【51CTO.com快译】1. 引言
文本摘要是自然语言处理(NLP)领域中的应用之一,它必将对我们的生活产生巨大影响。随着数字媒体和出 版业的不断发展,谁还有时间浏览整篇文章/文档/书籍来决定它们是否有用?值得庆幸的是 - 我们已经有了 文本摘要技术。
您是否用过一款名为 inshorts 的移动 APP?这是一个非常有创意的新闻 APP,能将新闻文章转换为 60 字的 摘要。这正是我们将在本文中学习的内容 - 自动文本摘要。

自动文本摘要是自然语言处理(NLP)领域中***挑战性和最有趣的问题之一。这是一个从多种文本资源(如 书籍,新闻文章,博客文章,研究论文,电子邮件和推文)生成简明而有意义的文本摘要的过程。
由于我们面临着大量的文本数据,近来对自动文本摘要系统的需求十分惊人。
通过本文,我们将探讨文本摘要所涉及的领域,了解 TextRank 算法的工作原理,并用 Python 实现该算法。
2. 文本摘要方法
自动文本摘要早在 20 世纪 50 年代就引起了人们的关注。由 Hans Peter Luhn 在 20 世纪 50 年代末出版的题 为“文学摘要的自动创建”的研究论文,使用词频和短语频率等特征从文本中提取重要句子以概括文章。
Harold P Edmundson 在 1960 年代后期进行的另一项重要研究使用了诸如句中是否包含关键词、文本中是否 出现标题所含单词以及句子在文本中的位置等方法提取重要句子来生成文本摘要。从那时起,许多重要且令 人兴奋的研究陆续发表,以应对自动文本摘要领域的挑战。
文本摘要大致可以分为两类 - 抽取摘要和抽象摘要。
- 抽取摘要:这些方法依赖于从一段文本中提取几个部分,例如短语和句子,并将它们堆叠在一起以创建 摘要。因此,在提取方法中识别正确的摘要句子是至关重要的。
- 抽象摘要:这些方法使用高级 NLP 技术生成全新的摘要。这些摘要的某些部分甚至可能没有在原始文 本中出现。
在本文中,我们将重点介绍抽取摘要技术。
3. 理解 TextRank 算法
在开始使用 TextRank 算法之前,我们应该了解另一种算法 - PageRank 算法。事实上,TextRank 算法也是 在此基础上开发的!PageRank 主要用于在网页搜索结果中对网页进行排名。让我们借助一个例子快速理解这 个算法的基础知识。
3.1. PageRank 算法
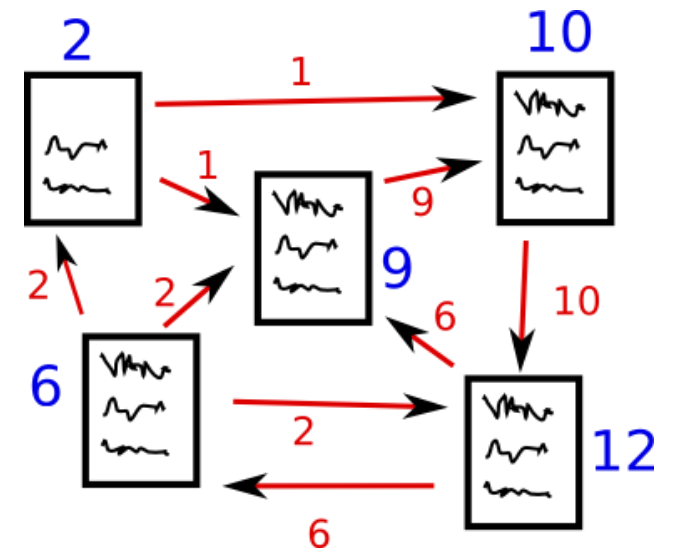
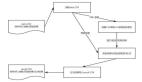
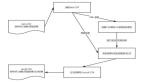
假设我们有 4 个网页 - w1,w2,w3 和 w4。这些网页包含指向其它网页的链接。但其中有些页面可能没有指 向其它网页的链接 - 这些网页被称为悬空页面(dangling pages)。
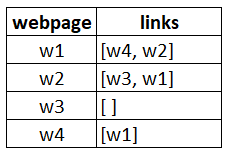
- 网页 w1 有指向网页 w2 和 w4 的链接
- 网页 w2 有指向网页 w3 和 w1 的链接
- 网页 w4 有指向网页 w1 的链接
- 网页 w3 没有指向其它网页的链接,因此它是一个悬空网页(dangling page)
为了对这些页面进行排名,我们必须计算一个称为 PageRank score 的分数。该分数是用户访问该页面的概率。 为了获得用户从一个页面跳转到另一个页面的概率,我们创建一个 n 行 n 列的方阵 M,其中 n 是网页的数量。
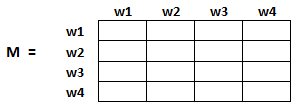
该矩阵的每个元素表示用户从一个网页跳转到另一个网页的概率。例如,下图高亮的单元格表示从网页 w1 跳 转到网页 w2 的概率。
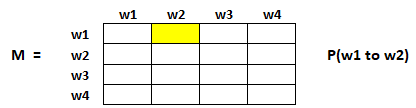
网页跳转概率的初始化方法如下:
- 从页面 i 跳转到页面 j 的概率,即 M[i][j] ,用 1 /(网页 wi 中的不重复的总链接数)初始化
- 如果页面 i 和 j 之间没有链接,则概率将初始化为 0
