一、问题分析
经过几分钟的排查,数据库情况如下:
数据库采用SQLserver 2008 R2,单表数据量21亿

无水平或者垂直切分,但是采用了分区表。分区表策略是按时间降序分的区,将近30个分区。正因为分区表的原因,系统才保证了在性能不是太差的情况下坚持至今。
此表除聚集索引之外,无其他索引,无主键(主键其实是利用索引来快速查重的)。所以在频繁插入新数据的情况下,索引调整所耗费的性能比较低。
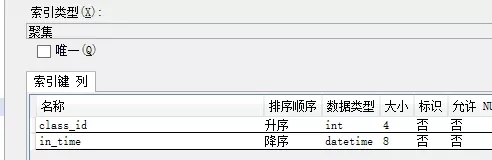
至于聚集索引和非聚集索引等知识,请各位移步google或者百度。
至于业务,不是太复杂。经过相关人员咨询,大约40%的请求为单条Insert,大约60%的请求为按class_id 和in_time(倒序)分页获取数据。Select请求全部命中聚集索引,所以性能非常高。这也是聚集索引这样设计的目的。
二、解决问题
由于单表数据量已经超过21亿,并且2017年以前的数据几乎不影响业务,所以决定把2017年以前(不包括2017年)的数据迁移到新表,仅供以后特殊业务查询使用。经过查询大约有9亿数据量。
数据迁移工作包括三个个步骤:
- 从源数据表查询出要迁移的数据
- 把数据插入新表
- 把旧表的数据删除
1、传统做法
这里申明一点,就算是传统的做法也需要分页获取源数据,因为你的内存一次性装载不下9亿条数据。
1)从源数据表分页获取数据,具体分页条数,太少则查询原表太频繁,太多则查询太慢。
SQL语句类似于:
SELECT * FROM (
SELECT *,ROW_NUMBER() OVER(ORDER BY class_id,in_time) p FROM tablexx WHERE in_time <'2017.1.1'
) t WHERE t.p BETWEEN 1 AND 100
- 1.
- 2.
- 3.
2)把查询出来的数据插入目标数据表,这里强调一点,一定不要用单条插入策略,必须用批量插入。
3)把数据删除,其实这里删除还是有一个小难点,表没有标示列。这里不展开,因为这不是本文要说的重点。
如果你的数据量不大,以上方法完全没有问题,但是在9亿这个数字前面,以上方法显得心有余而力不足。一个字:慢,太慢,非常慢。
可以大体算一下,假如每秒可以迁移1000条数据,大约需要的时间为(单位:分):
900000000/1000/60=15000(分钟)
- 1.
大约需要10天^ V ^
2、改进做法
以上的传统做法弊端在哪里呢?
- 在9亿数据前查询必须命中索引,就算是非聚集索引我也不推荐,首推聚集索引。
- 如果你了解索引的原理,你应该明白,不停的插入新数据的时候,索引在不停的更新,调整,以保持树的平衡等特性。尤其是聚集索引影响甚大,因为还需要移动实际的数据。
提取以上两点共同的要素,那就是聚集索引。相应的解决方案也就应运而生:
- 按照聚集索分页引查询数据;
- 批量插入数据迎合聚集索引,即:按照聚集索引的顺序批量插入;
- 按照聚集索引顺序批量删除;
由于做了表分区,如果有一种方式把2017年以前的分区直接在磁盘物理层面从当前表剥离,然后挂载到另外一个表,可算是神级操作。有谁能指导一下,不胜感激~
三、扩展阅读
一个表的聚集索引的顺序就是实际数据文件的顺序,映射到磁盘上,本质上位于同一个磁道上,所以操作的时候磁盘的磁头不必跳跃着去操作。
存储在硬盘中的每个文件都可分为两部分:文件头和存储数据的数据区。文件头用来记录文件名、文件属性、占用簇号等信息,文件头保存在一个簇并映射在FAT表(文件分配表)中。
而真实的数据则是保存在数据区当中的。
平常所做的删除,其实是修改文件头的前2个代码,这种修改映射在FAT表中,就为文件作了删除标记,并将文件所占簇号在FAT表中的登记项清零,表示释放空间,这也就是平常删除文件后,硬盘空间增大的原因。
而真正的文件内容仍保存在数据区中,并未得以删除。要等到以后的数据写入,把此数据区覆盖掉,这样才算是彻底把原来的数据删除。如果不被后来保存的数据覆盖,它就不会从磁盘上抹掉。
四、实际运行代码
第一步:由于聚集索引需要class_id,所以宁可花2-4秒时间把要操作的class_id查询出来(ORM为dapper),并且升序排列:
DateTime dtMax = DateTime.Parse("2017.1.1");
var allClassId = DBProxy.GeSourcetLstClassId(dtMax)?.OrderBy(s=>s);
- 1.
