前些日子小组内安排值班,轮流看顾我们的服务,主要做一些报警邮件处理、Bug排查、运营issue处理的事。工作日还好,无论干什么都要上班的,若是轮到周末,那这一天算是毁了。
不知道是公司网络广了就这样还是网络运维组不给力,网络总有问题,不是这边交换机脱网了,就是那边路由器坏了,还偶发地各种超时,而我们灵敏地服务探测服务总能准确地抓住偶现的小问题,给美好的工作加点料。
好几次值班组的小伙伴们一起吐槽,商量着怎么避过服务保活机制,偷偷停了探测服务而不让人发现(虽然也并不敢)。
前些天我就在周末处理了一次探测服务的锅。本文会持续修订,大家可以继续关注。
一、问题
网络问题?
晚上七点多开始,我就开始不停地收到报警邮件,邮件显示探测的几个接口有超时情况。 多数执行栈都在:
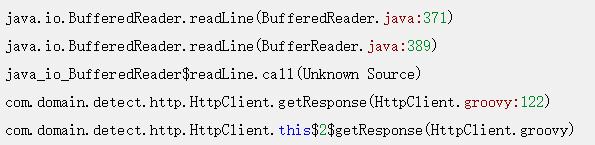
这个线程栈的报错我见得多了,我们设置的HTTP DNS超时是1s,connect超时是2s,read超时是3s,这种报错都是探测服务正常发送了HTTP请求,服务器也在收到请求正常处理后正常响应了,但数据包在网络层层转发中丢失了,所以请求线程的执行栈会停留在获取接口响应的地方。
这种情况的典型特征就是能在服务器上查找到对应的日志记录。而且日志会显示服务器响应完全正常。与它相对的还有线程栈停留在Socket connect处的,这是在建连时就失败了,服务端完全无感知。
我注意到其中一个接口报错更频繁一些,这个接口需要上传一个4M的文件到服务器,然后经过一连串的业务逻辑处理,再返回2M的文本数据,而其他的接口则是简单的业务逻辑,我猜测可能是需要上传下载的数据太多,所以超时导致丢包的概率也更大吧。
根据这个猜想,群登上服务器,使用请求的request_id在近期服务日志中搜索一下,果不其然,就是网络丢包问题导致的接口超时了。
当然这样leader是不会满意的,这个结论还得有人接锅才行。于是赶紧联系运维和网络组,向他们确认一下当时的网络状态。网络组同学回复说是我们探测服务所在机房的交换机老旧,存在未知的转发瓶颈,正在优化,这让我更放心了,于是在部门群里简单交待一下,算是完成任务。
问题爆发
本以为这次值班就起这么一个小波浪,结果在晚上八点多,各种接口的报警邮件蜂拥而至,打得准备收拾东西过周日单休的我措手不及。
这次几乎所有的接口都在超时,而我们那个大量网络I/O的接口则是每次探测必超时,难道是整个机房故障了么?
我再次通过服务器和监控看到各个接口的指标都很正常,自己测试了下接口也完全OK,既然不影响线上服务,我准备先通过探测服务的接口把探测任务停掉再慢慢排查。
结果给暂停探测任务的接口发请求好久也没有响应,这时候我才知道没这么简单。
二、解决
内存泄漏
于是赶快登陆探测服务器,首先是top free df三连,结果还真发现了些异常。

我们的探测进程CPU占用率特别高,达到了900%。
我们的Java进程,并不做大量CPU运算,正常情况下,CPU应该在100~200%之间,出现这种CPU飙升的情况,要么走到了死循环,要么就是在做大量的GC。
使用jstat -gc pid [interval]命令查看了java进程的GC状态,果然,FULL GC达到了每秒一次。

这么多的FULL GC,应该是内存泄漏没跑了,于是使用jstack pid > jstack.log保存了线程栈的现场,使用jmap -dump:format=b,file=heap.log pid保存了堆现场,然后重启了探测服务,报警邮件终于停止了。
jstat
jstat是一个非常强大的JVM监控工具,一般用法是:jstat [-options] pid interval
它支持的查看项有:
class查看类加载信息
compile编译统计信息
gc垃圾回收信息
gcXXX各区域GC的详细信息,如-gcold
使用它,对定位JVM的内存问题很有帮助。
三、排查
问题虽然解决了,但为了防止它再次发生,还是要把根源揪出来。
分析栈
栈的分析很简单,看一下线程数是不是过多,多数栈都在干嘛。

才四百多线程,并无异常。

线程状态好像也无异常,接下来分析堆文件。
下载堆dump文件
堆文件都是一些二进制数据,在命令行查看非常麻烦,Java为我们提供的工具都是可视化的,Linux服务器上又没法查看,那么首先要把文件下载到本地。
由于我们设置的堆内存为4G,所以dump出来的堆文件也很大,下载它确实非常费事,不过我们可以先对它进行一次压缩。
gzip是个功能很强大的压缩命令,特别是我们可以设置-1~-9来指定它的压缩级别,数据越大压缩比率越大,耗时也就越长,推荐使用-6~7,-9实在是太慢了,且收益不大,有这个压缩的时间,多出来的文件也下载好了。
使用MAT分析jvm heap
MAT是分析Java堆内存的利器,使用它打开我们的堆文件(将文件后缀改为 .hprof), 它会提示我们要分析的种类,对于这次分析,果断选择memory leak suspect。

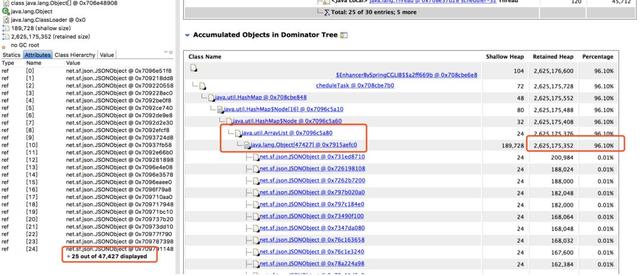
从上面的饼图中可以看出,绝大多数堆内存都被同一个内存占用了,再查看堆内存详情,向上层追溯,很快就发现了罪魁祸首。
分析代码
找到内存泄漏的对象了,在项目里全局搜索对象名,它是一个Bean对象,然后定位到它的一个类型为Map的属性。
这个Map根据类型用ArrayList存储了每次探测接口响应的结果,每次探测完都塞到ArrayList里去分析,由于Bean对象不会被回收,这个属性又没有清除逻辑,所以在服务十来天没有上线重启的情况下,这个Map越来越大,直至将内存占满。
内存满了之后,无法再给HTTP响应结果分配内存了,所以一直卡在readLine那。而我们那个大量I/O的接口报警次数特别多,估计跟响应太大需要更多内存有关。
给代码owner提了PR,问题圆满解决。
四、小结
其实还是要反省一下自己的,一开始报警邮件里还有这样的线程栈:

看到这种报错线程栈却没有细想,要知道TCP是能保证消息完整性的,况且消息没有接收完也不会把值赋给变量,这种很明显的是内部错误,如果留意后细查是能提前查出问题所在的,查问题真是差了哪一环都不行啊。