本文经AI新媒体量子位(公众号 ID: QbitAI)授权转载,转载请联系出处
AI一本正经的“胡编”起来,已经逼真的让人不敢相信。
刚刚,OpenAI发布了一个“逆天”的语言AI,整个模型包含15亿个参数。
这个AI写起文章来文思泉涌毫无违和感,无需针对性训练就能横扫各种特定领域的语言建模任务,还具备阅读理解、问答、生成文章摘要、翻译等等能力。
因为假新闻实在编的太真实,OpenAI说:我们不敢放出完整模型。
它的作品究竟什么样呢?
人类只给了它两句话的开头:
科学家们有个令人震惊的发现,在安第斯山脉一个偏远且没被开发过的山谷里,生活着一群独角兽。更加让人讶异的是,这些独角兽说着流利的英文。

AI就顺着这胡言乱语的设定,一本正经地编了下去 (欲赏全篇请见文末) :
这些生物有着独特的角,科学家们就以此为它们命名,叫Ovid’s Unicorn。长着四只角的银白色生物,在这之前并不为科学界所知。
……
虽然,这些生物的起源还不清楚,但有些人相信,它们是一个人和一个独角兽相交而诞生的,那时人类文明还不存在。Pérez教授说:“在南美洲,这样的现象很常见。”
……


天马行空却言之凿凿。几乎没有矛盾信息,甚至在结尾严谨地表明:
如果要确认它们是消失种族的后裔,DNA检测可能是比较有效的方法。
这位AI写手,名叫GPT-2。
它训练用的数据,都是人类写作的原始文本。无监督学习过程,纯洁无污染。
对此,深度学习之父Hinton献出了他注册Twitter以来的第三次评论:

这应该能让硅谷的独角兽们生成更好的英语了。
看来是读了AI编的独角兽新闻报道有感。

DeepMind研究员、星际AI AlphaStar的主要爸爸Oriol Vinyals也大肆赞美了同行:
规模化+计算力,深度学习不会让人失望。恭喜Alec Radford、Ilya Sutskever等等!
由于AI生成的假消息太过真实,OpenAI的开源动作也变得十分谨慎。与以往不同,这一次开源的内容,没有完整的预训练模型,只放出了一个1.17亿参数的“缩小版”。
媒体也纷纷认为,GPT-2是个危险的存在:

来自The Verge
如果所托非人,GPT2便会成为一台挖掘机,挖出无尽的痛苦和仇恨。
而且,造假新闻只是GPT-2的冰山一角,你想要的技能它都有。
在不需要对任何其他任务进行针对性训练的情况下,GPT-2还能完成阅读理解、常识推理、文字预测、文章总结等多种任务,效果好到让人怀疑:这个模型后面单怕藏着一位语文老师吧!
语言模型全能王
这位N项全能的“语文老师”,就是“语言建模”(language modeling)。
OpenAI的研究人员表示,在各种特定领域数据集的语言建模测试中,GPT-2都取得了优异的分数。作为一个没有经过任何领域数据专门训练的模型,它的表现,比那些专为特定领域打造的模型还要好。
下图为研究人员统计的不同类型任务的成绩对比图,其中,(+)表示此领域得分越高越好,(-)表示此领域得分越低越好:

△ GPT-2在不同语言建模任务上的测试结果(从左到右:数据集名称、指标类型、GPT-2测试结果、此前比较好的结果、人类水平)
除了能用于语言建模,GPT-2在问答、阅读理解、摘要生成、翻译等等任务上,无需微调就能去的非常好的成绩。
从人类的感官角度来评判,GPT-2的效果也出奇得好。
不信?不信一起来考考它。
第一题(阅读理解):一篇让小学四年级学生卡了半天的阅读理解
阅读下列材料回答问题:
3月24日,火炬在希腊奥林匹亚奥林匹克运动会的发源地点燃后,将传递至雅典的帕纳辛奈科体育场,并于3月31日传递至北京。从北京开始,火炬将经过六大洲,途经丝绸之路沿线的城市。此次接力还会将火炬送上珠穆朗玛峰,这是接力的最后一站。
- 问题1:接力从哪里开始?
- 问题2:这个地方有什么值得注意的吗?
- 问题3:这场接力进行了多少天了?
- 问题4:他们有没有访问过任何著名的地标?
这样一段考验对时政、地理和生词理解能力的阅读理解,一个成年人认真读下来尚且还需要转换思维多思考一番,但对GPT-2来说,找出正确答案是分分钟的事:
希腊奥林匹亚;是奥林匹克运动会的发源地;七天;帕纳辛奈科体育场。
第一题:全对✅
第二题(常识推理):容易让人摸不着头脑的模糊代词
阅读下面句子,回答“它”指代的部分:
1、奖杯放不进棕色旅行箱,因为它太大了。
2、奖杯放不进棕色手提箱,因为它太小了
5秒思考,请作答。
这两句“含糊不清”的句子并没有难到GPT-2,它的答案分别为奖杯、行李箱。
第二题,没毛病✅。
第三题(文章总结):考试中让中学生头大的主旨概括
阅读下类材料,概括文章内容。
(这份材料来自外媒Daily Mail的一篇报道,全文字图交杂,Word粗略统计共1300多字。文章篇幅限制,量子位在这里把材料“阉割”了)
36000年前,史前人类在现代法国一个洞穴的粗糙石灰岩墙壁上勾勒出了一系列令人难以置信的史前野兽……(省略若干字)…………现在,在先进技术的帮助下,Chauvet-Pont-d’Arc洞穴的艺术作品被复制,创造了世界超大的复制洞穴。

不错,一段看起来就“很阅读理解”的朴素文风,GPT-2的处理情况如何?还不错:
位于法国南部Vallon-Pont-D’arc的原始遗址是联合国教科文组织世界遗产,是已知最古老、保存最完好的人类装饰洞穴。复制洞穴距离法国南部Vallon-Pont-D’Arc的原址几英里,洞穴内包含14种不同动物的图像,包括长毛犀,猛犸象和大型猫科动物。
第三题,非常好✅
怎么样,感受到GPT-2的威力了么?关于GPT-2做题的例子还有很多,文末的OpenAI博客原文,还可以查看更多。
它是怎么做的?
GPT-2,是GPT的“进化版”,比较大区别就在于规模大小。OpenAI在官方博客中表示,两者相比,GPT-2的参数扩大10倍,达到了15亿个,数据量扩大10倍,使用了包含800万个网页的数据集,共有40GB。
但在很大程度上,模型还是和GPT一样:
使用语言建模作为训练信号,以无监督的方式在大型数据集上训练一个Transformer,然后在更小的监督数据集上微调这个模型,以帮助它解决特定任务。
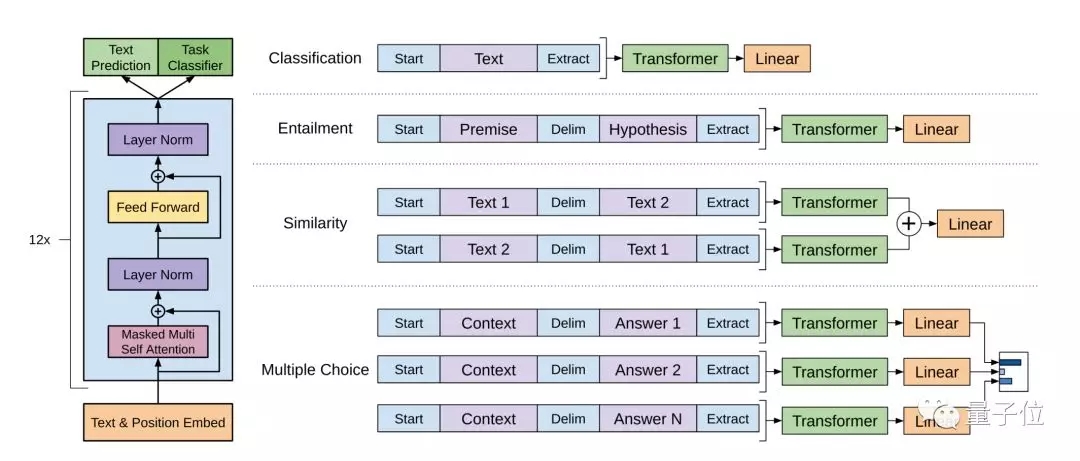
△GPT模型
上图左部分,是研究中使用的Transformer架构以及训练目标。右边部分,是针对特定任务进行微调。
将所有结构化输入转换为token序列,由预训练模型处理,然后经过线性+softmax层处理。
就GPT-2而言,它的训练目标很简单:根据所有给定文本中前面的单词,预测下一个单词。
由于训练数据集的多样性,使得这个目标非常简单的模型,具备了解决不同领域各种问题的能力。
一把双刃剑
显然,GPT-2这样一个强大的通用模型,会带来巨大的社会影响。
比如,它能用于开发AI写作助理、更强大的语音助手、提高不同语言之间无监督翻译的性能,甚至构建更好的语音识别系统。
但同样,它同样也能用来干坏事,就像用图像合成的研究造假一样, 比如deepfake,让多少人苦不堪言。
GPT-2可以用来生成具有误导性的新闻报道、自动生成垃圾邮件、伪造内容发布到社交媒体上等等等等。
这个研究,加上先前图像、音频、视频合成与生成的研究,能够大幅度降低制作虚假内容的成本。
以后你在网络上看到的东西,是真是假,可能就很难分辨了。
为了避免这种情况发生,OpenAI表示,不会发布经过训练的模型,为了能够让更多的研究人员进行试验,发布了一个更小的模型以及技术论文。
这个“防止恶意应用,不开放完整模型”的决定也引来了不少质疑。
其中最激烈的,来自英伟达研究负责人Anima Anandkumar。
她说:“Malicious BS”。大致相当于中文的“恶意个P”。
这位Anima,曾经逼得顶会NIPS改了名,正面硬刚Yann LeCun,最近在呼吁学术会议强制投稿者公开源代码。
不愿开放完整模型的OpenAI,被Anima斥责“为了站道德高地本末倒置”,站在了open的对立面,传播恐惧、误导媒体。
你怎么看?
无论观点如何,如果你对这项研究感兴趣,请先收好传送门:
模型代码:
https://github.com/openai/gpt-2
技术论文:
Language Models are Unsupervised Multitask Learners
这项研究的作者分别是Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever。

