












【51CTO.com原创稿件】相信很多 IT 界的朋友,昨天都被这条新闻刷屏了:阿里云宕机故障导致华北地区多家公司 App 和网站瘫痪。虽然目前阿里回应称故障已全部修复,但宕机事件对企业用户的影响和损失是巨大的。
3 月 3 日凌晨,有微博网友反映阿里云疑似出现宕机事故。这次宕机出现得丝毫没有征兆,以至于听说有不少工程师都是半夜里被从被窝里薅出来的。
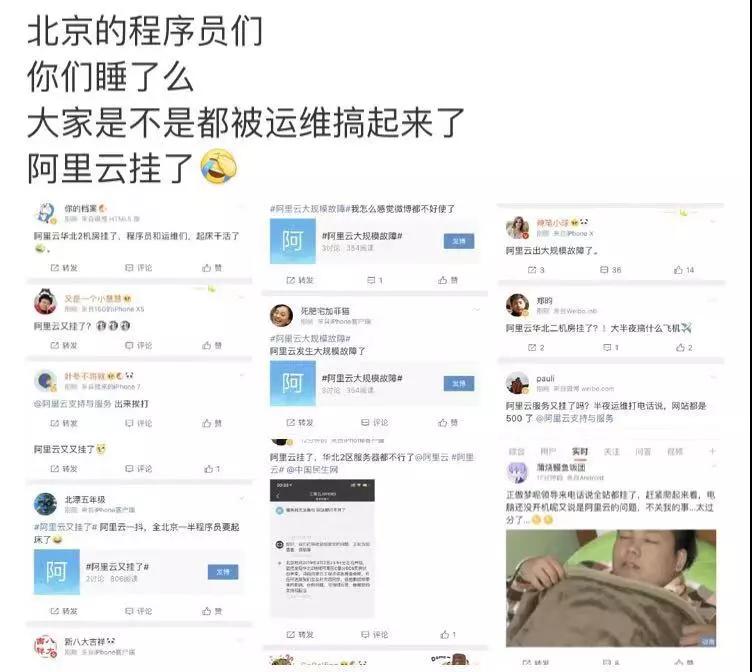
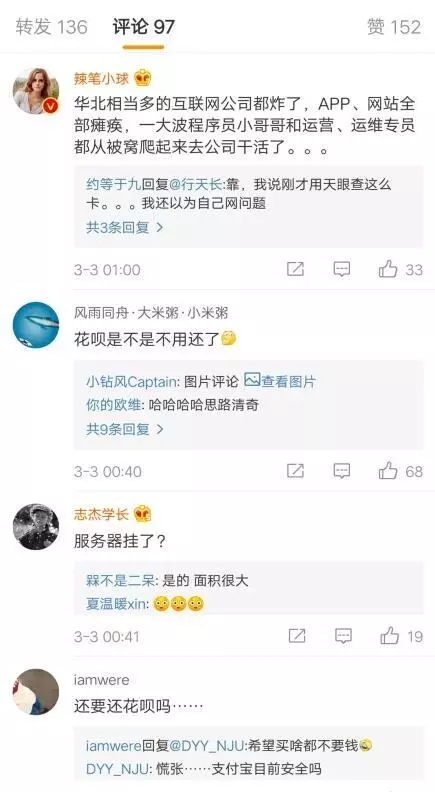
此次宕机引发众多网友吐槽,不过网友的反应很现实,他们心中关心的只有“花呗”:
阿里云方面表示,从 3 月 2 日 23:55 分左右开始,监控发现华北 2 地域可用区 C 部分 ECS 实例状态异常。
后经排查处理,为 ECS 服务器等实例出现 IO HANG,其他地域及可用区经过排查后未发现此类情况。所谓 IO HANG,就是云服务器的磁盘无响应。
对此,阿里云回应称,经紧急排查处理后全部恢复,针对本次故障,将根据 SLA 协议,尽快处理赔偿事宜,但阿里云并未公开详细的赔偿细节。
而根据阿里云开发者论坛上的网友说法,赔偿通常是按照故障时间的 100 倍进行的,而方案则根据包年包月预付费模式和按量付费模式有所不同,但总额不超过支付的单台云服务器费用总额。
经过 10 多年发展,云计算技术已经逐渐成熟,企业对于云计算的接受程度也在进一步提高。
由于云计算能够给企业 IT 运营、业务创新等带来明显效用,上云已经成为企业常态。
同样是 3 月 3 日的消息,全球云管理服务厂商 RightScale 发布 2019 年云状况调查报告,受调查用户表示 2019 年在公有云服务上的支出增长速度将是私有云的 3 倍,而包括阿里云在内的全球公有云厂商将受益于这一趋势。
根据 RightScale 报告,在被调查企业中公有云采用率为 91%,私有云采用率为 72%,也就是说,差不多超过 9 成的企业已经有工作流跑在公有云上。这一数据较上年持平,但较几年前出现了大幅上升。
公有云市场的大幅增长,除了其成本低,扩展性好之外,安全性越来越高也是重要的原因。但尽管双方约定的可用性为 99.99%,但意外的发生仍不可避免。
