













同程艺龙的机票、火车票、汽车票、酒店相关业务已经接入了 RocketMQ,用于流量高峰时候的削峰,以减少后端的压力。
同时,对常规的系统进行解耦,将一些同步处理改成异步处理,每天处理的数据达 1500 亿条。
在近期的 Apache RocketMQ Meetup 上,同程艺龙机票事业部架构师查江,分享了同程艺龙的消息系统如何应对每天 1500 亿条的数据处理。
通过此文,您将了解到:
- 同程艺龙消息系统的使用情况
- 同程艺龙消息系统的应用场景
- 技术上踩过的坑
- 基于 RocketMQ 的改进
同程艺龙消息系统的使用情况
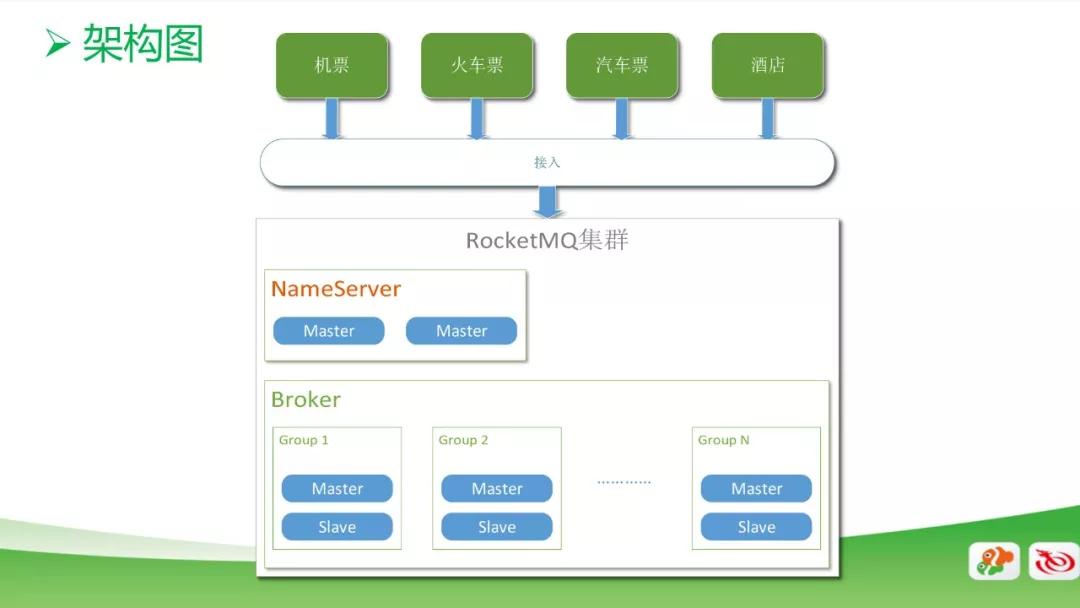
RocketMQ 集群分为 Name Server 和 Broker 两部分,Name Server 用的是双主模式,一个是考虑性能,另一个考虑安全性。在纯数据的 Broker 分成很多组,每个组里面分为 Master 和 Slave。
目前,我们的机票、火车票、汽车票、酒店相关业务已经接入了 RocketMQ,用于流量高峰时候的削峰,以减少后端的压力。