- 2.
按照第一步class_id列表顺序查询数据,每个class_id分页获取,然后插入目标表,全部完成然后删除源表相应class_id的数据。
D int pageIndex = 1; //页码
int pageCount = 20000;//每页的数据条数
DataTable tempData =null;
int successCount = 0;
foreach (var classId in allClassId)
{
tempData = null;
pageIndex = 1;
while (true)
{
int startIndex = (pageIndex - 1) * pageCount+1;
int endIndex = pageIndex * pageCount;
tempData = DBProxy.GetSourceDataByClassIdTable(dtMax, classId, startIndex, endIndex);
if (tempData == null || tempData.Rows.Count==0)
{
//末尾一页无数据了,删除源数据源数据然后跳出
DBProxy.DeleteSourceClassData(dtMax, classId);
break;
}
else
{
DBProxy.AddTargetData(tempData);
}
pageIndex++;
}
successCount++;
Console.WriteLine($"班级:{classId} 完成,已经完成:{successCount}个");
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
DBProxy完整代码:
class DBProxy
{
//获取要迁移的数据所有班级id
public static IEnumerable<int> GeSourcetLstClassId(DateTime dtMax)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @"SELECT class_id FROM tablexx WHERE in_time <@dtMax GROUP BY class_id ";
using (connection)
{
return connection.Query<int>(Sql, new { dtMax = dtMax }, commandType: System.Data.CommandType.Text);
}
}
public static DataTable GetSourceDataByClassIdTable(DateTime dtMax, int classId, int startIndex, int endIndex)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @" SELECT * FROM (
SELECT *,ROW_NUMBER() OVER(ORDER BY in_time desc) p FROM tablexx WHERE in_time <@dtMax AND class_id=@classId
) t WHERE t.p BETWEEN @startIndex AND @endIndex ";
using (connection)
{
DataTable table = new DataTable("MyTable");
var reader = connection.ExecuteReader(Sql, new { dtMax = dtMax, classId = classId, startIndex = startIndex, endIndex = endIndex }, commandType: System.Data.CommandType.Text);
table.Load(reader);
reader.Dispose();
return table;
}
}
public static int DeleteSourceClassData(DateTime dtMax, int classId)
{
var connection = Config.GetConnection(Config.SourceDBStr);
string Sql = @" delete from tablexx WHERE in_time <@dtMax AND class_id=@classId ";
using (connection)
{
return connection.Execute(Sql, new { dtMax = dtMax, classId = classId }, commandType: System.Data.CommandType.Text);
}
}
//SqlBulkCopy 批量添加数据
public static int AddTargetData(DataTable data)
{
var connection = Config.GetConnection(Config.TargetDBStr);
using (var sbc = new SqlBulkCopy(connection))
{
sbc.DestinationTableName = "tablexx_2017";
sbc.ColumnMappings.Add("class_id", "class_id");
sbc.ColumnMappings.Add("in_time", "in_time");
.
.
.
using (connection)
{
connection.Open();
sbc.WriteToServer(data);
}
}
return 1;
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
运行报告:
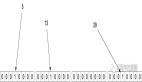
程序本机运行,开虚拟专用网络连接远程DB服务器,运行1分钟,迁移的数据数据量为1915560,每秒约3万条数据。
1915560 / 60=31926 条/秒
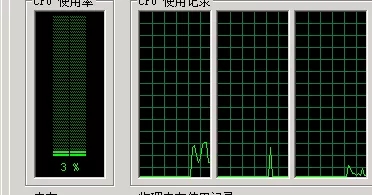
CPU情况(不高):
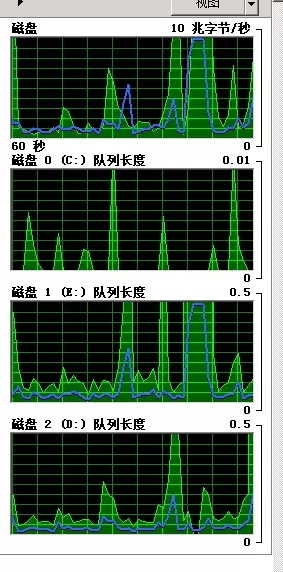
磁盘队列情况(不高):
五、写在后面
在以下情况下速度还将提高:
- 源数据库和目标数据库硬盘为ssd,并且分别为不同的服务器;
- 迁移程序和数据库在同一个局域网,保障数据传输时候带宽不会成为瓶颈;
- 合理的设置SqlBulkCopy参数;
- 我们的场景大多数场景下每次批量插入的数据量达不到设置的值,因为有的class_id 对应的数据量就几十条,甚至几条而已,打开关闭数据库连接也是需要耗时的;
- 单纯的批量添加或者批量删除操作。