【51CTO.com原创稿件】经过多年的发展,从大数据1.0的BI/Datawarehouse时代,到大数据2.0的Web/App过渡期间,再进入到IOT的大数据3.0时代,随之而来的是数据架构的变化。
2018 年 5 月 18-19 日,由 51CTO 主办的全球软件与运维技术峰会在北京召开。在“大数据处理技术”分会场,来自易观智库的CTO郭炜先生为我们带来了《Lambda架构已死,新一代的去ELT化IOTA架构》的主题演讲。
他就Lambda与Kappa架构的发展及优缺点展开,分享IOTA大数据架构的思路及优缺点,以及易观在IOTA架构领域的实践经验。
IOTA架构的背景

首先介绍我们遇到过的各种数据问题和提出IOTA架构的背景。
我们的数据来源于手机的SDK。上图是易观当前的数据规模。如今月活数已经达到了5.5个亿,其中包含有大概20多亿个用户画像(Profile),并且已“打上了”各种维度的标签。
那么面对这么多维度的数据量,以及层出不穷的新数据,我们该如何支持好各种数据的运作呢?

我们先来看看IOTA架构的提出背景。上图右侧是易观在前两年构建的大数据架构,底层是SDK采集各类数据的过程。
由于每天都会有几百亿条的数据量,因此我们在SDK上采取的是“云+端”的控制策略,以避免底层SDK沦为导流层。
目前我们使用的接收带宽已达到6个GB。当有并发数据传到我们的接收端时,可能会出现几个GB以上的流量爆增,因此我们要避免这种类似DDoS情况的出现。
在底层上面,我们基于Kafka自行定制了各种内部使用的队列与分发。与此同时,我们实现了多方的HDFS查询,并基于此构建了批量查询的Hive。
对于前端的各种产品,我们用Greenplum实现了Ad—hoc查询。同时,我们用Presto来满足内部分析师的各种查询需求。
图中的右侧部分是内部的一些数据治理服务,包括对源数据的管理、数据口径与质量的检测、以及左侧绿色的各种调度服务。
上述便是我们在前两年构建的内部大数据结构。当然,我们也遇到了如下各种问题:
- 如今IoT的时代已经来临,各种智能硬件设备接踵而至,包括智能手环,医用糖尿病筛查设备、智能WiFi、BCON和智能摄像头等。随着数据越来越复杂,简单的移动客户端已经无法满足我们采集和分析数据的需求了。
- 随着IoT设备的面市和产生的巨大数据量级,其采集频次远大于人工点击,这给整个架构带来了更大的挑战。
- 数据格式不统一,例如一种云摄像头的数据格式,就不一定与其他厂商的IoT摄像头相同。
- 数据格式多变,会导致业务查询的频繁变更。我们易观的70多名分析师,他们所要求的数据类型,每天都不尽相同。
- 数据需要能够被实时地查询到。
我们以转化查询为例:某公司要在双十一大促的活动中,查询一下自己前一个小时广告投放的效果、以及价格波动对于用户***购买的影响。这些都属于Ad-hoc式查询。
Lambda架构
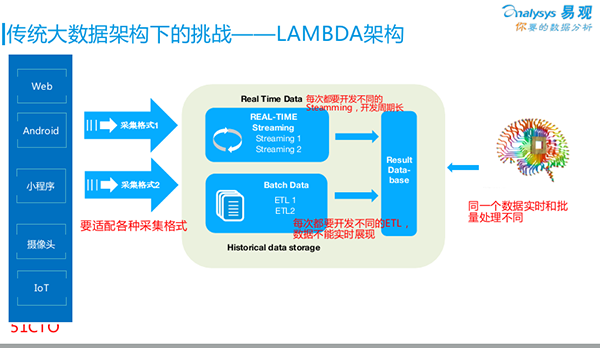
我们回头来看Lambda架构。如今80%~90%的企业都在使用Lambda架构进行自己的大数据分析,包括我们自己也是从Lambda架构过渡而来。
如图所示,所有的数据采集都是从最左侧进入架构的。根据不同的SDK,各种数据源所采集到的数据格式会有所不同。它们在此汇聚到我们云端的大数据平台。
我们通过两条线来保证数据的实时性和有效性:
- 通过传统的ETL,我们将数据做成批量任务—Batch Data,每晚运行一次,次日早上我们去查看相关的数据结果。
- 为了保证实时地采集,例如:需要根据销售量来做出智能推荐的决策,或是查看当日的PV/UV,那么我们就去“跑”一些Data Streaming(数据流)。
上述两条线的结果,最终都被放入一个Result Database(结果数据库,如某个MySQL)中,以方便我们的前端应用,通过该数据库,来查询后端的数据。
但是,该架构存在着如下问题:
1. 业务方会发现,次日看到的数据比昨晚看到的要少。原因在于:数据在被放入Result Database时,走了两条线的计算方式:一条线是ETL按照某个口径“跑”过来,得到更为准确的批量处理结果;另一条线是通过Streaming“跑”过来,依靠Hadoop Hive或其他算法得出的实时性结果。当然它牺牲了部分的准确性。可见,这两个来自批量的和实时的数据结果是对不上的,因此大家觉得很困惑。
2. 针对每一次实时分析的需求,都需要用Data Streaming重新开发一次。无论您是用Storm、Spark Streaming还是Flink,只要你想查看某个结果,就必须开发一次流式计算。也就是说,我们要按需做各种各样的ETL开发,这显然效率不高。
3. 我们做数据清洗的目的就是为了得到更好的数据格式,然后放到大数据平台之上。但是由于平台需要通过处理,来适配不同的采集格式,因此,我们无法迅速地呈现不同领域的实时数据。
KAPPA架构

