【51CTO.com快译】基础设施监控是基础设施管理的一个组成部分。它是IT管理员防范意外停机的***道防线。严重的问题可能导致基础设施出现大量停机时间,有时导致严重的经济损失。
监控系统从你的基础设施收集时间序列数据,以便对其进行分析,预测基础设施及底层部件即将出现的问题。这使得IT管理员或支持人员有时间在问题发生之前准备并运用解决方案。
一套良好的监控系统具有以下功能:
1. 长期测量基础设施的性能
2. 节点级分析和警报
3. 网络级分析和警报
4. 停机分析和警报
5. 回答事件管理和根本原因分析(RCA)的五个W:
○实际问题是什么?
○什么时候发生的?
○为什么会发生?
○什么系统或部件出现停机?
○需要采取什么措施才能在将来避免?
建立强大的监控系统
有许多工具可以构建可行且强大的监控系统。唯一的决定是使用哪个工具;答案在于你希望通过监控实现的目标以及要考虑的各种财务和业务因素。
虽然一些监控工具是专有的,但许多开源工具(无人管理的软件或社区管理的软件)的效果甚至比闭源工具还好。
本文将介绍开源工具以及如何用它们来构建一套强大的监控架构。
日志收集和分析
日志大有帮助。日志不仅有助于调试问题,还提供了大量信息,帮助预测即将发生的问题。遇到软件组件问题时,应首先分析日志。
Fluentd和Logstash都可用于收集日志;我选择Fluentd而不是Logstash的唯一原因是因为它独立于Java进程;它是用C + Ruby编写的,得到Docker等容器运行时环境和Kubernetes等编排工具的广泛支持。
日志分析是指分析逐渐收集的日志数据,并生成实时日志度量指标。Elasticsearch是这方面的一款强大工具。
***,你需要一个工具来收集日志度量指标,以便能够使用易于理解的图表和图形直观地显示日志趋势。Kibana是我在这方面所青睐的选择。
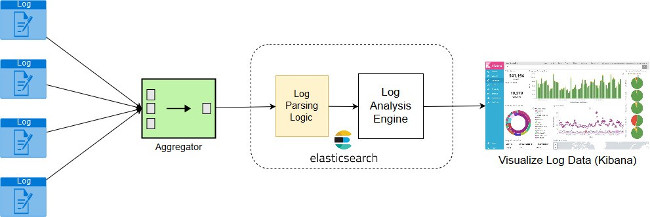
图1. 日志工作流程
由于日志可能保存敏感信息,因此需要记住几个安全要点:
•始终通过安全的连接传输日志。
•应在受限制的子网内实施日志/监控基础设施。
•应仅限于利益相关者访问监控用户界面(比如Kibana和Grafana)。
节点级度量指标
并非一切都记入日志!
没错,日志监控的是软件或进程,而不是基础设施中的每个部件。
操作系统磁盘、外部挂载的数据磁盘、Elastic Block Store、CPU、I/O、网络数据包、入站和出站连接、物理内存、虚拟内存、缓冲区空间和队列是很少出现在日志中的一些主要部件,除非它们出了故障。
那么,如何收集这类数据呢?