同时,对常规的系统进行解耦,将一些同步处理改成异步处理,每天处理的数据达 1500 亿条。
选择 RocketMQ 的原因是:
- 接入简单,引入的 Java 包比较少
- 纯 Java 开发,设计逻辑比较清晰
- 整体性能比较稳定的,Topic 数量大的情况下,可以保持性能
同程艺龙消息系统的应用场景
退订系统
这个是我们退订系统中的一个应用场景。用户点击前端的退订按钮,系统调用退订接口,再去调用供应商的退订接口,从而完成一个退订功能。
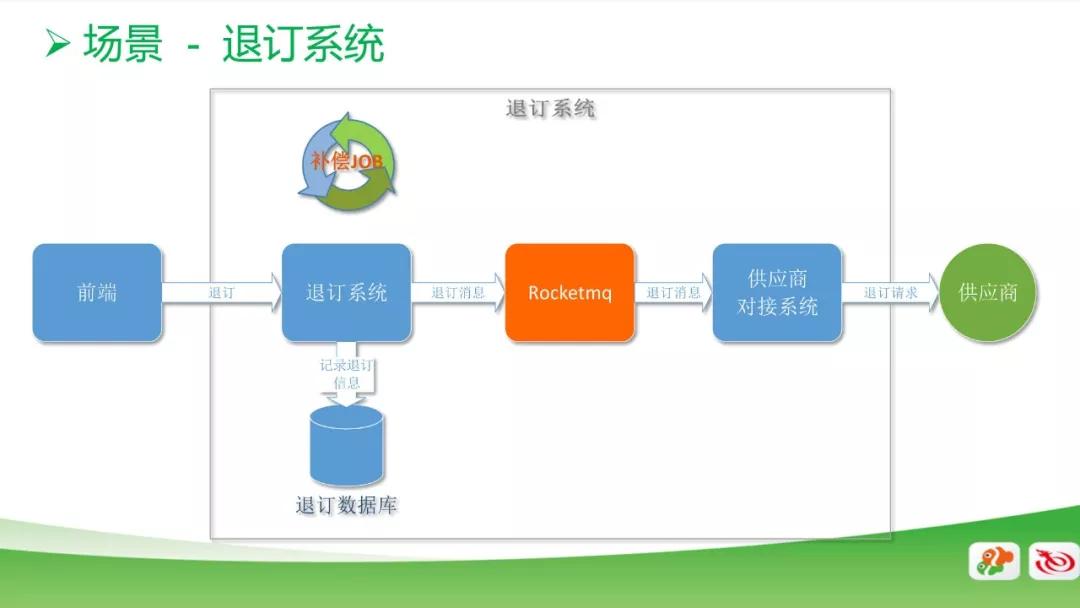
如果供应商的系统接口不可靠,就会导致用户退订失败,如果系统设置为同步操作,会导致用户需要再去点一次。
所以,我们引入 RocketMQ 将同步改为异步,当前端用户发出退订需求,退订系统接收到请求后就会记录到退订系统的数据库里面,表示这个用户正在退订。
同时通过消息引擎把这条退订消息发送到和供应商对接的系统,去调用供应商的接口。
如果调用成功,就会把数据库进行标识,表示已经退订成功。同时,加了一个补偿的脚本,去数据库捞那些未退订成功的消息,重新退订,避免消息丢失引起的退订失败的情况。