其中Ilya Sutskever是OpenAI的首席科学家,是AlexNet、seq2seq、AlphaGo、TensorFlow等人工智能领域重要成果的共同创造者。
论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
最后,附上AI撰写的关于独角兽的全文:
(人类给的开头:)
科学家们有个令人震惊的发现,在安第斯山脉一个偏远且没被开发过的山谷里,生活着一群独角兽。更加让人讶异的是,这些独角兽说着流利的英文。
(AI编的下文:)
这些生物长着独特的角,科学家们就以此为它们命名,叫Ovid’s Unicorn。长着四只角的银白色生物,在这之前并不为科学界所知。
现在,过了近两个世纪,这个奇异的现象到底是怎么发现的,谜底终于解开了。
来自拉巴斯大学的进化生物学教授Jorge Pérez和他的几个小伙伴,在探索安第斯山脉的时候发现了一个小山谷,没有其他动物也没有人类。
Pérez注意到,这山谷看上去曾是个喷泉的所在,旁边是两座石峰,上面有银白的雪。
然后,Pérez他们就深入探寻这个山谷。“我们爬上其中一座山峰的时候,下面的水很蓝,上面还有一些结晶。”Pérez说。
发现独角兽种群的时候,Pérez和他的小伙伴都惊呆了。都不用靠近,从高空就可以望见这些生物——看上去离得很近,就快摸到它们的角了。
在查看这些奇怪生物的时候,科学家们发现它们讲着普通的英文。Pérez说:“比如说,我们注意到,它们有一种共同‘语言’,有点接近方言。”
Pérez认为,这些独角兽起源于阿根廷。在那里,人们相信这些动物是一个消失种族的后裔,在人类到达之前,这个种族就生活在那里。
虽然,这些生物的起源还不清楚,但有些人相信,它们是一个人类和一个独角兽相交而诞生的,那时人类文明还不存在。Pérez说:“在南美洲,这样的事情是很常见的。”
然而,Pérez也指出,要确认它们是不是那个消失种族的后裔,DNA检测可能是非常有效的方法。“不过,它们看上去能用英语交流,我相信这也是一种进化的信号,或者至少也是社会组织的一种变化。”他说。