pig吗?)已经出局,R语言的采用率急剧上升,Python在《经济学人》杂志中被表扬多次,“云”已经再次改变了一切。
不幸的是,大众媒体在数据科学领域的炒作始终没有改变。
直到今天,在各类不负责任的媒体口中,数据科学家依然是“21世纪很性感和很容易找工作的职业”。而事实上,希望进入这个行业的初级数据科学家已经供过于求,他们一旦获得梦寐的“数据科学家”称号后,实际展现出来的能力并不能达到预期的那样。
新数据科学家的供过于求
首先,我们来谈谈初级数据科学家的供过于求。
围绕数据科学的持续媒体炒作极大地提高了过去五年市场上的初级人才数量。
这纯粹是传闻,你大可不必相信。但是,基于我参与筛选简历、做刚入门的数据科学家的导师、做采访者和受访者以及与处于类似职位的朋友和同事们的对话的经历,可以初步感受到,每个数据科学职位而言,特别是入门级的职位,候选人都已经从20个增加到100个或更多。
我最近和一个朋友谈话,他的一个开放职位收到了500份简历。
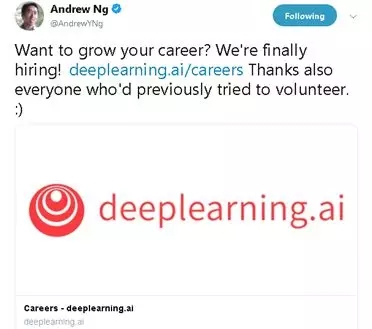
这并不奇怪。更多的传闻是来自像机器学习教父吴恩达的职位空缺,他的AI创业公司每周要求70-80小时的工作时间。
即便如此,他依然收到了很多人试图免费为他志愿工作。截止到目前,据他所说,他的办公室已经全部坐满。
正确估计市场供需当然不容易,但Wired的一篇文章可以提供一些线索:
| 对2018年4月份招聘广告的研究发现,美国有超过10000个职位空缺,面向有人工智能或机器学习技能的人。 |
文章继续表明:
| 超过10万人开始学习Fast.ai提供的深度学习课程,Fast.ai是一家专注于扩大人工智能应用的创业公司。 |
让我们做一道简单的数学题。
假设MOOC(慕课)的平均完成率约为7%,那意味着,这一年会有7000人可以填补这10000个工作岗位。这一年如此,但明年又如何呢?我们是否假设数据科学的就业率稳定?如果是这样,数据科学的就业市场看起来就会缩小很多。
我们再来看一项更广泛的研究,LinkedIn表示市场上缺少151,717个具有数据科学技能的人才。虽然目前还不清楚这是指数据科学家还是仅具有部分技能的人,但我们假设是前者。那样的话,该国数据科学家有150000个职位空缺。
鉴于有100000人已经开始了数据科学课程,我们假设其中有7000人能完成课程。
但是,这些数字还都没有考虑到所有创造新的数据科学候选人的计划和途径:有像Coursera这样的Fast.ai之外的MOOC,有超过10个像Metis和GA(General Assembly)这样的每季度25人参加的全国性训练营,还有像加州大学洛杉矶分校等地的远程学位——分析和数据科学的学士学位,YouTube等,还有大量无法在极其紧张的就业市场找到工作、正从学术界转向数据科学的博士们。
这里有第三个确凿证据,来自PWC,它指出2015年数据科学家有4万个职位空缺。它还从总体上估计,认为分析技能的市场供应(再次说明,它比数据科学范围更大,但也是一个比较点)到2018年将会使市场过度拥挤。

将此与数百个数据科学课程的训练营相结合,如果有人要进入某个行业,你将看到一场大风暴。