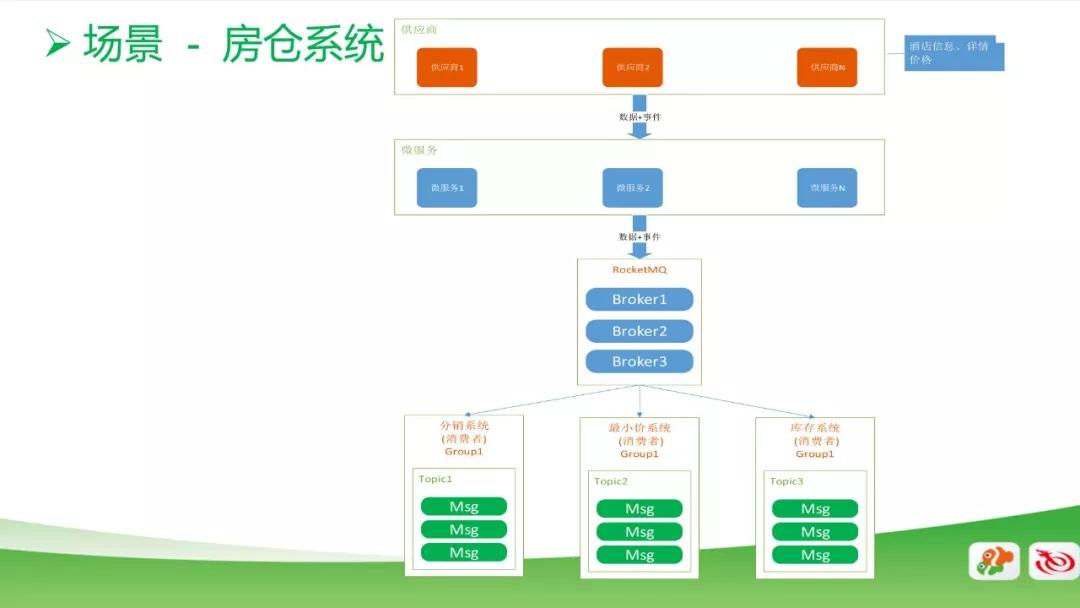
房仓系统
第二个应用场景是我们的房仓系统。这是一个比较常规的消息使用场景,我们从供应商处采集一些酒店的基本信息数据和详情数据,然后接入到消息系统,由后端的分销系统、最小价系统和库存系统来进行计算。
同时当供应商有变价的时候,变价事件也会通过消息系统传递给我们的后端业务系统,来保证数据的实时性和准确性。
供应库的订阅系统
数据库的订阅系统也用到了消息的应用。一般情况下做数据库同步,都是通过 binlog 去读里面的数据,然后搬运到数据库。
搬运过程中,我们最关注的是数据的顺序性,因此在数据库 row 模式的基础上,新增了一个功能,以确保每一个 Queue 里面的顺序是唯一的。
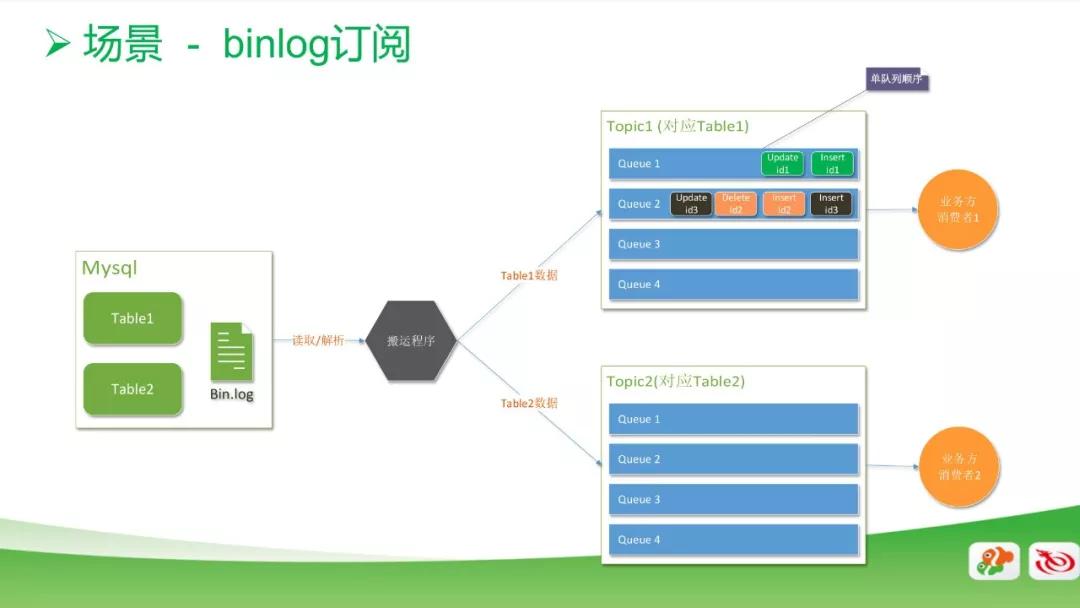
虽然 Queue 里面的顺序天然都是唯一的,但我们在使用上有一个特点,就是把相同 ID 的消息都是放在同一个 Queue 里面的。
例如,图中右上角 id1 的消息,数据库主字段是 id1,就统一放在 Queue1 里面,而且是顺序的。