此次阿里云宕机事件,凡是会读写故障盘的系统软件或服务程序,都会受到影响,涉及很多互联网公司、App、网站。云上不可能做到绝对不出事,所以,容灾灾备才是负责任的做法。
针对企业的特点,构建健全的容灾制度、完整的容灾方案、良好的容灾系统,并在实践中不断的进行评估、反复测试、随时调整并加以改善,是刻不容缓的。
将重要业务分别放在不同的“篮子”里,选择多个云服务供应商,也是个不错的选择。
再来看看知乎网友@千杯不醉的评论:
公有云故障年年有,去年腾讯云故障导致客户数据丢失闹的沸沸扬扬,这次是阿里云。这两家都是业界标杆,犹且如此。
到目前为止没有看到其他云服务商借机营销,吹嘘自己有多牛逼,为什么?借用前边某位仁兄说的,做技术的,一定要心存敬畏。
我想起一件往事,大概两年前,与多家网络设备友商一起在上海某金融客户处讨论设备冗余架构。
某 H 司突然发起攻击,你们的设备就那么容易出故障吗!眼中满是鄙夷,似乎他家产品永远不会出问题。
这一下惹恼了其他友商,同时向客户建议,让 H 司签署永不出问题承诺,结果 H 司哑口无言。
就这次事件来说,有人说公有云就是不行,还是私有云牛逼,能达到多少个 9。
我做私有云多年,只想跟大家说,不是私有云可用性好,而是公有云故障传播面广,影响大。
再者,云服务的高可用性跟你的投入也有很大关系,金融业云服务之所以可用性好,在于他们相对来说不计成本,用相对较好的设备,搭建高度冗余的数据中心架构。
就像阿里云的这次故障,如果能够利用阿里云的 Region-AZ-DC 多级架构进行响应的冗余部署,相信业务基本可以不受影响。
你或许会说,如此部署成本高啊。对啊,所有的商品都是用合适的钱买合适的服务。
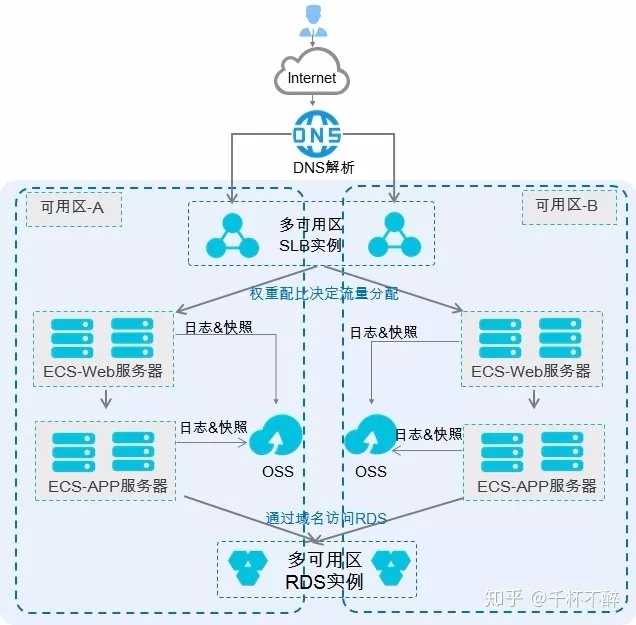
事实证明,鸡蛋不要放到一个篮子里(DC),篮子不要放到一辆车上(AZ),车不要走同一条路(Region)。基于此,我相信多云必将成为一个趋势。
也有网友吐槽到阿里云一年一宕机,今年特别早!在 2018 年 6 月,阿里云曾出现技术故障。尽管官方最终给出的故障时间仅为 30 分钟,而恢复时间需要 1 小时。
但阿里云最终仍将其定义为 S1 级别事故,即核心业务重要功能不可用,影响了部分用户,造成了一定损失。
根据 IDC 统计,阿里云占据近一半中国公有云市场。根据阿里云数据,有 40% 的国内网站和 50% 的独角兽公司都在使用阿里云。因此,阿里云每次的故障事件,都会引起轩然大波。