- 如果用户访问的是悬空页面,则假设他跳转到其它任何页面的概率都相等。因此,M[i][j] 将用 1 /(网 页总数)初始化
因此,在我们的例子中,矩阵 M 将初始化如下:
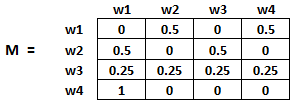
该矩阵中的值将不断迭代更新,以进行***的网页排名。
4. TextRank 算法
在掌握了 PageRank 算法的基本思想后,现在让我们来理解 TextRank 算法吧。我将两种算法之间的关联列 出如下:
- 我们将研究的是句子,而不再是网页
- 两个句子之间的相似度可以理解成网页之间的跳转概率
- 句子间的相似度得分存储在方阵中,类似于 PageRank 算法中的方阵 M
TextRank 算法是一种基于抽取和无监督的文本摘要技术。让我们来看看 TextRank 算法的流程:
- ***步是获取文章中包含的所有文本。
- 然后将文本拆分成单个句子。
- 下一步是,找到每个句子的向量表示。
- 然后计算句子向量之间的相似度并将其存储在矩阵中。 5. 然后将相似度矩阵转换成图,其中图中顶点表示句子,图中边表示句子间的相似度,用于后续句子排名 的计算。
- ***,最终摘要中包含排名***的几个句子。 所以,不用多说,让我们启动 Jupyter Notebook 开始编码吧! 注意:如果您想学习有关 Graph Theory 的更多内容,那么我建议您查看这篇文章。
5. 问题描述
作为一个网球爱好者,我总是通过阅读尽可能多的有关网球的在线文章来让自己了解网球运动中最近发生的 事情。然而,事实证明这是一项相当困难的工作!因为网上的资源太多但是我的时间却相当有限。
因此,我决定设计一个系统,可以通过扫描多篇文章然后为我提供一份文章摘要。怎样去做这件事?这就是我 将在本教程中向您展示的内容。我们将在一份网球文本数据集上运用 TextRank 算法,目标是为这些文本创 建一个简洁明了的摘要。
请注意,这实际上是一个单领域多文档的摘要任务,即我们将多篇文章作为输入并生成单个目标主题的摘要。 本文不涉及多领域文本摘要,但您可以自己去了解相关内容。
您可以从此处下载我们将使用的数据集。
6. TextRank 算法的实现
让我们打开 Jupyter Notebooks,将刚才学到的东西实现出来吧。
6.1. 导入必要的库
首先我们需要导入一些将要使用的库:
- import numpy as np
- import pandas as pd
- import nltk
- nltk.download('punkt') # one time execution
- import re
6.2. 读入数据
现在需要读入数据集,我在前一个部分提供了该数据集的下载链接 (防止你没有看见它)
- df = pd.read_csv("tennis_articles_v4.csv")
6.3. 查看数据
我们快速浏览一下数据的大致样子吧。
- df.head()

该数据集包含 3 列:“article_id”,“article_text”和“source”。我们对‘article_text’列最感兴趣,因为它包 含文章的文本。我们可以打印出变量的一些值,看看它们的样子。
- df['article_text'][0]
输出:
- "Maria Sharapova has basically no friends as tennis players on the WTA Tour. The Russian player has no problems in openly speaking about it and in a recent interview she said: 'I don't really hide any feelings too much. I think everyone knows this is my job here. When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net...