根据我在业内工作并与100多名同事交谈的直觉,这两条Twitter最终使我确信数据科学行业存在供应泡沫。
首先,是这个有关入门数据科学课程的Twitter:

Cal的入门数据科学课程是Data 8,这门课很受欢迎,位于泽勒巴赫教室。。
和UVA开设数据科学学院的消息:
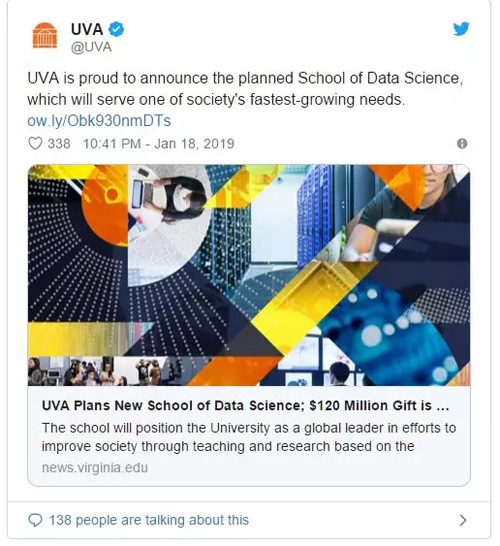
UVA很自豪地宣布计划中的数据科学学院成立,它将满足社会增长最快的需求之一
由于在适应工业界的新趋势上,学术界通常是滞后的,因此这个趋势真的该引起初级数据科学家们的重视,所有人都希望找一个数据科学的职位。考虑到他们在市场上的竞争者数量,刚获得数据科学学位的人很难找到真的入行。
在三、四年前情况还并非如此,然而现在数据科学已经从一个流行词汇转变为硅谷泡沫外更大的公司招聘的职位,相关的职位不仅更加正式化,而且有着更严格的准入要求(即倾向于曾经具备数据科学工作经验的人)。数据科学职位的面试仍然难以把握,并且与工作完全不匹配。
正如许多博客文章指出的那样,你未必在初次尝试时就能找到理想工作。 因此,就业市场相当艰难,对于大量入门者来说更加困难重重。
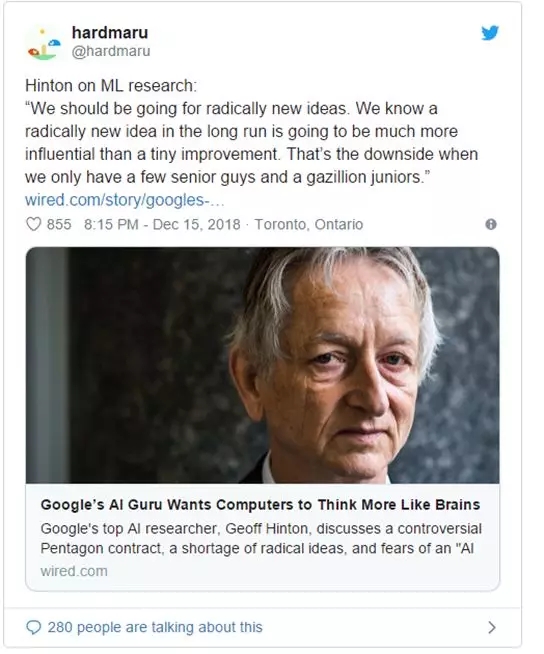
Hinton对于机器学习领域现状的想法:
| “我们应该采取全新的想法。我们都知道从长远来看,一个全新的想法将比一个个微小的改进更有效。当我们这个群体只有一些资深人士和一大批青少年时,这就是缺点。” |
数据科学存在有误导性的工作需求
第二个问题是,一旦这些初学者进入市场,他们会对数据科学的工作模式产生不切实际的期望。每个人都认为他们将进行机器学习、深度学习和贝叶斯模拟。
这并不是他们的错,这正是一些数据科学课程和技术媒体们一直以来强调的内容。自从很久之前我过分乐观地浏览Hacker News 上逻辑回归的帖子以来,情况并没有发生多大变化。
现实情况是,“数据科学”从未像机器学习那样关注数据清洗,数据转换以及将数据从一个地方移动到另一个地方。
我最近进行的极其非科学的调查问卷证实了这一点:
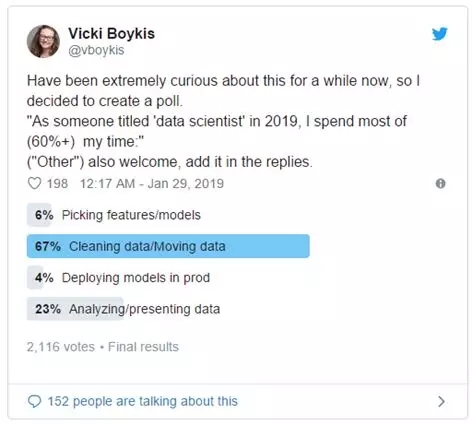
作者2019年1月在Twitter上做的调查温暖:
| 近一段时间以来对此非常好奇,所以我决定创建一个调查问卷:
“作为2019年被称为'数据科学家'的人,我花了大部分时间在(60%以上):” 选择了(“其他”)也欢迎在回复中添加。 调查结果:
|
许多行业专家发送的推文也是如此:

| “在我最近的几个机器学习项目中,复杂的地方不再是建模或培训里;二是在在输入预处理中。我发现自己耗尽的是CPU而不是GPU,并且在一个项目中我真的不确定如何进一步优化python(我也正在考虑c ++)。”
— mat kelcey “我在初级ML/ CV工程师身上看到的最失败的一面是对构建数据集完全缺乏兴趣。虽然这是一项无聊的工作,但我认为在整理数据集时能够学习到很多东西。这就像是问题的一半。“ — Katherine Scott |
伴随着数据清洗,当炒作周期继续发挥着它的效应时,更加清晰的是,数据工具和将模型投入生产变得比在一台机器上从头开始构建ML算法更加重要,特别是随着云资源可用性的爆炸式增长。