后来LinkedIn提出了一个新的架构:KAPPA。它的理念是:鉴于大家认为批量数据和实时数据对不上是个问题,它直接去掉了批量数据;而直接通过队列,放入实时数据之中。
例如:将所有的数据直接放到原来的Kafka中,然后通过Kafka的Streaming,去直接面向***的查询结果。
当然,该架构也存在着一些问题:
1. 不能及时查询和训练。例如:我们的分析师想通过一条SQL语句,来查询前五秒的状态数据。这对于KAPPA架构是很难去实现的。
2. 面对各种需求,它同样也逃不过每次需要重新做一次Data Streaming。也就是说,它无法实现Ad—hoc查询,我们必需针对某个需求事先准备好,才能进行数据分析。
3. 新数据源的结构问题。例如:要新增一台智能硬件设备,我们就要重新开发一遍它对应的适配格式、负责采集的SDK、以及SDK的接收端等,即整体都要重复开发一遍。
因此,虽然KAPPA架构比Lambda好的方面是不必实时地把ETL数据做两遍,但是它仍然存在着结构上的问题。
IOTA架构

至此,我们提出了IOTA架构。在取名上,它是基于希腊字母的顺序,即:从IOTA、到KAPPA、再到Lambda的。
我们首先来看看IOTA架构的基本思路。鉴于大家既需要支持实时数据、又要支持Ad—hoc查询,还要支持各种数据的适配,因此该架构必然会有一些“约束”。
***个约束:我们应事先确定好通用的数据模型(Common Data Model)。例如:我们在做用户行为分析时,可以通过一种“主-谓-宾”的模型去描述:“谁对什么做了什么”。而剩下的其他修饰词,则完全可以被作为其他的列和参数。
在此模型基础上,所有的数据其实并非在中央被处理,而是在最开始的SDK端被操作。在此我们可以引入边缘计算的概念,即:不是在云端加工数据,而是把所有数据分散到从数据产生到***存储整个过程之中。
另外,由于一般公司的业务并不会天天发生变化,因此我们可以抽象出一套完整的业务模型,进而实现在边缘端做数据统一,而不是在云端进行。

如上图中所提到的Common Data Model的示例。我们可以用“主-谓-宾”模型,即“X用户 – 事件1 – A页面(2018/4/11 20:00)”来进行抽象。
当然,我们也可以根据业务的不同需求,使用“产品-事件”、或“地点-时间”模型。