- df['article_text'][1]
输出:
- BASEL, Switzerland (AP), Roger Federer advanced to the 14th Swiss Indoors final of his career by beating seventh-seeded Daniil Medvedev 6-1, 6-4 on Saturday. Seeking a ninth title at his hometown event, and a 99th overall, Federer will play 93th-ranked Marius Copil on Sunday. Federer dominated the 20th-ranked Medvedev and had his first match-point chance to break serve again at 5-1...
现在我们有两个选择:我们可以单独为每篇文章生成一个摘要,也可以为所有文章生成一个摘要。考虑我们的 问题需求,我们将做后者。
6.4. 将文本分成句子
接下来的步骤是将文本分成单个的句子,我们可以使用 nltk 库中的 sent_tokenize() 函数。
- from nltk.tokenize import sent_tokenize
- sentences = []
- for s in df['article_text']:
- sentences.append(sent_tokenize(s))
- sentences = [y for x in sentences for y in x] # flatten list
我们打印出 sentences 列表的一些元素:
- sentences[:5]
输出:
- ['Maria Sharapova has basically no friends as tennis players on the WTA Tour.', "The Russian player has no problems in openly speaking about it and in a recent interview she said: 'I don't really hide any feelings too much.", 'I think everyone knows this is my job here.', "When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match.", "I'm a pretty competitive girl."]
6.5. 下载 GloVe 词向量
GloVe 词向量是单词的向量表示。这些单词向量将用于后续创建句子向量。我们也可以使用 Bag-of-Words 或 TF-IDF 方法为我们的句子创建特征,但是这些方法忽略了单词的顺序(并且特征的数量通常非常大)。
我们将使用此处提供的预训练的 Wikipedia 2014 + Gigaword 5 GloVe 向量。注意,这些词向量的大小为 822 MB。
- !wget http://nlp.stanford.edu/data/glove.6B.zip
- !unzip glove*.zip
我们需要提取出词向量:
- # Extract word vectors
- word_embeddings = {}
- f = open('glove.6B.100d.txt', encoding='utf-8')
- for line in f:
- values = line.split()
- word = values[0]
- coefs = np.asarray(values[1:], dtype='float32')
- word_embeddings[word] = coefs
- f.close()
- len(word_embeddings)
输出:
- 400000
我们现在已经有了词典中包含的 400000 个单词的词向量了。
6.6. 文本预处理
尽可能使文本数据没有噪音始终是一种很好的做法。所以,让我们做一些基本的文本清理工作。
- # remove punctuations, numbers and special characters
- clean_sentences = pd.Series(sentences).str.replace("[^a-zA-Z]", " ")
- # make alphabets lowercase
- clean_sentences = [s.lower() for s in clean_sentences]
去除停用词(停用词是一种语言中最常用的一些词, 像英文中的 am, the, of, in 等)。如果您还没有下载 nltkstopwords,请执行以下代码:
- nltk.download('stopwords')
现在导入停用词列表:
- from nltk.corpus import stopwords
- stop_words = stopwords.words('english')
定义一个函数用于从我们的数据集中去除停用词。
- # function to remove stopwords
- def remove_stopwords(sen):
- sen_new = " ".join([i for i in sen if i not in stop_words])
- return sen_new
- # remove stopwords from the sentences
- clean_sentences = [remove_stopwords(r.split()) for r in clean_sentences]
在 GloVe 词向量的帮助下,我们将使用 clean_sentences 为我们数据中的句子创建向量。
6.7. 句子的向量表示
- # Extract word vectors
- word_embeddings = {}
- f = open('glove.6B.100d.txt', encoding='utf-8')
- for line in f:
- values = line.split()
- word = values[0]
- coefs = np.asarray(values[1:], dtype='float32')
- word_embeddings[word] = coefs
- f.close()
现在,让我们为句子创建向量表示。我们将首先获取组成句子的所有单词的向量(每个向量为 100 维),然后 取这些向量的平均值来得到句子的向量。
- sentence_vectors = []
