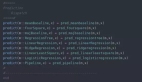
其实像以前 C 或其它主流语言在使用变量前先要声明变量的具体类型,而 Python 并不需要,赋值什么数据,变量就是什么类型。然而没想到正是这种类型稳定性,让 Julia 相比 Python 有更好的性能。
选择 Julia 的最主要原因:要比其他脚本语言快得多,让你拥有 Python/Matlab /R 一样快速的开发速度,同时像 C/Fortan 那样高效的运行速度。
Julia 的新手可能对下面这些描述略为谨慎:
- 为什么其他语言不能更快一点?Julia 能够做到,其他语言就不能?
- 你怎么解释 Julia 的速度基准?(对许多其他语言来说也很难?)
- 这听起来违背没有免费午餐定律,在其他方面是否有损失?
许多人认为 Julia 快是因为它使用的是 JIT 编译器,即每一条语句在使用前都先使用编译函数进行编译,不论是预先马上编译或之前先缓存编译。这就产生了一个问题,即 Python/R 和 MATLAB 等脚本语言同样可以使用 JIT 编译器,这些编译器的优化时间甚至比 Julia 语言都要久。所以为什么我们会疯狂相信 Julia 语言短时间的优化就要超过其它脚本语言?这是一种对 Julia 语言的完全误解。
在本文中,我们将了解到 Julia 快是因为它的设计决策。它的核心设计决策:通过多重分派的类型稳定性是允许 Julia 能快速编译并高效运行的核心,本文后面会具体解释为什么它是快的原因。此外,这一核心决策同时还能像脚本语言那样令语法非常简洁,这两者相加可以得到非常明显的性能增益。
但是,在本文中我们能看到的是 Julia 不总像其他脚本语言,我们需要明白 Julia 语言因为这个核心决策而有一些「损失」。理解这种设计决策如何影响你的编程方式,对你生成 Julia 代码而言非常重要。
为了看见其中的不同,我们可以先简单地看看数学运算案例。
Julia 中的数学运算
总而言之,Julia 中的数学运算看起来和其他脚本语言是一样的。值得注意的一个细节是 Julia 的数值是「真数值」,在 Float64 中真的就和一个 64 位的浮点数值一样,或者是 C 语言的「双精度浮点数」。一个 Vector{Float64} 中的内存排列等同于 C 语言双精度浮点数数组,这都使得它与 C 语言的交互操作变得简单(确实,某种意义上 Julia 是构建在 C 语言顶层的),且能带来高性能(对 NumPy 数组来说也是如此)。
Julia 中的一些数学:
- a = 2+2
- b = a/3
- c = a÷3 #\div tab completion, means integer division
- d = 4*5
- println([a;b;c;d])
output: [4.0, 1.33333, 1.0, 20.0]
此外,数值乘法在后面跟随着变量的情况下允许不使用运算符 *,例如以下的计算可通过 Julia 代码完成:
- α = 0.5
- ∇f(u) = α*u; ∇f(2)
- sin(2π)
output: -2.4492935982947064e-16
类型稳定和代码自省
类型稳定,即从一种方法中只能输出一种类型。例如,从 *(:: Float64,:: Float64) 输出的合理类型是 Float64。无论你给它的是什么,它都会反馈一个 Float64。这里是一种多重分派(Multiple-Dispatch)机制:运算符 * 根据它看到的类型调用不同的方法。当它看到 floats 时,它会反馈 floats。Julia 提供代码自省(code introspection)宏,以便你可以看到代码实际编译的内容。因此 Julia 不仅仅是一种脚本语言,它更是一种可以让你处理汇编的脚本语言!与许多语言一样,Julia 编译为 LLVM(LLVM 是一种可移植的汇编语言)。
- @code_llvm 2*5
- ; Function *
- ; Location: int.jl:54
- define i64 @"julia_*_33751"(i64, i64) {
- top:
- %2 = mul i64 %1, %0
- ret i64 %2
- }
这个输出表示,执行浮点乘法运算并返回答案。我们甚至可以看一下汇编:
- @code_llvm 2*5
- .text
- ; Function * {
- ; Location: int.jl:54
- imulq %rsi, %rdi
- movq %rdi, %rax
- retq
- nopl (%rax,%rax)
- ;}
这表示*函数已编译为与 C / Fortran 中完全相同的操作,这意味着它实现了相同的性能(即使它是在 Julia 中定义的)。因此,不仅可以「接近」C 语言的性能,而且实际上可以获得相同的 C 代码。那么在什么情况下会发生这种事情呢?