这是一场发生在周末的宕机时间,因微博的传播而备受关注。第三方机构 Forrester 分析师戴鲲称,华北 2 地域是阿里云最早开通服务的华北地域之一,而 ECS 服务器又是阿里云最为核心的 IaaS(基础设施即服务)之一,影响程度应当是相对较大的。
那么如何做好基础设施监控,防范意外停机呢?下面小编将介绍一些开源工具以及如何用它们来构建一套强大的监控架构。
如何做好基础设施监控,防范意外停机?
基础设施监控是基础设施管理的一个组成部分。它是 IT 管理员防范意外停机的首道防线。严重的问题可能导致基础设施出现大量停机时间,有时导致严重的经济损失。
监控系统从你的基础设施收集时间序列数据,以便对其进行分析,预测基础设施及底层部件即将出现的问题。这使得 IT 管理员或支持人员有时间在问题发生之前准备并运用解决方案。
一套良好的监控系统具有以下功能:
- 长期测量基础设施的性能
- 节点级分析和警报
- 网络级分析和警报
- 停机分析和警报
- 回答事件管理和根本原因分析(RCA)的五个 W
而回答事件管理和根本原因分析(RCA)的五个 W指的是:
- 实际问题是什么?
- 什么时候发生的?
- 为什么会发生?
- 什么系统或部件出现停机?
- 需要采取什么措施才能在将来避免?
建立强大的监控系统
有许多工具可以构建可行且强大的监控系统。就有一个决定是使用哪个工具;答案在于你希望通过监控实现的目标以及要考虑的各种财务和业务因素。
虽然一些监控工具是专有的,但许多开源工具(无人管理的软件或社区管理的软件)的效果甚至比闭源工具还好。
日志收集和分析
日志大有帮助。日志不仅有助于调试问题,还提供了大量信息,帮助预测即将发生的问题。遇到软件组件问题时,应首先分析日志。
Fluentd 和 Logstash 都可用于收集日志,我选择 Fluentd 而不是 Logstash 的仅有原因是因为它独立于 Java 进程。
它是用 C + Ruby 编写的,得到 Docker 等容器运行时环境和 Kubernetes 等编排工具的广泛支持。
日志分析是指分析逐渐收集的日志数据,并生成实时日志度量指标。Elasticsearch 是这方面的一款强大工具。
最后,你需要一个工具来收集日志度量指标,以便能够使用易于理解的图表和图形直观地显示日志趋势。Kibana 是我在这方面所青睐的选择。
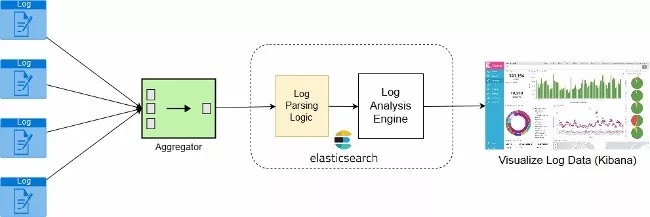