在 Queue2 里,两个 id3 之间被两个顺序的 id2 间隔开来了,但实际消费读出来的时候,也会是顺序的,由此,可以用多队列的顺序来提高整体的并发度。
技术上踩过的坑
供应商系统的场景
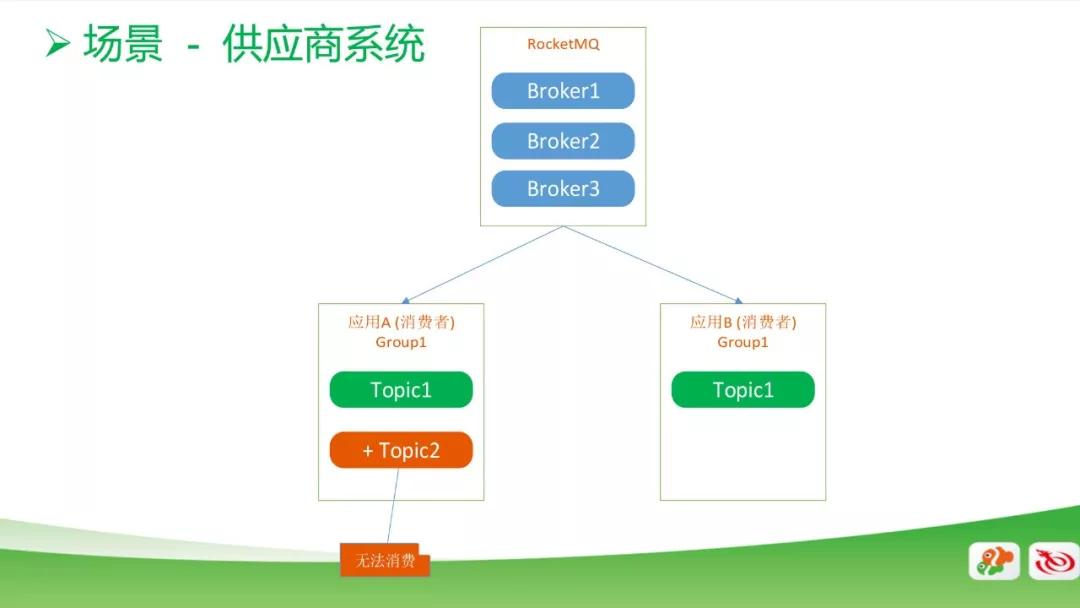
上图中,一个 MQ 对应有两个消费者,他们是在同一个 Group1 中,起初大家都只有 Topic1,这时候是正常消费的。
但如果在***个消费者里面加入一个 Topic2,这时候是无法消费或消费不正常了。
这是 RocketMQ 本身的机制引起的问题,需要在第二个消费者里面加入 Topic2 才能正常消费。
支付交易系统的场景
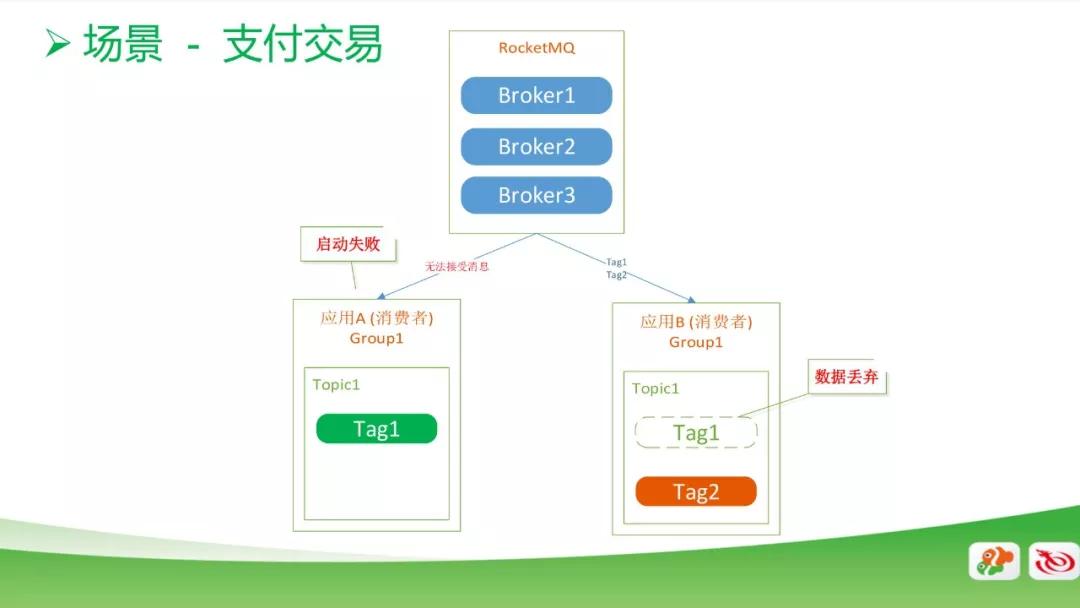
另外一个是支付交易系统,这个场景下也是有两个应用,他们都是在同一 Group 和同一 Topic 下,一个是消费 Tag1 的数据,另一个是消费 Tag2 的数据。
正常情况下,启动应该是没问题的,但是有一天我们发现一个应用起不来了,另外一个应用,他只消费 Tag2 的数据,但是因为 RocketMQ 的机制会把 Tag1 的数据拿过来,拿过来后会把 Tag1 的数据丢弃。