关于 Julia 的有趣之处在于,我们需要知道什么情况下代码不能编译成与 C / Fortran 一样高效的运算?这里的关键是类型稳定性。如果函数是类型稳定的,那么编译器可以知道函数中所有节点的类型,并巧妙地将其优化为与 C / Fortran 相同的程序集。如果它不是类型稳定的,Julia 必须添加昂贵的「boxing」以确保在操作之前找到或者已明确知道的类型。
这是 Julia 和其他脚本语言之间最为关键的不同点!
好处是 Julia 的函数在类型稳定时基本上和 C / Fortran 函数一样。因此^(取幂)很快,但既然 ^(:: Int64,:: Int64)是类型稳定的,那么它应输出什么类型?
- 2^5
output: 32
- 2^-5
output: 0.03125
这里我们得到一个错误。编译器为了保证 ^ 返回一个 Int64,必须抛出一个错误。如果在 MATLAB,Python 或 R 中执行这个操作,则不会抛出错误,这是因为那些语言没有围绕类型稳定性构建整个语言。
当我们没有类型稳定性时会发生什么呢?我们来看看这段代码:
- @code_native ^(2,5)
- .text
- ; Function ^ {
- ; Location: intfuncs.jl:220
- pushq %rax
- movabsq $power_by_squaring, %rax
- callq *%rax
- popq %rcx
- retq
- nop
- ;}
现在让我们定义对整数的取幂,让它像其他脚本语言中看到的那样「安全」:
- function expo(x,y)
- if y>0
- return x^y
- else
- x = convert(Float64,x)
- return x^y
- end
- end
output: expo (generic function with 1 method)
确保它有效:
- println(expo(2,5))
- expo(2,-5)
output: 32
0.03125
当我们检查这段代码时会发生什么?
- @code_native expo(2,5)
- .text
- ; Function expo {
- ; Location: In[8]:2
- pushq %rbx
- movq %rdi, %rbx
- ; Function >; {
- ; Location: operators.jl:286
- ; Function <; {
- ; Location: int.jl:49
- testq %rdx, %rdx
- ;}}
- jle L36
- ; Location: In[8]:3
- ; Function ^; {
- ; Location: intfuncs.jl:220
- movabsq $power_by_squaring, %rax
- movq %rsi, %rdi
- movq %rdx, %rsi
- callq *%rax
- ;}
- movq %rax, (%rbx)
- movb $2, %dl
- xorl %eax, %eax
- popq %rbx
- retq
- ; Location: In[8]:5
- ; Function convert; {
- ; Location: number.jl:7
- ; Function Type; {
- ; Location: float.jl:60
- L36:
- vcvtsi2sdq %rsi, %xmm0, %xmm0
- ;}}
- ; Location: In[8]:6
- ; Function ^; {
- ; Location: math.jl:780
- ; Function Type; {
- ; Location: float.jl:60
- vcvtsi2sdq %rdx, %xmm1, %xmm1
- movabsq $__pow, %rax
- ;}
- callq *%rax
- ;}
- vmovsd %xmm0, (%rbx)
- movb $1, %dl
- xorl %eax, %eax
- ; Location: In[8]:3
- popq %rbx
- retq
- nopw %cs:(%rax,%rax)
- ;}
这个演示非常直观地说明了为什么 Julia 使用类型推断来实现能够比其他脚本语言有更高的性能。
核心观念:多重分派+类型稳定性 => 速度+可读性
类型稳定性(Type stability)是将 Julia 语言与其他脚本语言区分开的一个重要特征。实际上,Julia 的核心观念如下所示:
(引用)多重分派(Multiple dispatch)允许语言将函数调用分派到类型稳定的函数。
这就是 Julia 语言所有特性的出发点,所以我们需要花些时间深入研究它。如果函数内部存在类型稳定性,即函数内的任何函数调用也是类型稳定的,那么编译器在每一步都能知道变量的类型。因为此时代码和 C/Fortran 代码基本相同,所以编译器可以使用全部的优化方法编译函数。