图 1:日志工作流程
由于日志可能保存敏感信息,因此需要记住几个安全要点:
- 始终通过安全的连接传输日志。
- 应在受限制的子网内实施日志/监控基础设施。
- 应仅限于利益相关者访问监控用户界面(比如 Kibana 和 Grafana)。
节点级度量指标
并非一切都记入日志!没错,日志监控的是软件或进程,而不是基础设施中的每个部件。
操作系统磁盘、外部挂载的数据磁盘、Elastic Block Store、CPU、I/O、网络数据包、入站和出站连接、物理内存、虚拟内存、缓冲区空间和队列是很少出现在日志中的一些主要部件,除非它们出了故障。
那么,如何收集这类数据呢?Prometheus 是个答案。你只需在虚拟机节点上安装针对特定软件的导出器,并配置 Prometheus,从这些无人值守的部件收集基于时间的数据。
Grafana 使用 Prometheus 收集的数据来实时直观地显示节点的当前状态。
如果你在寻找一个更简单的解决方案来收集时间序列指标,不妨考虑 Etricbeat,这是 Elastic.io 的内部开源工具,它可以与 Kibana 一起使用以取代 Prometheus 和 Grafana。
警报和通知
没有警报和通知,你就无法充分利用监控。除非利益相关者(无论他们人在哪里)接到有关问题的通知,否则他们就无法分析和解决问题、防止客户受到影响并在将来避免它。
Prometheus 使用其内部的 Alertmanager 和 Grafana 来创建预定义的警报规则,可以基于配置的规则发送警报。Sensu 和 Nagios 是提供警报和监控服务的其他开源工具。
人们在开源警报工具方面遇到的问题是,配置时间和过程有时看起来很费劲,但是一旦设置好,这些工具的效果比专有工具还好。然而,开源工具的突出优点是我们可以控制它们的行为。
监控工作流程和架构
良好的监控架构是强大而稳定的监控系统的支柱。它可能看起来像这个图:
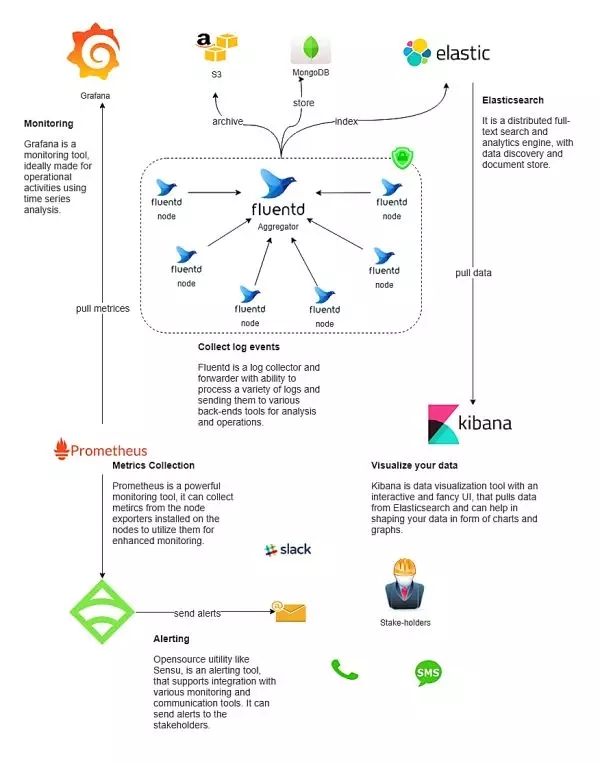
图 2:Devops 监控架构
你要根据自己的需求和基础设施来选择工具。许多企业组织使用本文中讨论的开源工具来监控基础设施并确保正常运行时间很长。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】