显而易见的是,在炒作周期的后期阶段,数据科学将逐渐接近工程学,而数据科学家需要的技能不再主要基于可视化和统计学,而是更符合传统的计算机科学课程:像单元测试和持续集成这样的概念,很快就成了术语,并被用作数据科学家和从事ML工程的数值科学家常用的工具集。
这也导致了几件事的发生:首先是“机器学习工程师”这个头衔的崛起,在过去的3-4年里,它带来了更多的声望和更高的收入潜力。
其次,它导致了数据科学家职称的严重缩水。由于数据科学家职称的声望,像Lyft这样的公司会招聘这类职位,但要求拥有数据分析师的技能,这就造成了别扭的情况——数据科学的职位究竟需要做什么,又有多少职位提供给新入职的工作者。
我们作为资深从业者、记者、经理、行业会议发言人、撰写工作要求的人力资源经理,仍然不能很好地解决这个重要的难题。
给新数据科学家的建议
因此,本着继续为初学者提供建议的精神,我将给任何在2019年向我咨询如何进入数据科学领域的人发送这封邮件。
这是一个两步计划:
- 不要一味追求数据科学的工作
- 为成为数据科学家做好准备,而不是单单为了数据科学。调整你的技能组合。
这些听起来真是令人沮丧!但是,让我来详细说明这两个问题,希望它们看起来不那么黯淡。
1. 谨慎选择数据科学
鉴于每个初级岗位有50或100或200个人投简历,因此不要与那些人竞争。不必攻读数据科学学位,不必参加训练营(边注:我见过的大多数训练营都是效率低下的,他们在很短的时间内让求职者处理太多的信息,使得求职者无法有效地对数据科学有所了解,在这里我就不细说了)。
不要做别人正在做的事情,因为这样不能使你脱颖而出。你是在和一个堆积如山、过度饱和的行业竞争,这只会让事情变得更困难。在我之前提到的那份PWC报告中,数据科学职位的数量估计为5万。数据工程职位的数量为50万。而数据分析师的数量是12.5万。
通过“后门”进入数据科学和技术的职位要容易得多,比如从做初级开发人员开始,或者从DevOps、项目管理开始,以及从事最相关的数据分析师、信息管理员等类似职位,而不是直接申请其他人也同时竞争的5个岗位。这将花费更长的时间,但是在你从事数据科学工作的同时,也在学习对你的整个职业生涯至关重要的IT技能。
2. 了解当今数据科学所需的技能
下面是一些你在数据空间中实际需要处理的问题:
- 创建Python包
- 将R语句投入实际生产
- 优化Spark工作,使其更有效地运行
- 版本控制数据
- 使模型和数据可复制
- 版本控制SQL
- 在数据湖中建立和维护干净的数据
- 大规模时间序列预测工具
- 扩展Jupyter笔记本的共享
- 考虑清洗数据的系统
- 大量的JSON
虽然在数据科学中有许多有趣的统计问题需要考虑,但这些博客链接都没有解决它们。尽管调整模型、可视化和分析占据了你作为数据科学家的部分时间,但数据科学一直主要的工作是如何得到可以直接使用的干净数据。
所有这些博客文章有什么共同之处?那就是良好的数据背景下的各个工程技能。
你该如何准备解决这些问题,并为工作做好准备?学习以下三种技能,它们都是基础技能,并且相互之间有关联,从入门到精通。
