AI作为2016年以来最热门的词汇,人们对之也持有不同的看法:有人在怀疑泡沫即将破裂、有人坚信这场变革会带来巨大的机会、有人抛出威胁论。
本系列试图以通俗易懂的方式,让不同知识水平的读者都能从中获益:让外行人对人工智能有一个清晰客观的理解,也帮助内行人更好地参与到AI带来这场产业变革中来。
本文将会从AI最基本的几个模块(计算机视觉、语音识别、自然语言处理、决策规划系统)着手,回顾其一路以来的发展脉络,以史为镜、正视未来。
1. 计算机视觉的发展历史
“看”是人类与生俱来的能力。刚出生的婴儿只需要几天的时间就能学会模仿父母的表情,人们能从复杂结构的图片中找到关注重点、在昏暗的环境下认出熟人。随着人工智能的发展,机器也试图在这项能力上匹敌甚至超越人类。
计算机视觉的历史可以追溯到1966年,人工智能学家Minsky在给学生布置的作业中,要求学生通过编写一个程序让计算机告诉我们它通过摄像头看到了什么,这也被认为是计算机视觉最早的任务描述。
到了七八十年代,随着现代电子计算机的出现,计算机视觉技术也初步萌芽。人们开始尝试让计算机回答出它看到了什么东西,于是首先想到的是从人类看东西的方法中获得借鉴。
- 借鉴之一是当时人们普遍认为,人类能看到并理解事物,是因为人类通过两只眼睛可以立体地观察事物。因此要想让计算机理解它所看到的图像,必须先将事物的三维结构从二维的图像中恢复出来,这就是所谓的“三维重构”的方法。
- 借鉴之二是人们认为人之所以能识别出一个苹果,是因为人们已经知道了苹果的先验知识,比如苹果是红色的、圆的、表面光滑的,如果给机器也建立一个这样的知识库,让机器将看到的图像与库里的储备知识进行匹配,是否可以让机器识别乃至理解它所看到的东西呢,这是所谓的“先验知识库”的方法。
这一阶段的应用主要是一些光学字符识别、工件识别、显微/航空图片的识别等等。
到了九十年代,计算机视觉技术取得了更大的发展,也开始广泛应用于工业领域。一方面原因是CPU、DSP等图像处理硬件技术有了飞速进步;另一方面是人们也开始尝试不同的算法,包括统计方法和局部特征描述符的引入。
在“先验知识库”的方法中,事物的形状、颜色、表面纹理等特征是受到视角和观察环境所影响的,在不同角度、不同光线、不同遮挡的情况下会产生变化。
因此,人们找到了一种方法,通过局部特征的识别来判断事物,通过对事物建立一个局部特征索引,即使视角或观察环境发生变化,也能比较准确地匹配上。

进入21世纪,得益于互联网兴起和数码相机出现带来的海量数据,加之机器学习方法的广泛应用,计算机视觉发展迅速。以往许多基于规则的处理方式,都被机器学习所替代,自动从海量数据中总结归纳物体的特征,然后进行识别和判断。
这一阶段涌现出了非常多的应用,包括典型的相机人脸检测、安防人脸识别、车牌识别等等。
数据的积累还诞生了许多评测数据集,比如权威的人脸识别和人脸比对识别的平台——FDDB和LFW等,其中最有影响力的是ImageNet,包含1400万张已标注的图片,划分在上万个类别里。
到了2010年以后,借助于深度学习的力量,计算机视觉技术得到了爆发增长和产业化。通过深度神经网络,各类视觉相关任务的识别精度都得到了大幅提升。
在全球最权威的计算机视觉竞赛ILSVR
(ImageNet Large Scale VisualRecognition Competition)上,千类物体识别Top-5错误率在2010年和2011年时分别为28.2%和25.8%,从2012年引入深度学习之后,后续4年分别为16.4%、11.7%、6.7%、3.7%,出现了显著突破。
由于效果的提升,计算机视觉技术的应用场景也快速扩展,除了在比较成熟的安防领域应用外,也有应用在金融领域的人脸识别身份验证、电商领域的商品拍照搜索、医疗领域的智能影像诊断、机器人/无人车上作为视觉输入系统等,包括许多有意思的场景:照片自动分类(图像识别+分类)、图像描述生成(图像识别+理解)等等。

2. 语音技术的发展历史
语言交流是人类最直接最简洁的交流方式。长久以来,让机器学会“听”和“说”,实现与人类间的无障碍交流一直是人工智能、人机交互领域的一大梦想。