这会导致用户在支付过程中出现支付失败的情况。对此,我们把 Tag2 放到 Group2 里面,两个 Group 就不会消费相同的消息了。
个人建议 RocketMQ 能够实现一个机制,即只接受自己的 Tag 消息,非相关的 Tag 不去接收。
大量老数据读取的场景
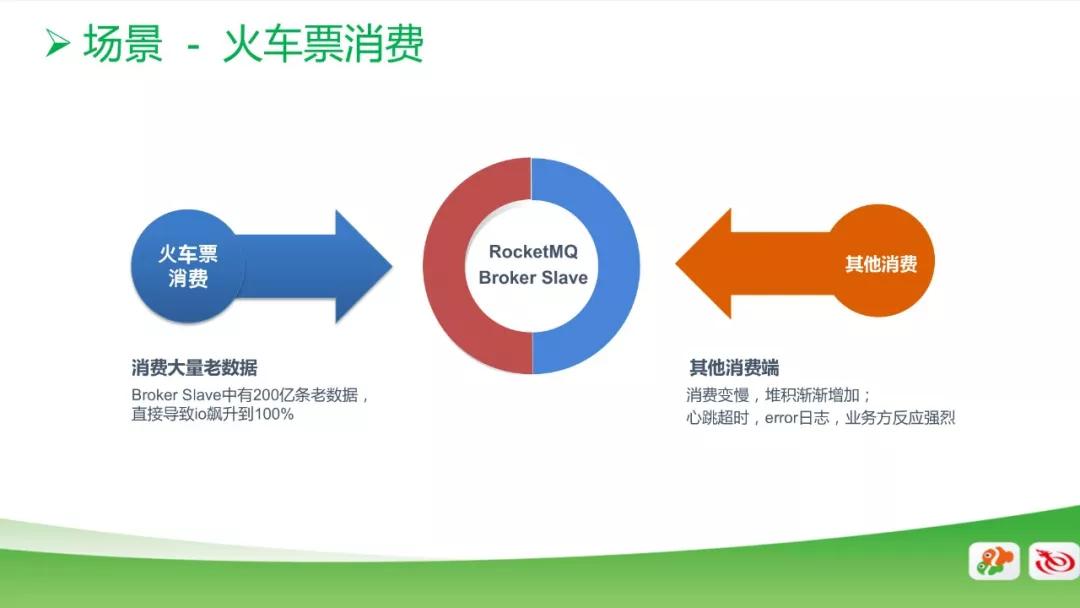
在火车票消费的场景中,我们发现有 200 亿条老数据没有被消费。当我们消费启动的时候,RocketMQ 会默认从第 0 个数据开始读,这时候磁盘 IO 飙升到 100%,从而影响到其他消费端数据的读取,但这些老数据被加载后,并没有实际作用。
因此,对于大量老数据读取的改进方式是:
- 对于新消费组,默认从 LAST_OFFSET 消费。
- Broker 中单 Topic 堆积超过 1000 万时,禁止消费,需联系管理员开启消费。
- 监控要到位,磁盘 IO 飙升时,能立刻联系到消费方处理。
服务端的场景
①CentOS 6.6 中 Futex Kernel bug, 导致 Name Server, Broker 进程经常挂起,无法正常工作
解决方法:升级到 6.7