所有这些技能的真正关键之处在于,它们对于数据科学之外的软件开发也是基础和重要的,这意味着如果你找不到数据科学相关的工作,也可以快速地过渡到软件开发或devops。我认为这种灵活性与针对特定数据相关任务的培训同样重要。
(1) 学习SQL
首先,我建议无论目标是成为数据工程师、ML专家还是AI 专家,每个人都需要学习SQL。
SQL并不吸引人,它也不是我刚才列出的问题的解决方案。但实际上,为了理解如何访问数据,你极有可能在某个地方遇到需要编写一些SQL查询并获得答案的数据库。
SQL非常强大且受欢迎,以至于NoSQL和键值存储解决方案也在复现它。只需查看Presto、Athena,它们由Presto、BigQuery、KSQL、Pandas和Spark等等提供支持。如果你发现自己被大量的数据工具所淹没,那么很可能有SQL是适合你的。而且,一旦你理解了SQL范式,就能更容易理解其他查询语言,从而开辟一个全新的领域。
在学好SQL之后,下一步是了解数据库如何工作以及为什这样就可以学习优化查询。你不会成为数据库开发人员,但是许多概念将延续到你的其他编程生活中。
(2) 学好编程语言、学习编程概念
前文我们谈论过如何学习SQL的问题,当你使用SQL的时候,你会有这样一个疑问,这样的数据库处理软件,它是不是一个编程语言呢?答案是肯定的,不过它属于声明式编程。你可以指定所需要的输出(就是你想从数据表中把哪几列提取出来),但没法控制它用什么方式把结果反馈。SQL抽象出大量发生在数据库内的信息。
与之相对的,如果你需要一种可以指定数据从哪里、用什么方式被选取出来。像Java、Python、Scala、R、Go等等这些都是现在流行的面向对象的过程化语言。
大家现在对用哪种语言去做数据科学依旧有很多争论,当然也不会在这里指定一种语言是最合适的。但我想说的是,在我的日常工作中,Python对我的帮助真的很大。作为一个初学者来说,Python很容易上手,而且也是数据领域里很流行的编程语言。为什么这么说呢,因为它可以处理很多数据问题,如构建一个模型放入到scikitlearn里、访问AWS API云平台服务接口、制作网页服务应用、清洗数据、创建深度学习模型等等。而在统计领域里,R还是更为广泛使用。
但同样的,我还是建议不用去深究统计领域,Python基本可以满足编程需求了。
当然Python在大规模应用、打包依赖关系、一些特定数字处理、特别是时间序列和R那样开包即用(Python不像R有很多成型的功能包、更细致的统计功能模型) 等等问题上也不是很适用。
如果你不选择Python,那也没什么问题。但你应该选择一门语言让你在数据科学之外的领域,一样可以大展拳脚。
如果说一旦你选择掌握某种编程语言,就会开始学习它的范式,研究它与整个计算机生态系统的关系。
在开始研究之后,你就会面对这样一系列问题。如何用你掌握的编程语言进行面向对象编程(OOP)?什么是面向对象编程?如何让你的代码更简化?你使用的语言是通过什么样依赖关系工作的?对你写好的代码如何打包,怎样进行版本控制、持续集成、模型部署?到哪里去找这种语言社区去交流学习,他们什么时候进行交流研讨会?