早在电子计算机出现之前,人们就有了让机器识别语音的梦想。1920年生产的“Radio Rex”玩具狗可能是世界上最早的语音识别器,当有人喊“Rex”的时候,这只狗能够从底座上弹出来。
但实际上它所用到的技术并不是真正的语音识别,而是通过一个弹簧,这个弹簧在接收到500赫兹的声音时会自动释放,而500赫兹恰好是人们喊出“Rex”中元音的第一个共振峰。
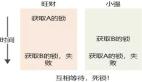
第一个真正基于电子计算机的语音识别系统出现在1952年,AT&T贝尔实验室开发了一款名为Audrey的语音识别系统,能够识别10个英文数字,正确率高达98%。
70年代开始出现了大规模的语音识别研究,但当时的技术还处于萌芽阶段,停留在对孤立词、小词汇量句子的识别上。
上世纪80年代是技术取得突破的时代,一个重要原因是全球性的电传业务积累了大量文本,这些文本可作为机读语料用于模型的训练和统计。研究的重点也逐渐转向大词汇量、非特定人的连续语音识别。
那时最主要的变化来自用基于统计的思路替代传统基于匹配的思路,其中的一个关键进展是隐马尔科夫模型(HMM)的理论和应用都趋于完善。
工业界也出现了广泛的应用,德州仪器研发了名为Speak& Spell语音学习机,语音识别服务商Speech Works成立,美国国防部高级研究计划局(DARPA)也赞助支持了一系列语音相关的项目。
90年代是语音识别基本成熟的时期,主流的高斯混合模型GMM-HMM框架逐渐趋于稳定,但识别效果与真正实用还有一定距离,语音识别研究的进展也逐渐趋缓。
由于80年代末、90年代初神经网络技术的热潮,神经网络技术也被用于语音识别,提出了多层感知器-隐马尔科夫模型(MLP-HMM)混合模型。但是性能上无法超越GMM-HMM框架。
突破的产生始于深度学习的出现。随着深度神经网络(DNN)被应用到语音的声学建模中,人们陆续在音素识别任务和大词汇量连续语音识别任务上取得突破。
基于GMM-HMM的语音识别框架被基于DNN-HMM的语音识别系统所替代,而随着系统的持续改进,又出现了深层卷积神经网络和引入长短时记忆模块(LSTM)的循环神经网络(RNN),识别效果得到了进一步提升,在许多(尤其是近场)语音识别任务上达到了可以进入人们日常生活的标准。
于是我们看到以Apple Siri为首的智能语音助手、以Echo为首的智能硬件入口等等。
而这些应用的普及,又进一步扩充了语料资源的收集渠道,为语言和声学模型的训练储备了丰富的燃料,使得构建大规模通用语言模型和声学模型成为可能。
3. 自然语言处理的发展历史
人类的日常社会活动中,语言交流是不同个体间信息交换和沟通的重要途径。因此,对机器而言,能否自然地与人类进行交流、理解人们表达的意思并作出合适的回应,被认为是衡量其智能程度的一个重要参照,自然语言处理也因此成为了绕不开的议题。
早在上世纪50年代,随着电子计算机的出现,出现了许多自然语言处理的任务需求,其中最典型的就是机器翻译。
当时存在两派不同的自然语言处理方法:基于规则方法的符号派和基于概率方法的随机派。受限于当时的数据和算力,随机派无法发挥出全部的功力,使得规则派的研究略占上风。
体现到翻译上,人们认为机器翻译的过程是在解读密码,试图通过查询词典来实现逐词翻译,这种方式产出的翻译效果不佳、难以实用。
当时的一些成果包括1959年宾夕法尼亚大学研制成功的TDAP系统(Transformation and Discourse Analysis Project,最早的、完整的英语自动剖析系统)、布朗美国英语语料库的建立等。
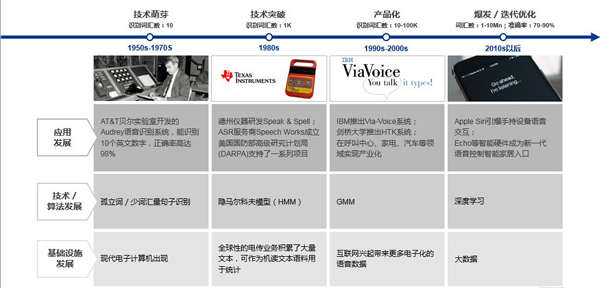
IBM-701计算机进行了世界上第一次机器翻译试验,将几个简单的俄语句子翻译成了英文。这之后苏联、英国、日本等国家也陆续进行了机器翻译试验。
1966年,美国科学院的语言自动处理咨询委员会(ALPAC),发布了一篇题为《语言与机器》的研究报告,报告全面否定了机器翻译的可行性,认为机器翻译不足以克服现有困难、投入实用。