第二个约束:对于同样的硬件设备而言,我们完全可以将“X用户的MAC 地址-出现- A楼层(2018/4/11 18:00)”模型,与前面提到的“主-谓-宾”模型统一成一种。
也就是说,无论是App小程序、Web页面、摄像头、还是IoT智能WiFi,只要数据模型是统一的,你就能够在数据产生端,统一整体的数据格式。
第三个约束:由于云端的数据只负责存储和查询,而不再负责做加工。
因此在IOTA架构中,有着如下主要的组成部分:
- Real Time Data Cache,对于海量的实时数据,我们会存储到云端,但是在将它们直接导入数据库的时候则会产生延迟,因此我们需要选用Hbase或Kudu之类的组件,来实现简单的列式存储。
- Historical Data,针对的是大量历史数据的底层存储,我们可以在云端用到HDFS。而之所以不将实时数据直接接入HDFS,是为了避免产生大量的碎片文件,而影响到最终的查询效率。
- Dumper,该程序实现并衔接了从Real Time Data Cache到数据的存储。我们可以按照既定的规则(每五分钟、或到达一百万条数据时),将Real Time Data Cache“落”到HDFS文件中。同时,我们也可以添加相关的索引,为后面的Query Engine做好准备。
- Query Engine,它可以用到的计算引擎包括:Spark、Presto、Impala等。通过Query Engine,我们既可以查询存储在HDFS的底层数据,又可以查询几分钟前的实时数据。另外,通过两者的合并,分析师还能够实现智能分析。
因此,基本的流程是:底层的SDK先将数据的格式予以统一,接着先存放在Cache里,然后再放入Historical Data中。
而在查询时,我们可以暴露一个SQL接口(如:Presto或SparkSQL),以供分析师们直接查看到几秒之前的各种数据状态。
例如:我们可以通过Query Engine查询到:用户是如何从登录页面最终点击到了购买页面,他们所经历的智能路径和触发过的事件等。这些一连串的前后相关的数据都能够被实时地显示出来,甚至包括一些Ad-hoc的查询。
总结
我们再回顾一下上面提到的重要方面:
- 通用数据模型非常重要,它贯穿整个业务的始终,从SDK的产生直至***的存储,以及按需查询。当然,如果模型本身上无法固定,我们则可以用Protobuf在SDK中先行定义一个模型。在做好了协议架构的基础上,如果后期需求固定下来了,我们只要保持从底层到上层的模型统一,那么修改起来就十分方便,甚至都不会涉及到云端存储的改动。
- 数据缓冲区,主要用来减少索引的延迟和历史数据的碎片等问题。
- 历史数据沉浸区,主要是为了Ad-hoc查询,其包括建立好各种相关的索引,以实现秒级的结果返回。
- SDK,过去我们只是让SDK进行简单地埋点和采集,而如今,我们在SDK上增加了一些简单的计算,让数据在产生端就完成了转化。
- 如果产生端(如摄像头)的性能不够,我们可以为它添加一台专门用作转化的EdgeAIServer服务器,从而实现上述提到的“主-谓-宾”模型的格式输出。当然,对于App和H5页面来说,由于没有计算的工作量,因此只要求埋点格式即可。

根据上述对于IOTA模型的介绍,我们对原来的大数据系统做了相应的调整。
具体情况如下:
- 我们的数据查询已不再需要ETL,而是通过Query Engine实现了数据的各种留存、转化、营销和分析等操作。
- 针对查询服务,我们基于Presto进行了二次开发,并构建出了“秒算平台”。
- 对应上面提到过的“主-谓-宾”模型,我们相应地制定了两个主要的数据存储结构:“用户/事件”,即:“谁在哪发生了什么”。
- 为了保证缓存中的数据能够被顺利地“灌”入Historical Data所对应的存储区域,我们配置了DumpMR服务模块。
- 针对“灌入”的数据会被分成很多个文件,如:每十分钟产生一个文件的情况,我们配置了MergerMR服务模块,它能够将这些碎片化的多个文件合并成为一个大的存储块。另外,我们还为这些数据重新添加了索引,以方便实时地进行计算。
- 在“秒算平台”上,我们运用Hbase来对实时数据进行缓存,并用HDFS来对历史数据进行存储。
- 由于我们将Presto作为查询服务引擎,为了能让它能够连接HDFS和Hbase,我们自行研发了一些Connector。通过我们的二次开发,它能够支持诸如MySQL、Redis和MongoDB等各种第三方数据库的查询。
- 我们对从用户处收集来的大数据,根据上面提到的“用户/事件”和“主-谓-宾”模型,直接放到SDK里,进行相关的计算。
众所周知,任何一种软件只有经历了开放源代码,才能够不断地促进自己的完善与发展。虽然我们的系统目前尚属内部版本,但是我们计划在今年底,将上述提到的基于IOTA架构模型的“秒算平台”开源出来,以供大家使用。
有了这样的平台,大家可以基于其存储引擎来快速地进行二次开发,而不必自己去写HDFS、Connector、DumpMR、MergerMR、以及一大堆Profile相关的代码。我们会把这些“坑”事先帮大家“填好”,大家直接用它去做用户级别的数据分析便可。

目前,就易观大数据混合云的数据规模和性能而言,已经能够根据我们分析师的各种Ad-hoc数据查询需求,实现了秒级的结果返回。同时,我们内部的秒算服务引擎,也能够支持并提供带有各种分析结果的分析报告。
郭炜,现任易观CTO,负责易观整体技术架构及分析产品线。北大计算系本科与研究生,在Teradata,IBM,中金负责大数据方向架构师或研发总监,后任万达电商数据部总经理,联想研究院大数据总监。在电商、移动互联网、商业地产、百货、移动通信、零售、院线等多个业务领域大数据方面具有搭建团队、系统以及分领域的分析与算法经验。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】