然后你需要做的就是不断地了解这门语言,知道它的优缺点,然后用这门语言做些有趣的编程,找到其中的乐趣。
然后就像武侠小说里练就奇功一样,当你打通任通二脉,这种编程语言能力成为你身体的一部分,然后你就去学习第二种编程语言,它将会教给你更多关于语言设计、算法和模式的内容,了解这个更丰富有趣的语言世界。
(3) 学会如何在云平台进行操作
现在你知道如何进行编程,那下一步要做的就是把这些能力和理论推广到云平台上,跟其他编程者进行共享。
现在云服务无处不在,很有可能你的下一份工作就是需要在云平台上完成的。有了云技术,如果能够抢先一步,就越容易走到前列,就比如现在有越来越多的机器学习范例转移到了云服务供应商(如亚马逊的SageMaker、谷歌的Cloud AI、微软的Azure Machine Learning),那上面会有更多现成的模板来实现你想要的算法、也有更多的公司数据会存储在云上。
当然你也有机会跟AWS合作,但越来越多的地方开始使用Google Cloud云服务,还有一些较为保守的传统企业也开始用Microsoft Azure云服务。我的建议是对这上文提到的三家云服务公司做一个用户调查,然后选择一个更适合你们的。云设计范式是通用的,所以你应该更关心如何将服务连接在一起、如何将你使用的部分与云上其他应用做逻辑隔离,以及如何解析处理大量的JSON。
一个很酷的事情是,现在三家云服务供应商都开始提供他们的产品认证。我通常不太相信认证是知识获取的标志,但是你可以通过认证学到云平台很重要的工作原理,这也是工程里另一个组成部分——网络。
所以在你找到下一份工作之前,可以有时间充分学习一下这三家的证书,并且在云平台上自由发挥一下,也是不错的选择。
还有一大部分我们没有讲到,就是“软技能”(知道如何构建、知道如何在工作环境下交流、知道其他人的需求)。这种能力与技术能力同样重要,也有很多博客专门提到这种能力。
(4) 结尾一步
现在深呼吸,我知道你已经做好准备了。
如果说上面说的内容已经足够打动你,说明在2019年,你已经做好成为一名数据科学家、或机器学习工程师、或云专家、AI法师的准备了。
请记住,遵循这些建议的最终目标是打败那些具有数据科学学位、通过训练营和通过教程的工作人员。
你想进入这个行业,得到一个数据相关职位,朝你期待的工作而努力,并且尽可能多的了解整个科技行业的发展。
我还有一点诚恳建议和鼓励是:这些东西对任何一个人来说都相当困难,而且看起来你需要了解成百上千的事情,永远不要失去信心。(不忘初心)
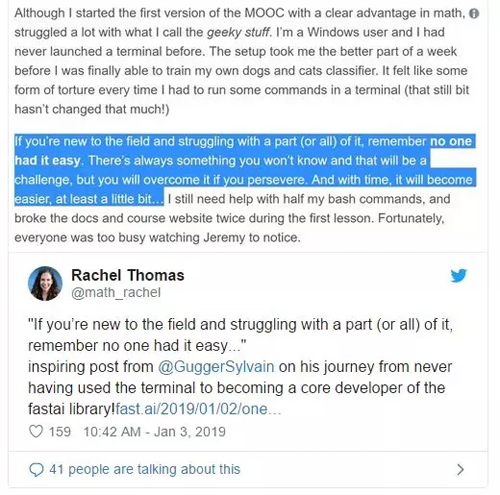
就像上面这个博客里,这个作者学习MOOC一开始都是幺蛾子,每个都是新东西,而且并没有接触过除了Windows以外其他操作系统,也没有接触过终端,但是经过努力终于做出了自己想要的分类器。
所以她也说到,在这个领域对于每个人来说都不容易,任何事情都是挑战,但是最终你都会克服并且一点点解决掉,你会发现车到山前必有路,柳暗花明又一村。
不要被分析问题的困难所击倒。从一个小问题入手,积跬步以至千里,最终问题会迎刃而解。
我最喜欢的其中一本书是安妮.拉莫特的《Bird By Bird》,是一本关于写作的书。很有趣的是,这本书的书名是作者的哥哥当年不得不写的一份读书报告。
“三十年前,我十岁的哥哥正在努力写一份关于鸟类的研究报告。他本来有三个月的时间进行写作,但是明天就要交了。我们在柏林阿斯的家里小屋里,哥哥他绞尽脑汁地写那份报告,几乎要留下眼泪,而他被这艰巨的任务禁锢在厨房餐桌旁,周围散落着活页纸、铅笔和一些没有开封过的鸟类书籍。这时候父亲来到旁边坐下,抱住哥哥的肩膀说道,“Bird by bird,孩子。就是把鸟一个个列出来””
后来他就完成了。
不要让天花乱坠宣传信息压倒你。不要因为那些时髦的词或者带着MacBook那种时尚人士形象所蒙蔽。集中在一只鸟的身上,从那里开始。
相关报道:
https://veekaybee.github.io/2019/02/13/data-science-is-different/
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】