我们可以通过案例解释多重分派,如果乘法运算符 * 为类型稳定的函数:它因输入表示的不同而不同。但是如果编译器在调用 * 之前知道 a 和 b 的类型,那么它就知道哪一个 * 方法可以使用,因此编译器也知道 c=a * b 的输出类型。因此如果沿着不同的运算传播类型信息,那么 Julia 将知道整个过程的类型,同时也允许实现完全的优化。多重分派允许每一次使用 * 时都表示正确的类型,也神奇地允许所有优化。
我们可以从中学习到很多东西。首先为了达到这种程度的运行优化,我们必须拥有类型稳定性。这并不是大多数编程语言标准库所拥有的特性,只不过是令用户体验更容易而需要做的选择。其次,函数的类型需要多重分派才能实现专有化,这样才能允许脚本语言变得「变得更明确,而不仅更易读」。***,我们还需要一个鲁棒性的类型系统。为了构建类型不稳定的指数函数(可能用得上),我们也需要转化器这样的函数。
因此编程语言必须设计为具有多重分派的类型稳定性语言,并且还需要以鲁棒性类型系统为中心,以便在保持脚本语言的句法和易于使用的特性下实现底层语言的性能。我们可以在 Python 中嵌入 JIT,但如果需要嵌入到 Julia,我们需要真的把它成设计为 Julia 的一部分。
Julia 基准
Julia 网站上的 Julia 基准能测试编程语言的不同模块,从而希望获取更快的速度。这并不意味着 Julia 基准会测试最快的实现,这也是我们对其主要的误解。其它编程语言也有相同的方式:测试编程语言的基本模块,并看看它们到底有多快。
Julia 语言是建立在类型稳定函数的多重分派机制上的。因此即使是最初版的 Julia 也能让编译器快速优化到 C/Fortran 语言的性能。很明显,基本大多数案例下 Julia 的性能都非常接近 C。但还有少量细节实际上并不能达到 C 语言的性能,首先是斐波那契数列问题,Julia 需要的时间是 C 的 2.11 倍。这主要是因为递归测试,Julia 并没有完全优化递归运算,不过它在这个问题上仍然做得非常好。
用于这类递归问题的最快优化方法是 Tail-Call Optimization,Julia 语言可以随时添加这类优化。但是 Julia 因为一些原因并没有添加,主要是:任何需要使用 Tail-Call Optimization 的案例同时也可以使用循环语句。但是循环对于优化显得更加鲁棒,因为有很多递归都不能使用 Tail-Call 优化,因此 Julia 还是建议使用循环而不是使用不太稳定的 TCO。
Julia 还有一些案例并不能做得很好,例如 the rand_mat_stat 和 parse_int 测试。然而,这些很大程度上都归因于一种名为边界检测(bounds checking)的特征。在大多数脚本语言中,如果我们对数组的索引超过了索引边界,那么程序将报错。Julia 语言默认会完成以下操作:
- function test1()
- a = zeros(3)
- for i=1:4
- a[i] = i
- end
- end
- test1()
- BoundsError: attempt to access 3-element Array{Float64,1} at index [4]
- Stacktrace:
- [1] setindex! at ./array.jl:769 [inlined]
- [2] test1() at ./In[11]:4
- [3] top-level scope at In[11]:7
然而,Julia 语言允许我们使用 @inbounds 宏关闭边界检测:
- function test2()
- a = zeros(3)
- @inbounds for i=1:4
- a[i] = i
- end
- end
- test2()
这会为我们带来和 C/Fortran 相同的不安全行为,但是也能带来相同的速度。如果我们将关闭边界检测的代码用于基准测试,我们能获得与 C 语言相似的速度。这是 Julia 语言另一个比较有趣的特征:它默认情况下允许和其它脚本语言一样获得安全性,但是在特定情况下(测试和 Debug 后)关闭这些特征可以获得完全的性能。
核心概念的小扩展:严格类型形式
类型稳定性并不是唯一必须的,我们还需要严格的类型形式。在 Python 中,我们可以将任何类型数据放入数组,但是在 Julia,我们只能将类型 T 放入到 Vector{T} 中。为了提供一般性,Julia 语言提供了各种非严格形式的类型。最明显的案例就是 Any,任何满足 T:
- a = Vector{Any}(undef,3)
- a[1] = 1.0
- a[2] = "hi!"
- a[3] = :Symbolic
- a
output::
- 3-element Array{Any,1}:
- 1.0
- "hi!"