这篇报告浇灭了之前的机器翻译热潮,许多国家开始消减在这方面的经费投入,许多相关研究被迫暂停,自然语言研究陷入低谷。
许多研究者痛定思痛,意识到两种语言间的差异不仅体现在词汇上,还体现在句法结构的差异上,为了提升译文的可读性,应该加强语言模型和语义分析的研究。
里程碑事件出现在1976 年,加拿大蒙特利尔大学与加拿大联邦政府翻译局联合开发
了名为TAUM-METEO的机器翻译系统,提供天气预报服务。这个系统每小时可以翻译6-30万个词,每天可翻译1-2千篇气象资料,并能够通过电视、报纸立即公布。
在这之后,欧盟、日本也纷纷开始研究多语言机器翻译系统,但并未取得预期的成效。
到了90年代时,自然语言处理进入了发展繁荣期。随着计算机的计算速度和存储量大幅增加、大规模真实文本的积累产生,以及被互联网发展激发出的、以网页搜索为代表的基于自然语言的信息检索和抽取需求出现,人们对自然语言处理的热情空前高涨。
在传统基于规则的处理技术中,人们引入了更多数据驱动的统计方法,将自然语言处理的研究推向了一个新高度。除了机器翻译之外,网页搜索、语音交互、对话机器人等领域都有自然语言处理的功劳。
进入2010年以后,基于大数据和浅层、深层学习技术,自然语言处理的效果得到了进一步优化。机器翻译的效果进一步提升,出现了专门的智能翻译产品。对话交互能力被应用在客服机器人、智能助手等产品中。

这一时期的一个重要里程碑事件是IBM研发的Watson系统参加综艺问答节目Jeopardy。比赛中Watson没有联网,但依靠4TB磁盘内200万页结构化和非结构化的信息,Watson成功战胜人类选手取得冠军,向世界展现了自然语言处理技术所能达到的实力。
机器翻译方面,谷歌推出的神经网络机器翻译(GNMT)相比传统的基于词组的机器翻译(PBMT),英语到西班牙语的错误率下降了87%,英文到中文的错误率下降了58%,取得了非常强劲的提升。
4. 规划决策系统的发展历史
人工智能规划决策系统的发展,一度是以棋类游戏为载体的。最早在18世纪的时候,就出现过一台可以下棋的机器,击败了当时几乎所有的人类棋手,包括拿破仑和富兰克林等。不过最终被发现机器里藏着一个人类高手,通过复杂的机器结构以混淆观众的视线,只是一场骗局而已。
真正基于人工智能的规划决策系统出现在电子计算机诞生之后,1962年,Arthur Samuel制作的西洋跳棋程序Checkers经过屡次改进后,终于战胜了州冠军。
当时的程序虽然还算不上智能,但也已经具备了初步的自我学习能力,这场胜利在当时还是引起了巨大的轰动,毕竟是机器首次在智力的角逐中战胜人类。这也让人们发出了乐观的预言:“机器将在十年内战胜人类象棋冠军”。
但人工智能所面临的困难比人们想象得要大很多,跳棋程序在此之后也败给了国家冠军,未能更上一层楼。而国际象棋相比跳棋要复杂得多,在当时的计算能力下,机器若想通过暴力计算战胜人类象棋棋手,每步棋的平均计算时长是以年为单位的。人们也意识到,只有尽可能减少计算复杂度,才可能与人类一决高下。
于是,“剪枝法”被应用到了估值函数中,通过剔除掉低可能性的走法,优化最终的估值函数计算。在“剪枝法”的作用下,西北大学开发的象棋程序Chess 4.5在1976年首次击败了顶尖人类棋手。
进入80年代,随着算法上的不断优化,机器象棋程序在关键胜负手上的判断能力和计算速度大幅提升,已经能够击败几乎所有的顶尖人类棋手。
到了90年代,硬件性能、算法能力等都得到了大幅提升,在1997年那场著名的人机大战中,IBM研发的深蓝(Deep Blue)战胜国际象棋大师卡斯帕罗夫,人类意识到在象棋游戏中已经很难战胜机器了。
到了2016年,硬件层面出现了基于GPU、TPU的并行计算,算法层面出现了蒙特卡洛决策树与深度神经网络的结合。
4:1战胜李世石、在野狐围棋对战顶尖棋手60连胜、3:0战胜世界排名第一的围棋选手柯洁,随着棋类游戏最后的堡垒——围棋也被Alpha Go所攻克,人类在完美信息博弈的游戏中已彻底输给机器,只能在不完美信息的德州扑克和麻将中苟延残喘。