Prometheus是个答案。你只需在虚拟机节点上安装针对特定软件的导出器,并配置Prometheus,从这些无人值守的部件收集基于时间的数据。Grafana使用Prometheus收集的数据来实时直观地显示节点的当前状态。
如果你在寻找一个更简单的解决方案来收集时间序列指标,不妨考虑Etricbeat,这是Elastic.io的内部开源工具,它可以与Kibana一起使用以取代Prometheus和Grafana。
警报和通知
没有警报和通知,你就无法充分利用监控。除非利益相关者(无论他们人在哪里)接到有关问题的通知,否则他们就无法分析和解决问题、防止客户受到影响并在将来避免它。
Prometheus使用其内部的Alertmanager和Grafana来创建预定义的警报规则,可以基于配置的规则发送警报。Sensu和Nagios是提供警报和监控服务的其他开源工具。
人们在开源警报工具方面遇到的唯一问题是,配置时间和过程有时看起来很费劲,但是一旦设置好,这些工具的效果比专有工具还好。
然而,开源工具的***优点是我们可以控制它们的行为。
监控工作流程和架构
良好的监控架构是强大而稳定的监控系统的支柱。它可能看起来像这个图。
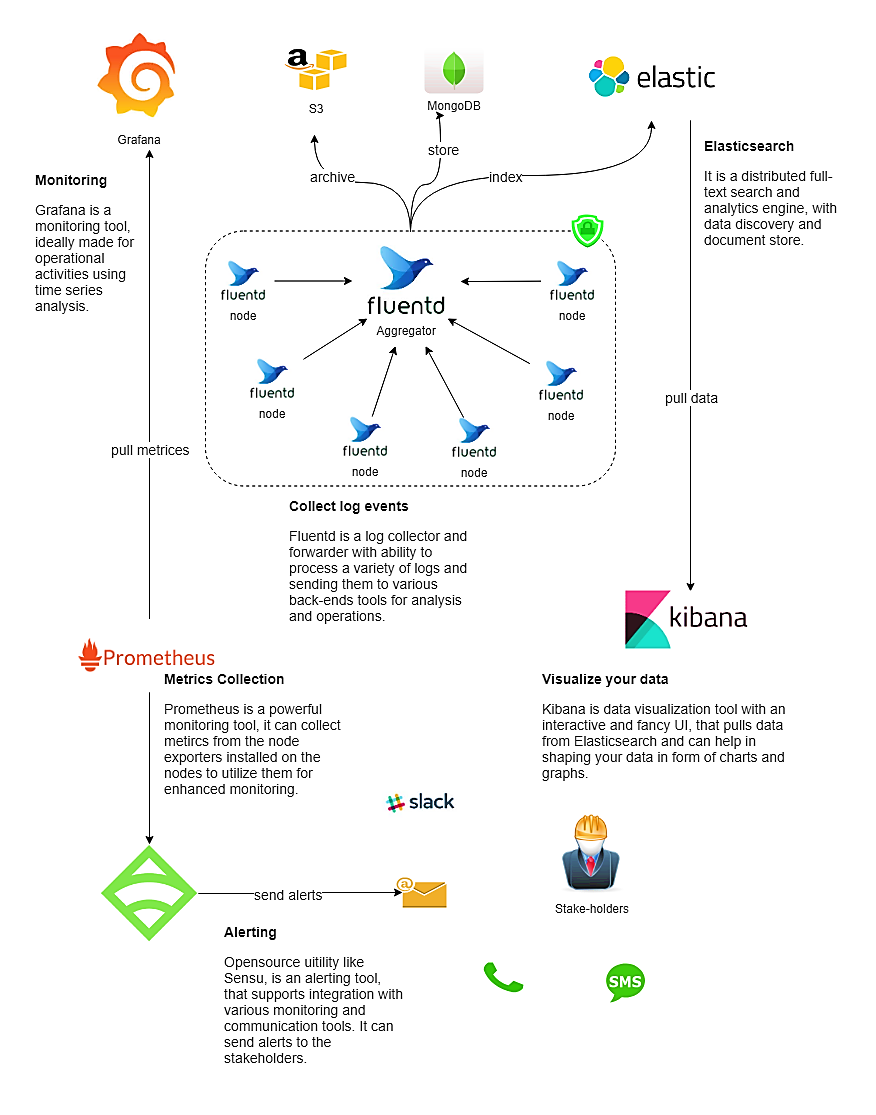
图2. Devops监控架构
***,你要根据自己的需求和基础设施来选择工具。许多企业组织使用本文中讨论的开源工具来监控基础设施并确保正常运行时间很长。
原文标题:Infrastructure monitoring: Defense against surprise downtime,作者:Abhishek Tamrakar
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】