- :Symbolic
抽象类型的一种不太极端的形式是 Union 类型,例如:
- a = Vector{Union{Float64,Int}}(undef,3)
- a[1] = 1.0
- a[2] = 3
- a[3] = 1/4
- a
output:
- 3-element Array{Union{Float64, Int64},1}:
- 1.0
- 3
- 0.25
该案例只接受浮点型和整型数值,然而它仍然是一种抽象类型。一般在抽象类型上调用函数并不能知道任何元素的具体类型,例如在以上案例中每一个元素可能是浮点型或整型。因此通过多重分派实现优化,编译器并不能知道每一步的类型。因为不能完全优化,Julia 语言和其它脚本语言一样都会放慢速度。
这就是高性能原则:尽可能使用严格的类型。遵守这个原则还有其它优势:一个严格的类型 Vector{Float64} 实际上与 C/Fortran 是字节兼容的(byte-compatible),因此它无需转换就能直接用于 C/Fortran 程序。
高性能的成本
很明显 Julia 语言做出了很明智的设计决策,因而在成为脚本语言的同时实现它的性能目标。然而,它到底损失了些什么?下一节将展示一些由该设计决策而产生的 Julia 特性,以及 Julia 语言各处的一些解决工具。
1. 可选的性能
前面已经展示过,Julia 会通过很多方式实现高性能(例如 @inbounds),但它们并不一定需要使用。我们可以使用类型不稳定的函数,它会变得像 MATLAB/R/Python 那样慢。如果我们并不需要***的性能,我们可以使用这些便捷的方式。
2. 检测类型稳定性
因为类型稳定性极其重要,Julia 语言会提供一些工具以检测函数的类型稳定性,这在 @code_warntype 宏中是最重要的。下面我们可以检测类型稳定性:
- @code_warntype 2^5
- Body::Int64
- │220 1 ─ %1 = invoke Base.power_by_squaring(_2::Int64, _3::Int64)::Int64
- │ └── return %1
注意这表明函数中的变量都是严格类型,那么 expo 函数呢?
- @code_warntype 2^5
- Body::Union{Float64, Int64}
- │╻╷ >2 1 ─ %1 = (Base.slt_int)(0, y)::Bool
- │ └── goto #3 if not %1
- │ 3 2 ─ %3 = π (x, Int64)
- │╻ ^ │ %4 = invoke Base.power_by_squaring(%3::Int64, _3::Int64)::Int64
- │ └── return %4
- │ 5 3 ─ %6 = π (x, Int64)
- ││╻ Type │ %7 = (Base.sitofp)(Float64, %6)::Float64
- │ 6 │ %8 = π (%7, Float64)
- │╻ ^ │ %9 = (Base.sitofp)(Float64, y)::Float64
- ││ │ %10 = $(Expr(:foreigncall, "llvm.pow.f64", Float64, svec(Float64, Float64), :(:llvmcall), 2, :(%8), :(%9), :(%9), :(%8)))::Float64
- │ └── return %10
函数返回可能是 4% 和 10%,它们是不同的类型,所以返回的类型可以推断为 Union{Float64,Int64}。为了准确追踪不稳定性产生的位置,我们可以使用 Traceur.jl:
- using Traceur
- @trace expo(2,5)
- ┌ Warning: x is assigned as Int64
- └ @ In[8]:2
- ┌ Warning: x is assigned as Float64
- └ @ In[8]:5
- ┌ Warning: expo returns Union{Float64, Int64}
- └ @ In[8]:2
output:32
这表明第 2 行 x 分派为整型 Int,而第 5 行它被分派为浮点型 Float64,所以类型可以推断为 Union{Float64,Int64}。第 5 行是明确调用 convert 函数的位置,因此这为我们确定了问题所在。原文后面还介绍了如何处理不稳定类型,以及全局变量 Globals 拥有比较差的性能,希望详细了解的读者可查阅原文。
结 论
设计上 Julia 很快。类型稳定性和多重分派对 Julia 的编译做特化很有必要,使其工作效率非常高。此外,鲁棒性的类型系统同样还需要在细粒度水平的类型上正常运行,因此才能尽可能实现类型稳定性,并在类型不稳定的情况下尽可能获得更高的优化。
原文链接:https://ucidatascienceinitiative.github.io/IntroToJulia/Html/WhyJulia
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】