人们从棋类游戏中积累的知识和经验,也被应用在更广泛的需要决策规划的领域,包括机器人控制、无人车等等。棋类游戏完成了它的历史使命,带领人工智能到达了一个新的历史起点。

5. 人工智能的现在
时至今日,人工智能的发展已经突破了一定的“阈值”。与前几次的热潮相比,这一次的人工智能来得更“实在”了,这种“实在”体现在不同垂直领域的性能提升、效率优化。计算机视觉、语音识别、自然语言处理的准确率都已不再停留在“过家家”的水平,应用场景也不再只是一个新奇的“玩具”,而是逐渐在真实的商业世界中扮演起重要的支持角色。
6. 语音处理的现在
一个完整的语音处理系统,包括前端的信号处理、中间的语音语义识别和对话管理(更多涉及自然语言处理)、以及后期的语音合成。
总体来说,随着语音技术的快速发展,之前的限定条件正在不断减少:包括从小词汇量到大词汇量再到超大词汇量、从限定语境到弹性语境再到任意语境、从安静环境到近场环境再到远场嘈杂环境、从朗读环境到口语环境再到任意对话环境、从单语种到多语种再到多语种混杂,但这给语音处理提出了更高的要求。
语音的前端处理中包含几个模块。
- 说话人声检测:有效地检测说话人声开始和结束时刻, 区分说话人声与背景声;
- 回声消除:当音箱在播放音乐时,为了不暂停音乐而进行有效的语音识别,需要消除来自扬声器的音乐干扰;
- 唤醒词识别:人类与机器交流的触发方式,就像日常生活中需要与其他人说话时,你会先喊一下那个人的名字;
- 麦克风阵列处理:对声源进行定位,增强说话人方向的信号、抑制其他方向的噪音信号;
- 语音增强:对说话人语音区域进一步增强,、环境噪声区域进一步抑制,有效降低远场语音的衰减。
除了手持设备是近场交互外,其他许多场景——车载、智能家居等——都是远场环境。
在远场环境下,声音传达到麦克风时会衰减得非常厉害,导致一些在近场环境下不值一提的问题被显著放大。这就需要前端处理技术能够克服噪声、混响、回声等问题、较好地实现远场拾音。
同时,也需要更多远场环境下的训练数据,持续对模型进行优化,提升效果。
语音识别的过程需要经历特征提取、模型自适应、声学模型、语言模型、动态解码等多个过程。除了前面提到的远场识别问题之外,还有许多前沿研究集中在解决“鸡尾酒会问题”。
“鸡尾酒会问题”显示的是人类的一种听觉能力,能在多人场景的语音/噪声混合中,追踪并识别至少一个声音,在嘈杂环境下也不会影响正常交流。
这种能力体现在两种场景下:
- 一是人们将注意力集中在某个声音上时,比如在鸡尾酒会上与朋友交谈时,即使周围环境非常嘈杂、音量甚至超过了朋友的声音,我们也能清晰地听到朋友说的内容;
- 二是人们的听觉器官突然受到某个刺激的时候,比如远处突然有人喊了自己的名字,或者在非母语环境下突然听到母语的时候,即使声音出现在远处、音量很小,我们的耳朵也能立刻捕捉到。
而机器就缺乏这种能力,虽然当前的语音技术在识别一个人所讲的内容时能够体现出较高的精度,当说话人数为二人或更多时,识别精度就会大打折扣。
如果用技术的语言来描述,问题的本质其实是给定多人混合语音信号,一个简单的任务是如何从中分离出特定说话人的信号和其他噪音,而复杂的任务则是分离出同时说话的每个人的独立语音信号。
在这些任务上,研究者已经提出了一些方案,但还需要更多训练数据的积累、训练过程的打磨,逐渐取得突破,最终解决鸡尾酒会问题。
考虑到语义识别和对话管理环节更多是属于自然语言处理的范畴,剩下的就是语音合成环节。
语音合成的几个步骤包括:文本分析、语言学分析、音长估算、发音参数估计等。
基于现有技术合成的语音在清晰度和可懂度上已经达到了较好的水平,但机器口音还是比较明显。
目前的几个研究方向包括:如何使合成语音听起来更自然、如何使合成语音的表现力更丰富、如何实现自然流畅的多语言混合合成。只有在这些方向有所突破,才能使合成的语音真正与人类声音无异。
可以看到,在一些限制条件下,机器确实能具备一定的“听说”能力。因此在一些具体的场景下,比如语音搜索、语音翻译、机器朗读等,确实能有用武之地。
但真正做到像正常人类一样,与其他人流畅沟通、自由交流,还有待时日。
7. 计算机视觉的现在
计算机视觉的研究方向,按技术难度的从易到难、商业化程度的从高到低,依次是处理、识别检测、分析理解。