②服务端 2 个线程会创建相同 CommitLog 放入 List,导致计算消息 offset 错误,解析消息失败,无法消费,重启没法解决问题。
解决方法:线程安全问题,改为单线程
③Pull 模式下重置消费进度,导致服务端填充大量数据到 Map 中,Broker CPU 使用率飙升 100%。
解决方法:Map 局部变量场景用不到,删除
④Master 建议客户端到 Slave 消费时,若数据还没同步到 Slave, 会重置 pullOffset,导致大量重复消费。
解决方法:不重置 offset
⑥同步没有 MagicCode,安全组扫描同步端口时,Master 解析错误,导致一些问题。
解决方法:同步时添加 magicCode 校验
基于 RocketMQ 的改进
新增客户端
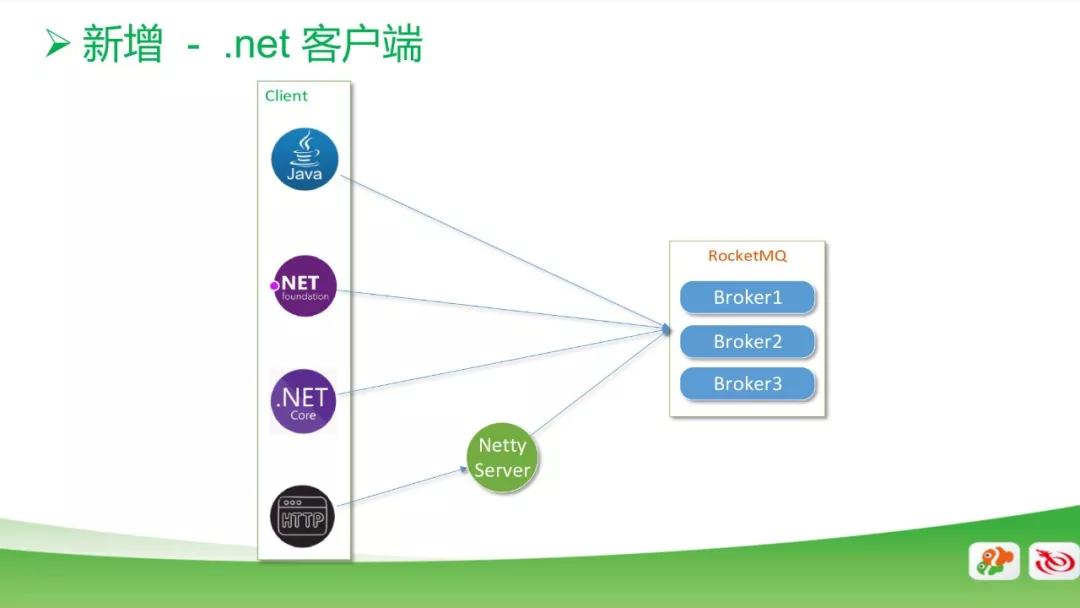
新增 .net 客户端,基于 Java 源代码原生开发;新增 HTTP 客户端,实现部分功能,并通过 Netty Server 连接 RocketMQ。
新增消息限流功能