- for i in clean_sentences:
- if len(i) != 0:
- v = sum([word_embeddings.get(w, np.zeros((100,))) for w in i.split()])/(len(i.split())+0.001)
- else:
- v = np.zeros((100,))
- sentence_vectors.append(v)
6.8. 准备相似度矩阵
下一步是计算句子之间的相似度,我们将使用余弦相似度(cosine similarity)方法来计算句子向量间的相似 度。
让我们首先定义维度为(n * n)的零矩阵。然后使用句子的余弦相似度分数初始化该矩阵。这里,n 是句子 数。
- # similarity matrix
- sim_mat = np.zeros([len(sentences), len(sentences)])
- from sklearn.metrics.pairwise import cosine_similarity
- for i in range(len(sentences)):
- for j in range(len(sentences)):
- if i != j:
- sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,100), sentence_vectors[j].reshape(1,100))[0,0]
6.9. 应用 PageRank 算法
在继续下一步之前,需要将相似度矩阵转换为图,图中的顶点表示句子,边表示句子间的相似度分数。我们将 在这张图上应用 PageRank 算法来进行句子的排名。
- import networkx as nx
- nx_graph = nx.from_numpy_array(sim_mat)
- scores = nx.pagerank(nx_graph)
6.10. 摘要抽取
***,从生成的摘要中抽取出排名前 N 的句子。
- ranked_sentences = sorted(((scores[i],s)
- for i,s in enumerate(sentences)), reverse=True)
- # Extract top 10 sentences as the summary
- for i in range(10):
- print(ranked_sentences[i][1])
输出:
- When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the weather and know that in the next few minutes I have to go and try to win a tennis match.
- Major players feel that a big event in late November combined with one in January before the Australian Open will mean too much tennis and too little rest.
- Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of any commitment.
- "I felt like the best weeks that I had to get to know players when I was playing were the Fed Cup weeks or the Olympic weeks, not necessarily during the tournaments.
- Currently in ninth place, Nishikori with a win could move to within 125 points of the cut for the eight-man event in London next month.
- He used his first break point to close out the first set before going up 3-0 in the second and wrapping up the win on his first match point. The Spaniard broke Anderson twice in the second but didn't get another chance on the South African's serve in the final set.
- "We also had the impression that at this stage it might be better to play matches than to train.
- The competition is set to feature 18 countries in the November 18-24 finals in Madrid next year, and will replace the classic home-and-away ties played four times per year for decades.
- Federer said earlier this month in Shanghai in that his chances of playing the Davis Cup were all but non-existent.
这样,我们就得到了想要的文本摘要的结果。
7. What’s Next?
自动文本摘要是研究的热门话题,我们在本文只讨论了冰山一角。展望未来,我们将探索深度学习在其中起着 重要作用的抽象文本摘要技术。此外,我们还可以研究以下摘要任务:
1. 特定问题的摘要任务
- 多领域文本摘要
- 单文档摘要
- 跨语言文本摘要(输入是某种语言,生成另一种语言的摘要)
2. 特定算法的摘要任务:
- 使用 RNN 和 LSTM 网络的文本摘要
- 使用增强学习的文本摘要
- 使用对抗生成网络(GAN)的文本摘要
8. 结语
我希望这篇文章能帮助您理解自动文本摘要的概念。它有各种各样的用例,并有人用此做出了非常成功的应 用程序。无论是出于商业的考虑,还是仅仅出于学习知识的考虑,文本摘要技术都应是 NLP 爱好者们应该熟 悉的方法。
我将在以后的文章中尝试使用高级技术来介绍抽象文本摘要技术。以上代码可以在此Github中找到。
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】