图像处理是指不涉及高层语义,仅针对底层像素的处理;图像识别检测则包含了语音信息的简单探索;图像理解则更上一层楼,包含了更丰富、更广泛、更深层次的语义探索。
目前在处理和识别检测层面,机器的表现已经可以让人满意。但在理解层面,还有许多值得研究的地方。
图像处理以大量的训练数据为基础(例如通过有噪声和无噪声的图像配对),通过深度神经网络训练一个端到端的解决方案。有几种典型任务:去噪声、去模糊、超分辨率处理、滤镜处理等。
运用到视频上,主要是对视频进行滤镜处理。这些技术目前已经相对成熟,在各类P图软件、视频处理软件中随处可见。
图像识别检测的过程包括图像预处理、图像分割、特征提取和判断匹配,也是基于深度学习的端到端方案。可以用来处理分类问题(如识别图片的内容是不是猫)、定位问题(如识别图片中的猫在哪里)、检测问题(如识别图片中有哪些动物、分别在哪
里)、分割问题(如图片中的哪些像素区域是猫)等。
这些技术也已比较成熟,图像上的应用包括人脸检测识别、OCR(Optical Character Recognition,光学字符识别)等,视频上可用来识别影片中的明星等。
当然,深度学习在这些任务中都扮演了重要角色。
传统的人脸识别算法,即使综合考虑颜色、形状、纹理等特征,也只能做到95%左右的准确率。而有了深度学习的加持,准确率可以达到99.5%,错误率下降了10倍,从而使得在金融、安防等领域的广泛商业化应用成为可能。
OCR领域,传统的识别方法要经过清晰度判断、直方图均衡、灰度化、倾斜矫正、字符切割等多项预处理工作,得到清晰且端正的字符图像,再对文字进行识别和输出。
而深度学习的出现不仅省去了复杂且耗时的预处理和后处理工作,更将字准确率从60%提高到90%以上。

图像理解本质上是图像与文本间的交互。可用来执行基于文本的图像搜索、图像描述生成、图像问答(给定图像和问题,输出答案)等。
在传统的方法下:基于文本的图像搜索是针对文本搜索最相似的文本后,返回相应的文本图像对;图像描述生成是根据从图像中识别出的物体,基于规则模板产生描述文本;图像问答是分别对图像与文本获取数字化表示,然后分类得到答案。
而有了深度学习,就可以直接在图像与文本之间建立端到端的模型,提升效果。图像理解任务目前还没有取得非常成熟的结果,商业化场景也正在探索之中。
可以看到,计算机视觉已经达到了娱乐用、工具用的初级阶段。
照片自动分类、以图搜图、图像描述生成等等这些功能,都可作为人类视觉的辅助工具。人们不再需要靠肉眼捕捉信息、大脑处理信息、进而分析理解,而是可以交由机器来捕捉、处理和分析,再将结果返回给人类。
而往未来看,计算机视觉有希望进入自主理解、甚至分析决策的高级阶段,真正赋予机器“看”的能力,从而在智能家居、无人车等应用场景发挥更大的价值。
8. 自然语言处理的现在
自然语言处理中的几个核心环节包括知识的获取与表达、自然语言理解、自然语言生成等等,也相应出现了知识图谱、对话管理、机器翻译等研究方向,与前述的处理环节形成多对多的映射关系。
由于自然语言处理要求机器具备的是比“感知”更难的“理解”能力,因此其中的许多问题直到今天也未能得到较好的解决。
知识图谱是基于语义层面对知识进行组织后得到的结构化结果,可以用来回答简单事实类的问题。
包括语言知识图谱(词义上下位、同义词等)、常识知识图谱(“鸟会飞但兔子不会飞”)、实体关系图谱(“刘德华的妻子是朱丽倩”)。
知识图谱的构建过程其实就是获取知识、表示知识、应用知识的过程。
举例来说,针对互联网上的一句文本“刘德华携妻子朱丽倩出席了电影节”,我们可以从中取出“刘德华”、“妻子”、“朱丽倩”这几个关键词,然后得到“刘德华-妻子-朱丽倩”这样的三元表示。
同样地,我们也可以得到“刘德华-身高-174cm”这样的三元表示。将不同领域不同实体的这些三元表示组织在一起,就构成了知识图谱系统。
语义理解是自然语言处理中的最大难题,这个难题的核心问题是如何从形式与意义的多对多映射中,根据当前语境找到一种最合适的映射。
以中文为例,这里面需要解决4个困难:
- 首先是歧义消除,包括词语的歧义(例如“潜水”可以指一种水下运动,也可以指在论坛中不发言)、短语的歧义(例如“进口彩电”可以指进口的彩电,也可以指一个行动动作)、句子的歧义(例如“做手术的是他父亲”可以指他父亲在接受手术,也可以指他父亲是手术医生);
- 其次是上下文关联性,包括指代消解(例如“小明欺负小李,所以我批评了他。”,需要依靠上下文才知道我批评的是调皮的小明)、省略恢复(例如“老王的儿子学习不错,比老张的好。”其实是指“比老张的儿子的学习好”);
- 第三是意图识别,包括名词与内容的意图识别(“晴天”可以指天气也可以指周杰伦的歌)、闲聊与问答的意图识别(“今天下雨了”是一句闲聊,而“今天下雨吗”则是有关天气的一次查询)、显性与隐性的意图识别(“我要买个手机”和“这手机用得太久了”都是用户想买新手机的意图);
- 最后一块是情感识别,包括显性与隐性的情感识别(“我不高兴”和“我考试没考好”都是用户在表示心情低落)、基于先验常识的情感识别(“续航时间长”是褒义的,而“等待时间长”则是贬义的)。
鉴于以上的这种种困难,语义理解可能的解决方案是利用知识进行约束,来破解多对多映射的困局,通过知识图谱来补充机器的知识。
然而,即使克服了语义理解上的困难,距离让机器显得不那么智障还是远远不够的,还需要在对话管理上有所突破。
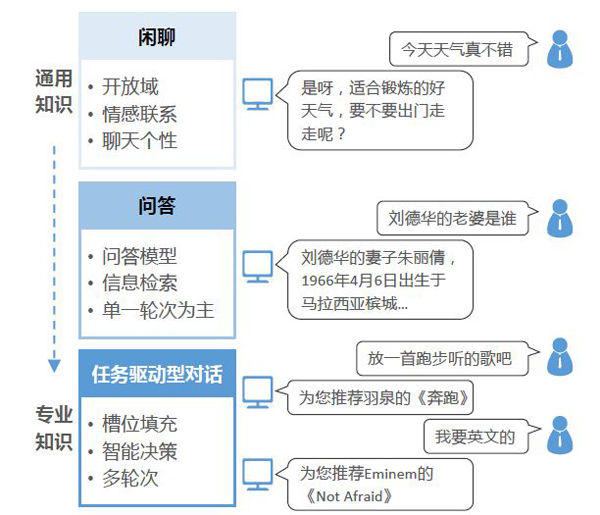
目前对话管理主要包含三种情形,按照涉及知识的通用到专业,依次是闲聊、问答、任务驱动型对话。
闲聊是开放域的、存在情感联系和聊天个性的对话,比如“ 今天天气真不错。”“是呀,要不要出去走走?”闲聊的难点在于如何通过巧妙的回答激发兴趣/降低不满,从而延长对话时间、提高粘性;
问答是基于问答模型和信息检索的对话,一般是单一轮次,比如“刘德华的老婆是谁?”“刘德华的妻子朱丽倩,1966年4月6日出生于马来西亚槟城…”。问答不仅要求有较为完善的知识图谱,还需要在没有直接答案的情况下运用推理得到答案;
任务驱动型对话涉及到槽位填充、智能决策,一般是多轮次,比如“放一首跑步听的歌吧”“为您推荐羽泉的《奔跑》”“我想听英文歌”“为您推荐Eminem的《Notafraid》”简单任务驱动型对话已经比较成熟,未来的攻克方向是如何不依赖人工的槽位定义,建立通用领域的对话管理。
历史上自然语言生成的典型应用一直是机器翻译。传统方法是一种名为Phrased-Based Machine Translation(PBMT)的方法:先将完整的一句话打散成若干个词组,对这些词组分别进行翻译,然后再按照语法规则进行调序,恢复成一句通顺的译文。
整个过程看起来并不复杂,但其中涉及到了多个自然语言处理算法,包括中文分词、词性标注、句法结构等等,环环相扣,其中任一环节出现的差错都会传导下去,影响最终结果。
而深度学习则依靠大量的训练数据,通过端到端的学习方式,直接建立源语言与目标语言之间的映射关系,跳过了中间复杂的特征选择、人工调参等步骤。
在这样的思想下,人们对早在90年代就提出了的“编码器-解码器”神经机器翻译结构进行了不断完善,并引入了注意力机制(attention mechanism),使系统性能得到显著提高。
之后谷歌团队通过强大的工程实现能力,用全新的机器翻译系统GNMT(Google Neural Machine Translation)替代了之前的SMT(Statistical machine translation),相比之前的系统更为通顺流畅,错误率也大幅下降。
虽然仍有许多问题有待解决,比如对生僻词的翻译、漏词、重复翻译等,但不可否认神经机器翻译在性能上确实取得了巨大突破,未来在出境游、商务会议、跨国交流等场景的应用前景也十分可观。
随着互联网的普及,信息的电子化程度也日益提高。海量数据既是自然语言处理在训练过程中的燃料,也为其提供了广阔的发展舞台。搜索引擎、对话机器人、机器翻译,甚至高考机器人、办公智能秘书都开始在人们的日常生活中扮演越来越重要的角色。
9. 机器学习的现在
按照人工智能的层次来看,机器学习是比计算机视觉、自然语言处理、语音处理等技术层更底层的一个概念。近几年来技术层的发展风生水起,处在算法层的机器学习也产生了几个重要的研究方向。