如果客户端代码写错产生死循环,就会产生大量的重复数据,这时候会把生产线程打满,导致队列溢出,严重影响我们 MQ 集群的稳定性,从而影响其他业务。
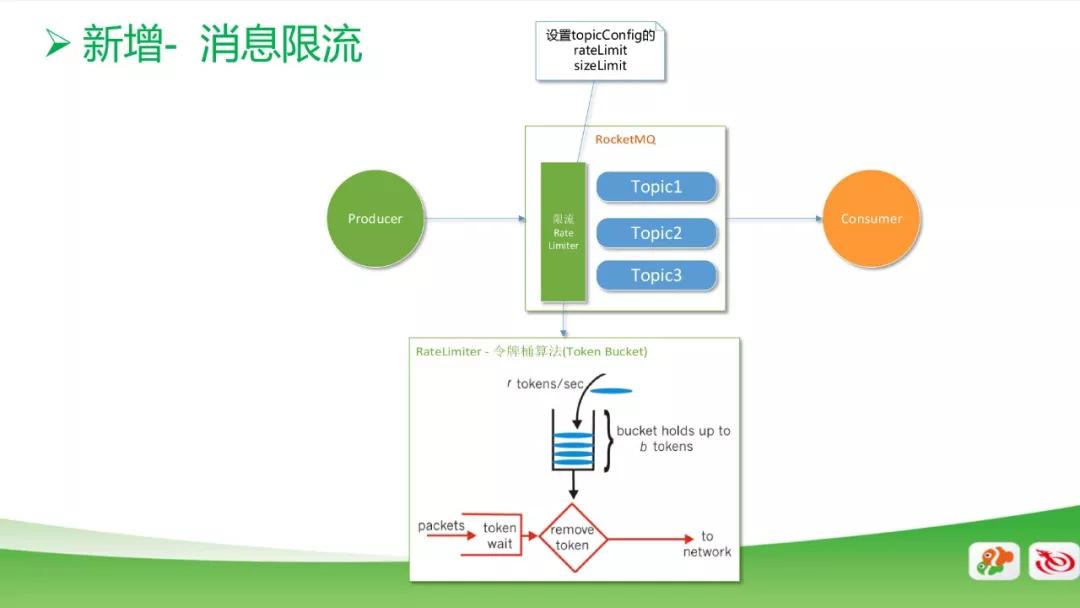
上图是限流的模型图,我们把限流功能加在 Topic 之前。通过限流功能可以设置 rate limit 和 size limit 等。
其中 rate limit 是通过令牌桶算法来实现的,即每秒往桶里放多少个令牌,每秒就消费多少速度,或者是往 Topic 里写多少数据。以上的两个配置是支持动态修改的。
后台监控
我们还做了一个监控后台,用于监控消息的全链路过程,包括:
- 消息全链路追踪,覆盖消息产生、消费、过期整个生命周期
- 消息生产、消费曲线
- 消息生产异常报警
- 消息堆积报警,通知哪个 IP 消费过慢
其他功能:
- HTTP 方式生产,消费消息
- Topic 消费权限设置,Topic 只能被指定 Group 消费,防止线上错乱订阅
- 支持新消费组从***位置消费 (默认是从***条开始消费)
- 广播模式消费进度同步 (服务端显示进度)
以上便是同程艺龙在消息系统建设方面的实践。




















