













游戏在 DeepMind 公司的英国伦敦总部进行了直播
日前,谷歌(Google)旗下 DeepMind 公司开发的人工智能软件玩家在“星际争霸 II”(Starcraft II)游戏中上击败了人类玩家——这在人工智能领域尚属首例。
在 YouTube 和 Twitch 上播放的一系列游戏比赛中,AI 玩家连续 10 场击败人类玩家。在最后一场比赛中,职业游戏玩家科明茨(Grzegorz “MaNa” Komincz)为人类夺取了一场胜利。
DeepMind 公司的研究负责人大卫·西尔弗(David Silver)在比赛结束后表示:“人工智能在不同的游戏比赛中取得的成绩,成为人工智能发展的重要里程碑。我希望——尽管显然还有工作要做——未来的人们可能会回顾今天,并认识到这是人工智能系统潜在能力又迈出的重要一步。”
在电子游戏中打败人类看起来像是人工智能发展中的一场杂耍,但这其实是一个重大的研究挑战。像“星际争霸2”这样的游戏比棋类游戏(如国际象棋或围棋)更难玩。在电子游戏中,人工智能软件实体不能通过观察每一个棋子的运动来计算下一步的动作,他们必须实时作出反应。
一张去年 12 月份的游戏截图,显示了 AlphaStar 与 TLO 的对决
这些因素看起来并不是 DeepMind 人工智能游戏玩家系统(AlphaStar)的主要障碍。首先,它击败了职业玩家达里奥“TLO”Wünsch,然后它开始挑战科明茨。一系列比赛最初于去年 12 月在 DeepMind 的伦敦总部举行,但今天对科明茨的最后一场比赛提供了直播,这位职业玩家为人类带来了一场胜利。
专业的星际争霸评论员形容 AlphaStar 的表现是“非凡的”和“超人的”。
在“星际争霸 II”中,首先需要从同一张地图的不同位置开始,随后建立基地、训练军队和入侵敌人领土。AlphaStar 特别擅长所谓的“微管理”(Micromanagement),即在战场上快速果断地控制部队的能力。
尽管人类玩家有时能训练出更强大的军队,但 AlphaZero 仍能在近距离击败他们。在一场游戏中,AlphaStar 用一个快速移动的“潜行者”(Stalker)聚集了法力。评论员凯文“鹿特丹”范德科形容它实现了“非凡的军队控制,这不是一般人平时所能看到的水平。”
在游戏比赛结束之后,科明茨表示:“如果我和任何人类对手比赛,他们就不会以这么高的水平对‘潜行者’进行微操控。”
这一事件与我们从其他高级人工智能游戏玩家中看到的行为相呼应。
去年,当 OpenAI 公司的 AI 玩家参加 Dota 2 的比赛时,他们最终被人类玩家所击败。不过,当时业内专家点评指出,AI 软件玩家表现出了优秀的清晰度和准确度,能够快速无误地做出判断,这也是人工智能玩家的优势所在。
专家们已经开始剖析这一次的游戏对决,并讨论 AlphaStar 是否获得了任何不公平的优势。人工智能玩家(软件实体)在某些方面表现不佳,例如,AI 玩家每分钟进行的点击次数被限制。不过,与人类玩家不同的是,它能够一次查看整个地图,而不是手动导航。
DeepMind 公司的研究人员说,AI 玩家实际上并未获得真正的优势,因为它在任何时候只专注于地图的一个部分。但是,正如游戏过程所显示,这并没有阻止 AlphaStar 同时在三个不同的区域熟练地控制部队。评论员表示,这对人类玩家来说是不可能的。值得注意的是,当科明茨在直播的比赛中击败 AlphaStar 时,AI 正在使用一个受限的相机视图模式。
另外需要指出的是,这次和人工智能玩家对决的对手虽然是职业玩家,但并不是世界冠军水平。参加比赛的玩家 TLO 还必须完成星际争霸 II 中他所不熟悉的比赛。
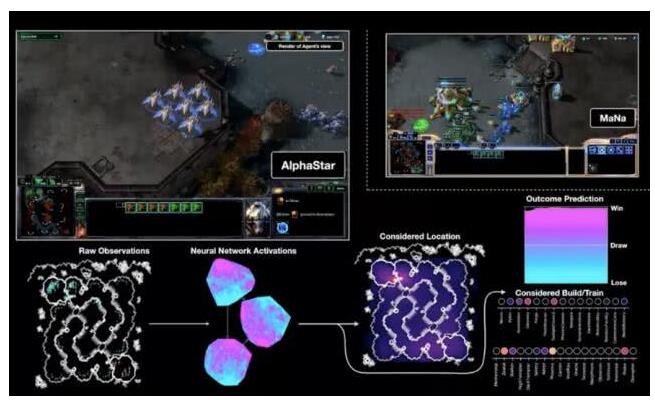
图形显示了 AlphaStar 的游戏处理过程。该系统自上而下地观察整个地图,并预测哪些行为将获得胜利
撇开这一讨论不谈,专家们说,这场比赛是人工智能向前迈出的重要一步。长期参与“星际争霸”人工智能场景研究的研究员戴夫·丘吉尔告诉英国“卫报”:“我认为人工智能游戏软件实体所表现出的能力是一项重大成就,至少比我在人工智能研究人员中听到的最乐观的猜测早一年。”
然而,丘吉尔也补充说,由于 DeepMind 还没有发布任何有关这项工作的研究论文,因此很难判断出 AlphaStar 是否获得了任何技术上的飞跃。丘吉尔说:“我还没有读过这篇博客文章,也没有看到任何文件或技术细节来做出一个判断。”
佐治亚理工学院人工智能副教授马克·里德尔(Mark Riedl)说,他对游戏比赛结果并不感到惊讶,人工智能击败人类玩家只是“一个时间问题”。
里德尔补充说,他并不认为这场比赛表明星际争霸 II 确实被人工智能玩家所征服。他表示,在过去直播的游戏中,AlphaStar 被限制在窗口中,这消除了人工智能的一些优势,“但我们看到的更大问题…是人工智能所学到的策略是脆弱的,当一个职业玩家把人工智玩家逼出舒适区时,人工智能就会崩溃。”
实际上,让人工智能玩家在电子游戏中击败人类,其最终目的是提高人工智能的训练方法,特别是创造出能够在类似星际争霸这样复杂的虚拟环境中运行的人工智能系统。
为了训练 AlphaStar,DeepMind 公司的研究人员使用了一种称为强化学习的方法。AI 软件实体为了达到某些目标(如获胜或仅仅是活着),基本上是通过反复试验来玩这个游戏的。他们首先通过模仿人类玩家来学习,然后在游戏竞技比赛中互相学习。在不同的 AI 软件实体中,强者生存,弱者被抛弃。DeepMind 估计,它的每一个 AlphaStar 软件实体都以这种方式积累了大约 200 年的游戏时间,随着游戏积累,它们玩游戏的速度也越来越快。
DeepMind 清楚地知晓其开展这项工作的目标。“最重要的是,DeepMind 的任务是构建一种通用的人工智能系统。”AlphaStar 项目的负责人奥里尔·维尼亚尔斯(Oriol Vinyals)说,他指的是建立一个能执行人类所能完成的任何心理任务的人工智能软件实体。“要做到这一点,重要的是要对我们的人工智能软件实体在各种任务中的表现进行测评对比。”



