首先是在垂直领域的广泛应用。
鉴于机器学习还存在不少的局限、不具备通用性,在一个比较狭窄的垂直领域的应用就成为了较好的切入口。
因为在限定的领域内,一是问题空间变得足够小,模型的效果能够做到更好;二是具体场景下的训练数据更容易积累,模型训练更高效、更有针对性;三是人们对机器的期望是特定的、具体的,期望值不高。
这三点导致机器在这个限定领域内表现出足够的智能性,从而使最终的用户体验也相对更好。
因此,在金融、律政、医疗等等垂直领域,我们都看到了一些成熟应用,且已经实现了一定的商业化。可以预见,在垂直领域内的重复性劳动,未来将有很大比例会被人工智能所取代。
其次是从解决简单的凸优化问题到解决非凸优化问题。
优化问题,是指将所有的考虑因素表示为一组函数,然后从中选出一个最优解。而凸优化问题的一个很好的特性是——局部最优就是全局最优。
目前机器学习中的大部分问题,都可以通过加上一定的约束条件,转化或近似为一个凸优化问题。
虽然任何的优化问题通过遍历函数上的所有点,一定能够找到最优值,但这样的计算量十分庞大。
尤其当特征维度较多的时候,会产生维度灾难(特征数超过已知样本数可存在的特征数上限,导致分类器的性能反而退化)。而凸优化的特性,使得人们能通过梯度下降法寻找到下降的方向,找到的局部最优解就会是全局最优解。
但在现实生活中,真正符合凸优化性质的问题其实并不多,目前对凸优化问题的关注仅仅是因为这类问题更容易解决。
就像在夜晚的街道上丢了钥匙,人们会优先在灯光下寻找一样。因此,换一种说法,人们现在还缺乏针对非凸优化问题的行之有效的算法,这也是人们的努力方向。
第三点是从监督学习向非监督学习和强化学习的演进。
目前来看,大部分的AI应用都是通过监督学习,利用一组已标注的训练数据,对分类器的参数进行调整,使其达到所要求的性能。但在现实生活中,监督学习不足以被称为“智能”。
对照人类的学习过程,许多都是建立在与事物的交互中,通过人类自身的体会、领悟,得到对事物的理解,并将之应用于未来的生活中。而机器的局限就在于缺乏这些“常识”。
卷积神经网络之父、Facebook AI 研究院院长Yann LeCun曾通过一个“黑森林蛋糕”的比喻来形容他所理解的监督学习、非监督学习与强化学习间的关系:
如果将机器学习视作一个黑森林蛋糕,那(纯粹的)强化学习是蛋糕上不可或缺的樱桃,需要的样本量只有几个Bits;监督学习是蛋糕外层的糖衣,需要10到10000个Bits的样本量;无监督学习则是蛋糕的主体,需要数百万Bits的样本量,具备强大的预测能力。
但他也强调,樱桃是必须出现的配料,意味着强化学习与无监督学习是相辅相成、缺一不可的。
无监督学习领域近期的研究重点在于“生成对抗网络”(GANs),其实现方式是让生成器(Generator)和判别器(Discriminator)这两个网络互相博弈,生成器随机从训练集中选取真实数据和干扰噪音,产生新的训练样本,判别器通过与真实数据进行对比,判断数据的真实性。
在这个过程中,生成器与判别器交互学习、自动优化预测能力,从而创造最佳的预测模型。
自2014由Ian Goodfellow提出后,GANs席卷各大顶级会议,被Yann LeCun 评价为是“20年来机器学习领域最酷的想法”。
而强化学习这边,则更接近于自然界生物学习过程的本源:如果把自己想象成是环境(environment)中一个代理(agent),一方面你需要不断探索以发现新的可能性(exploration),一方面又要在现有条件下做到极致(exploitation)。
正确的决定或早或晚一定会为你带来奖励(positive reward),反之则会带来惩罚(negative reward),知道最终彻底掌握问题的答案(optimal policy)。
强化学习的一个重要研究方向在于建立一个有效的、与真实世界存在交互的仿真模拟环境,不断训练,模拟采取各种动作、接受各种反馈,以此对模型进行训练。

10. 人工智能的未来
随着技术水平的突飞猛进,人工智能终于迎来它的黄金时代。回顾人工智能六十年来的风风雨雨,历史告诉了我们这些经验:
- 首先,基础设施带来的推动作用是巨大的,人工智能屡次因数据、运算力、算法的局限而遇冷,突破的方式则是由基础设施逐层向上推动至行业应用;
- 其次,游戏AI在发展过程中扮演了重要的角色,因为游戏中牵涉到人机对抗,能帮助人们更直观地理解AI、感受到触动,从而起到推动作用;
- 最后,我们也必须清醒地意识到,虽然在许多任务上,人工智能都取得了匹敌甚至超越人类的结果,但瓶颈还是非常明显的。
比如计算机视觉方面,存在自然条件的影响(光线、遮挡等)、主体的识别判断问题(从一幅结构复杂的图片中找到关注重点);语音技术方面,存在特定场合的噪音问题(车载、家居等)、远场识别问题、长尾内容识别问题(口语化、方言等);自然语言处理方面,存在理解能力缺失、与物理世界缺少对应(“常识”的缺乏)、长尾内容识别等问题。
总的来说,我们看到,现有的人工智能技术,一是依赖大量高质量的训练数据,二是对长尾问题的处理效果不好,三是依赖于独立的、具体的应用场景、通用性很低。
而往未来看,人们对人工智能的定位绝不仅仅只是用来解决狭窄的、特定领域的某个简单具体的小任务,而是真正成为和人类一样,能同时解决不同领域、不同类型的问题,像人类一样进行判断和决策,也就是所谓的通用人工智能(Artificial General Intelligence, AGI)。
具体来说,需要机器一方面能够通过感知学习、认知学习去理解世界,另一方面通过强化学习去模拟世界。
前者让机器能感知信息,并通过注意、记忆、理解等方式将感知信息转化为抽象知识,快速学习人类积累的知识;后者通过创造一个模拟环境,让机器通过与环境交互试错来获得知识、持续优化知识。
人们希望通过算法上、学科上的交叉、融合和优化,整体解决人工智能在创造力、通用性、对物理世界理解能力上的问题。
在未来,底层的基础设施将会是由互联网、物联网提供的现代人工智能场景和数据,这些是生产的原料;
算法层将会是由深度学习、强化学习提供的现代人工智能核心模型,辅以云计算提供的核心算力,这些是生产的引擎;
在这些的基础之上,不管是计算机视觉、自然语言处理、语音技术,还是游戏AI、机器人等,都是基于同样的数据、模型、算法之上的不同的应用场景。
这其中还存在着一些亟待攻克的问题,如何解决这些问题正是人们一步一个脚印走向AGI的必经之路。
首先是从大数据到小数据。
深度学习的训练过程需要大量经过人工标注的数据,例如无人车研究需要大量标注了车、人、建筑物的街景照片,语音识别研究需要文本到语音的播报和语音到文本的听写,机器翻译需要双语的句对,围棋需要人类高手的走子记录等。
但针对大规模数据的标注工作是一件费时费力的工作,尤其对于一些长尾的场景来说,连基础数据的收集都成问题。
因此,一个研究方向就是如何在数据缺失的条件下进行训练,从无标注的数据里进行学习,或者自动模拟(生成)数据进行训练,目前特别火热的GANs就是一种数据生成模型。
其次是从大模型到小模型。
目前深度学习的模型都非常大,动辄几百兆字节(MB)、大的甚至可以到几千兆字节(GB)甚至几十千兆字节(GB)。
虽然模型在PC端运算不成问题,但如果要在移动设备上使用就会非常麻烦。这就造成语音输入法、语音翻译、图像滤镜等基于移动端的APP无法取得较好的效果。
这块的研究方向在于如何精简模型的大小,通过直接压缩或是更精巧的模型设计,通过移动终端的低功耗计算与云计算之间的结合,使得在小模型上也能跑出大模型的效果。
最后是从感知认知到理解决策。
人类智能在感知和认知的部分,比如视觉、听觉,机器在一定限定条件下已经能够做到足够好了。当然这些任务本来也不难,机器的价值在于可以比人做得更快、更准、成本更低。
但这些任务基本都是静态的,即在给定输入的情况下,输出结果是一定的。而在一些动态的任务中,比如如何下赢一盘围棋、如何开车从一个路口到另一个路口、如何在一支股票上投资并赚到钱,这类不完全信息的决策型的问题,需要持续地与环境进行交互、收集反馈、优化策略,这些也正是强化学习的强项。而模拟环境(模拟器)作为强化学习生根发芽的土壤,也是一个重要的研究方向。